前言:先自己尝试去回答,回答不了再看参考答案,你才能学的更多!
1.MVC具有什么样的优势,各个模块之间怎么通信,比如点击 Button 后 怎么通知 Model?
2.两个无限长度链表(也就是可能有环) 判断有没有交点
3.UITableView的相关优化
4.KVO、Notification、delegate各自的优缺点,效率还有使用场景
5.如何手动通知KVO
6.Objective-C 中的copy方法
7.runtime 中,SEL和IMP的区别
8.autoreleasepool的使用场景和原理
9.RunLoop的实现原理和数据结构,什么时候会用到
10.block为什么会有循环引用
11.有没有自己设计过网络控件? 12.NSOperation和GCD的区别
13.CoreData的使用,如何处理多线程问题
14.如何设计图片缓存?
15.有没有自己设计过网络控件?
1.MVC 具有什么样的优势,各个模块之间怎么通信,比如点击 Button 后 怎么通知 Model?
MVC 是一种设计思想,一种框架模式,是一种把应用中所有类组织起来的策略,它把你的程序分为三块,分别是:
M(Model):实际上考虑的是“什么”问题,你的程序本质上是什么,独立于 UI 工作。是程序中用于处理应用程序逻辑的部分,通常负责存取数据。
C(Controller):控制你 Model 如何呈现在屏幕上,当它需要数据的时候就告诉 Model,你帮我获取某某数据;当它需要 UI 展示和更新的时候就告诉 View,你帮我生成一个 UI 显示某某数据,是 Model 和 View 沟通的桥梁。
V(View):Controller 的手下,是 Controller 要使用的类,用于构建视图,通常是根据 Model 来创建视图的。
要了解 MVC 如何工作,首先需要了解这三个模块间如何通信。
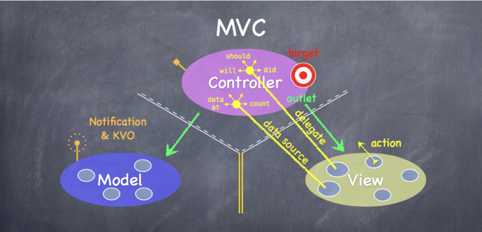
MVC通信规则
Controller to Model
可以直接单向通信。Controller 需要将 Model 呈现给用户,因此需要知道模型的一切,还需要有同 Model 完全通信的能力,并且能任意使用 Model 的公共 API。
Controller to View
可以直接单向通信。Controller 通过 View 来布局用户界面。
Model to View
永远不要直接通信。Model 是独立于 UI 的,并不需要和 View 直接通信,View 通过 Controller 获取 Model 数据。
View to Controller
View 不能对 Controller 知道的太多,因此要通过间接的方式通信。
Target action。首先 Controller 会给自己留一个 target,再把配套的 action 交给 View 作为联系方式。那么 View 接收到某些变化时,View 就会发送 action 给 target 从而达到通知的目的。这里 View 只需要发送 action,并不需要知道 Controller 如何去执行方法。
代理。有时候 View 没有足够的逻辑去判断用户操作是否符合规范,他会把判断这些问题的权力委托给其他对象,他只需获得答案就行了,并不会管是谁给的答案。
DataSoure。View 没有拥有他们所显示数据的权力,View 只能向 Controller 请求数据进行显示,Controller 则获取 Model 的数据整理排版后提供给 View。
Model 访问 Controller
同样的 Model 是独立于 UI 存在的,因此无法直接与 Controller 通信,但是当 Model 本身信息发生了改变的时候,会通过下面的方式进行间接通信。
Notification & KVO一种类似电台的方法,Model 信息改变时会广播消息给感兴趣的人 ,只要 Controller 接收到了这个广播的时候就会主动联系 Model,获取新的数据并提供给 View。
从上面的简单介绍中我们来简单概括一下 MVC 模式的优点。
1.低耦合性
2.有利于开发分工
3.有利于组件重用
4.可维护性
2.两个无限长度链表(也就是可能有环) 判断有没有交点?
单链表是否存在环?环的入口是什么?
是否存在环
1) 判断是否存在环:设置快慢指针fast和slow,fast步速为2,slow为1,若最终fast==slow,那么就证明单链表中一定有环。如果没有环的话,fast一定先到达尾节点
2) 简单证明:利用相对运动的概念,以slow为参考点(静止不动),那么fast的步速实际为1,当fast超过slow之后,fast以每步一个节点的速度追赶slow,如果链表有环的话,fast一定会追赶到slow,即fast==slow。
如何找到环的入口
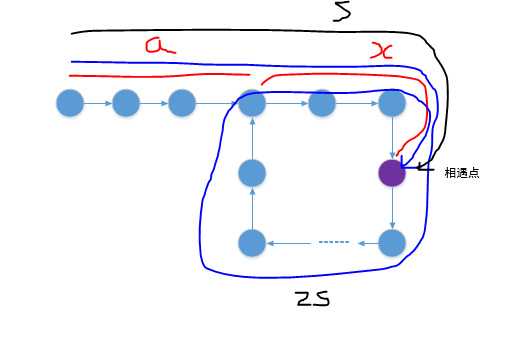
第一次相遇
字母代表的量:
- a:链表头结点到环入口的距离
- r:环长
- 蓝色线:fast指针所走的距离2s
- 黑色线:slow指针所走的距离s
假设链表总长度为L,且fast与slow相遇时fast已经绕环走了n圈,则有如下关系:
2s = s + nr
将s移到左边得:
s = nr
转换:
s = (n-1)r + r = (n-1)r + L-a
a+x = (n-1)r + L-a
得:
a = (n-1)r + L-a-x
由图可知,(L-a-x)为相遇点到环入口点的距离。由上式可知:
从链表头到环入口的距离 = (n-1)圈内环循环 + 相遇点到环入口点的距离
将r视为周期的话,a与L-a-x在某种意义上是相等的(实际并不一定相等)。
那么由此我们便找到了突破点,为了找到环的入口点,在fast与slow相遇时,将slow指针重新指向单链表的头节点,fast仍然留在相遇点,只不过步速降为与slow相同的1,每次循环只经过一个节点,如此,当fast与slow再次相遇时,那个新的相遇点便是我们苦苦寻找的入口点了。
如何知道环的长度
纪录下相遇点,让slow与fast从该点开始,再次碰撞所走过的操作数就是环的长度r。
带环的链表的长度是多少?
通过以上分析我们已经知道了如何求环入口,环长,那么链表长度显然就是两者之和,即:
L = a + r
判断两个链表是否相交
分析问题之前我们要搞清楚链表相交的一些基本概念
- 明确概念:两个单向链表相交,只能是y型相交,不可能是x型相交。
- 分析:有两个链表,La,Lb,设他们的交点设为p,假设在La中,p的前驱为pre_a,后继为next_a,在Lb中,前驱为pre_b,后继为next_b,则
pre_a->next=p,pre_b->next=p,接下来看后继,p->next=next_a,p->next=next_b;那么问题就出来了,一个单链表的next指针只有一个,
怎么跑出两个来呢,所以必有next_a==next_b,于是我们得出两个链表相交只能是Y型相交。明确了这个概念,我们再来堆相交问题进行分析。
情况一:两个链表都无环
1) 问题简化。将链表B接到链表A的后面,如果A、B有交点,则构成一个有环的单链表,而我们刚刚在上面已经讨论了如何判断一个
单链表是否有环。
2) 若两个链表相交则必为Y型,由此可知两个链表从相交点到尾节点是相同的,我们并不知道他们的相交点位置,但是我们可以遍历得出A、B链表的
尾节点,如此,比较他们的尾节点是否相等便可以求证A、B是否相交了。
情况二:链表有环
1) 其中一个链表有环,另外一个链表无环。则两个链表不可能相交。(啥?你不知道为啥?自己看看前面的“明确概念”反省吧)
2) 那么有环相交的情况只有当两个链表都有环时才会出现,如果两个有环链表相交,则他们拥有共通的环,即环上任意一个节点都存在于
两个链表上。因此,通过判断A链表上的快慢指针相遇点是否也在B链表上便可以得出两个链表是否相交了。
求相交链表的相交点
题目描述:如果两个无环单向链表相交,怎么求出他们相交的第一个节点呢?
分析:采用对齐的思想。计算两个链表的长度 L1 , L2,分别用两个指针 p1 , p2 指向两个链表的头,然后将较长链表的 p1(假设为 p1)向后移动L2 - L1个节点,然后再同时向后移动p1 , p2,直到 p1 = p2。相遇的点就是相交的第一个节点。
3.UITableView 的相关优化
前言
1.这篇文章对 UITableView 的优化主要从以下3个方面分析:
?基础的优化准则(高度缓存, cell 重用...)
?学会使用调试工具分析问题
?异步绘制
2.涉及到 tableView 请一定要 用真机调试!用真机调试!用真机调试!
手机的性能比起电脑还是差别很大,不要老想着用模拟器调试。一定要用真机才能看出效果。
3.不要过早的做复杂的优化
虽然这篇文章讲的是如何优化table,但是根据我的经验,不要一开始就去做这些工作(基本的优化除外),因为不管怎么说,PM不会闲着的,产品的变动并不是由开发人员控制。但是大的优化对代码的结构还是有很大影响的,这意味着过早优化可能会拖慢工程的进度。在项目初期能用 xib 就用吧,本来大部分这样的文章都是不推荐使用 IB 的东西,但是不得不说,在效率上 IB 实在是有了很多天然的优势。
4.优化总是在 空间 和 时间 之间权衡
一般优化的后期总是以更多的空间换取更短时间的响应。这表示可能会增加额外的内存和CPU资源的开销,需要缓存高度,缓存布局...,当然也可能有别的考量以时间换取空间。具体怎么做,还得根据项目相关的业务逻辑确定。其实我想表达的是目前并没有十全十美的方案既可以节省内存,又可以加快速度,如果非要说好的话,也只能是在资源调度上下了功夫(如果你知道更好的请告诉我,谢谢)。如果你追求的是非常完美,还是不要朝下看了。
基础的优化准则
1.正确地使用UITableViewCell的重用机制
UITableView最核心的思想就是 UITableViewCell 的重用机制。UITableView 只会创建一屏幕(或一屏幕多一点)的 UITableViewCell ,每当 cell 滑出屏幕范围时,就会放入到一重用池当中,当要显示新的 cell 时,先去重用池中取,若没有可用的,才会重新创建。这样可以极大的减少内存的开销。
比较早的一种写法
static NSString *cellID = @"Cell";
2. UITableViewCell *cell = [tableView dequeueReusableCellWithIdentifier:cellID];
3. if (!cell) {
4. cell = [[UITableViewCell alloc] initWithStyle:UITableViewCellStyleDefault reuseIdentifier:cellID];
5. //cell 初始化
6. }
7. // cell 设置数据
8. return cell;
或者通过注册cell的方式
//注册cell
9.[tableView registerClass:[UITableViewCell class] forCellReuseIdentifier:@"cell"];
10.//获取cell
11.UITableViewCell *cell = [tableView dequeueReusableCellWithIdentifier:@"cell"];
12.提前计算好 cell 的高度和布局。
UITableView有两个重要的回调方法:
- (UITableViewCell *)tableView:(UITableView *)tableView cellForRowAtIndexPath:(NSIndexPath *)indexPath;
13.
14.- (CGFloat)tableView:(UITableView *)tableView heightForRowAtIndexPath:(NSIndexPath *)indexPath;
UITableView的回调顺序是先多次调用tableView:heightForRowAtIndexPath: 用来确定 contentSize 及 Cell 的位置,然后才会调用 tableView:cellForRowAtIndexPath:,从而来显示在当前屏幕的 cell 。
ios8会更厉害,还会边滑动边调用 tableView:heightForRowAtIndexPath: ,可见这个方法里一定不能重复进行着大量的计算。我们应该提前计算好 cell 的高度并且缓存起来,在回调时直接把高度值直接返回。
这里说一种我经常采用的策略:
一般在网络请求结束后,在更新界面之前就把每个 cell 的高度算好,缓存到相对应的 model 中。
这里可能有人说要是一个 model 对应多种 cell 怎么办?
model 可以添加多个高度属性啊,这点空间上的开销还是可以接受的吧。
当然这个时候最好把布局也都算好了最好,下面的YY的做法会介绍。
15.避免阻塞主线程。
很多时候我们需要从网络请求图片等,把这些操作放在后台执行,并且缓存起来。现在我们大都使用 SDWebImage 进行网络图片处理,正常的使用是没有大问题的,但是如果对性能要求比较高,或者要处理gif图,我还是推荐 YYWebImage,详细内容请自行移步到github查看,当然这只是个人建议。
还有就是不要在主线程做一些文件的I/O操作。
16.按需加载。
这一条真的是看各位喜好了,我是觉得滚动的过程中有大量的 “留白” 并不太好,不过作为优化的建议还是要考虑的。
如快速滚动时,仅绘制目标位置的 cell ,可以提高滚动的顺畅程度。
具体可以参考 VVebo 。
17.减少SubViews的数量。
总觉得这条有点多余,能简单点的我们肯定不会做复杂了吧。这更多的取决于UI界面的复杂度。
18.尽可能重用开销比较大的对象。
如NSDateFormatter 和 NSCalendar等对象初始化非常慢,我们可以把它加入类的属性当中,或者创建单例来使用。
19.尽量减少计算的复杂度
在高分屏尽量用 ceil 或 floor 或 round 取整。不要出现 1.7,10.007这样的小数。
20.不要动态的add 或者 remove 子控件
最好在初始化时就添加完,然后通过hidden来控制是否显示。
学会使用调试工具分析问题
Instruments里的:
?Core Animation instrument
?OpenGL ES Driver instrument
模拟器中的:
?Color debug options View debugging
Xcode的:
?View debugging
Xcode 已经集成了 Instruments 工具,通过菜单 profile 即可打开。
在模拟器中你可以在 Debug 中找到如下的菜单:
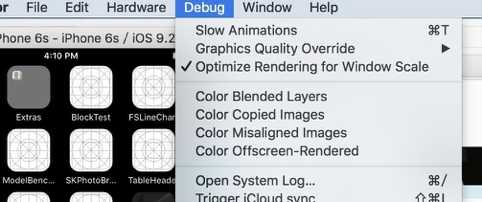
D5806B24-BB86-449D-81C2-82DA247E053C.png
下面是一些常见的调试选项的含义:
1. Color Blended Layers
Instruments可以在物理机上显示出被混合的图层Blended Layer(用红色标注),
Blended Layer是因为这些Layer是透明的(Transparent),
系统在渲染这些view时需要将该view和下层view混合(Blend)后才能计算出该像素点的实际颜色。
解决办法:检查红色区域view的opaque属性,记得设置成YES;检查backgroundColor属性是不是[UIColor clearColor]
2. Color Copied Images
这个选项主要检查我们有无使用不正确图片格式,若是GPU不支持的色彩格式的图片则会标记为青色,
则只能由CPU来进行处理。我们不希望在滚动视图的时候,CPU实时来进行处理,因为有可能会阻塞主线程。
解决办法:检查图片格式,推荐使用png。
3. Color Misaligned Images
这个选项检查了图片是否被放缩,像素是否对齐。
被放缩的图片会被标记为黄色,像素不对齐则会标注为紫色。
如果不对齐此时系统需要对相邻的像素点做anti-aliasing反锯齿计算,会增加图形负担
通常这种问题出在对某些View的Frame重新计算和设置时产生的。
解决办法:参考 基本优化准则的第7点
4. Color Offscreen-Rendered
这个选项将需要offscreen渲染的的layer标记为黄色。
离屏渲染意思是iOS要显示一个视图时,需要先在后台用CPU计算出视图的Bitmap,
再交给GPU做Onscreen-Rendering显示在屏幕上,因为显示一个视图需要两次计算,
所以这种Offscreen-Rendering会导致app的图形性能下降。
大部分Offscreen-Rendering都是和视图Layer的Shadow和Mask相关。
下列情况会导致视图的Offscreen-Rendering:
- 使用Core Graphics (CG开头的类)。
- 使用drawRect()方法,即使为空。
- 将CALayer的属性shouldRasterize设置为YES。
- 使用了CALayer的setMasksToBounds(masks)和setShadow*(shadow)方法。
- 在屏幕上直接显示文字,包括Core Text。
- 设置UIViewGroupOpacity。
解决办法:只能减少各种 layer 的特殊效果了。
这篇博文 Designing for iOS: Graphics & Performance 对offsreen以及图形性能有个很棒的介绍,
异步绘制
这个属于稍高级点的技能。
如果我们使用 Autolayout 可能就无能为力了。这也是为什么那么多人在优化这块拒绝使用 IB 开发。
但是这里并不展示具体的绘制代码。给个简单的形式参考:
//异步绘制
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{
CGRect rect = CGRectMake(0, 0, 100, 100);
UIGraphicsBeginImageContextWithOptions(rect.size, YES, 0);
CGContextRef context = UIGraphicsGetCurrentContext();
[[UIColor lightGrayColor] set];
CGContextFillRect(context, rect);
//将绘制的内容以图片的形式返回,并调主线程显示
UIImage *temp = UIGraphicsGetImageFromCurrentImageContext();
UIGraphicsEndImageContext();
// 回到主线程
dispatch_async(dispatch_get_main_queue(), ^{
//code
});
});
另外绘制 cell 不建议使用 UIView,建议使用 CALayer。
从形式来说:UIView 的绘制是建立在 CoreGraphic 上的,使用的是 CPU。CALayer 使用的是 Core Animation,CPU,GPU 通吃,由系统决定使用哪个。View的绘制使用的是自下向上的一层一层的绘制,然后渲染。Layer处理的是 Texure,利用 GPU 的 Texture Cache 和独立的浮点数计算单元加速 纹理 的处理。
从事件的响应来说:UIView是 CALayer 的代理,layer本身并不能响应事件,因为layer是直接继承自NSObject,不具备处理事件的能力。而 UIView 是继承了UIResponder 的,这也是事件转发的角度上说明,view要比单纯的layer复杂的多。在滑动的列表上,多层次的view再加上各种手势的处理势必导致帧数的下降。
在这一块还有个问题就是当 TableView 快速滑动时,会有大量异步绘制任务提交到后台线程去执行。线程并不是越多越好,太多了只会增加 CPU 的负担。所以我们需要在适当的时候取消掉不重要的线程。
目前这里有两种做法:
YY的做法是:
尽量快速、提前判断当前绘制任务是否已经被取消;在绘制每一行文本前,都会调用 isCancelled() 来进行判断,保证被取消的任务能及时退出,不至于影响后续操作。
VVebo的做法是:
当滑动时,松开手指后,立刻计算出滑动停止时 Cell 的位置,并预先绘制那个位置附近的几个 Cell,而忽略当前滑动中的 Cell。忽略的代价就是快速滑动中会出现大量空白内容。
两者都是不错的优化方法,各位自行取舍。
番外
?YYText 的使用
这个框架涉及到的方面还是很多的,在这里说再多的理论还是不如自己去看代码的好。
关于用法,没什么比YY作者说的更明白的了:
当获取到 API JSON 数据后,我会把每条 Cell 需要的数据都在后台线程计算并封装为一个布局对象 CellLayout。CellLayout 包含所有文本的 CoreText 排版结果、Cell 内部每个控件的高度、Cell 的整体高度。每个 CellLayout 的内存占用并不多,所以当生成后,可以全部缓存到内存,以供稍后使用。这样,TableView 在请求各个高度函数时,不会消耗任何多余计算量;当把 CellLayout 设置到 Cell 内部时,Cell 内部也不用再计算布局了。
对于通常的 TableView 来说,提前在后台计算好布局结果是非常重要的一个性能优化点。为了达到最高性能,你可能需要牺牲一些开发速度,不要用 Autolayout 等技术,少用 UILabel 等文本控件。但如果你对性能的要求并不那么高,可以尝试用 TableView 的预估高度的功能,并把每个 Cell 高度缓存下来。这里有个来自百度知道团队的开源项目可以很方便的帮你实现这一点:FDTemplateLayoutCell。
一开始我是想要在这里长篇大论的,不过后来想想千言万语还是不及一个 Demo (还没做完)。
?AsyncDisplayKit 的使用
这个框架是 facebook 团队开源的,它的使用代价有点大,因为它已经不是按照我们正常的UIKit框架来写了。由于这个框架就是建立在各种 Display Node 上的,所以要使用该框架,那么就需要使用 Display Node 层次结构替换视图层次结构和/或 Layer 树。但是这个框架还是值得尝试的,因为 AsyncDisplayKit 支持在非主线程执行之前只能在主线程才能执行的任务。这就能减轻主线程的工作量以执行其他操作,例如处理触摸事件,滑动事件。
下面附一篇 AsyncDisplayKit教程
当然,不管是 YYText 还是 AsyncDisplayKit,他们都有非常流畅的体验,对于复杂的列表来说都是神器。用好其中一种都可以解决大部分问题了,那么还有一部分问题来自于哪里呢?继续向下看。
应该是使用最为广泛的图片库了吧。上面也提到了,我们正常的使用是没有大问题的,但是如果对性能要求比较高,或者要处理gif图,SD 难免会拖慢速度。特别是 gif 的内存暴增问题,SD 一直没有一个较好的解决方案。
这个就是在列表优化时我推荐使用的网络图片库,在对性能要求比较高的情况下,YY 可以直接以 layer 作为图片的载体这样减少了相当的一部分资源消耗。具体在什么情况下使用layer 什么情况下使用 imageView 戳这里 。
小结
?如果项目比较紧,我更推荐 IB + 基础的优化准则,既可以保证整体效率也不至于卡的太严重。
?如果项目已经到后期,并且有时间进行大量的优化。我倾向于使用 纯代码 + 异步绘制,这一部分在苹果现在的多种屏幕尺寸上适配工作量并不小。但是效果却也是很明显的。
?如果想获得流畅的体验,但是有没有太多的时间去做优化,那就可以使用一些封装好的第三方库,比如 YYText,AsyncDisplayKit 。
4.KVO、Notification、delegate 各自的优缺点,效率还有使用场景
在开发ios应用的时候,我们会经常遇到一个常见的问题:在不过分耦合的前提下,controllers间怎么进行通信。在IOS应用不断的出现三种模式来实现这种通信:
1.委托delegation;
2.通知中心Notification Center;
3.键值观察key value observing,KVO
delegate的优势:
1.很严格的语法,所有能响应的时间必须在协议中有清晰的定义
2.因为有严格的语法,所以编译器能帮你检查是否实现了所有应该实现的方法,不容易遗忘和出错
3.使用delegate的时候,逻辑很清楚,控制流程可跟踪和识别
4.在一个controller中可以定义多个协议,每个协议有不同的delegate
5.没有第三方要求保持/监视通信过程,所以假如出了问题,那我们可以比较方便的定位错误代码。
6.能够接受调用的协议方法的返回值,意味着delegate能够提供反馈信息给controller
delegate的缺点:
需要写的代码比较多
有一个“Notification Center”的概念,他是一个单例对象,允许当事件发生的时候通知一些对象,满足控制器与一个任意的对象进行通信的目的,这种模式的基本特征就是接收到在该controller中发生某种事件而产生的消息,controller用一个key(通知名称),这样对于controller是匿名的,其他的使用同样地key来注册了该通知的对象能对通知的事件作出反应。
notification的优势:
1.不需要写多少代码,实现比较简单
2.一个对象发出的通知,多个对象能进行反应,一对多的方式实现很简单
缺点:
1.编译期不会接茬通知是否能被正确处理
2.释放注册的对象时候,需要在通知中心取消注册
3.调试的时候,程序的工作以及控制流程难跟踪
4.需要第三方来管理controller和观察者的联系
5.controller和观察者需要提前知道通知名称、UserInfo dictionary keys。如果这些没有在工作区间定义,那么会出现不同步的情况
6.通知发出后,发出通知的对象不能从观察者获得任何反馈。
KVO
KVO是一个对象能观察另一个对象属性的值,前两种模式更适合一个controller和其他的对象进行通信,而KVO适合任何对象监听另一个对象的改变,这是一个对象与另外一个对象保持同步的一种方法。KVO只能对属性做出反应,不会用来对方法或者动作做出反应。
优点:
1.提供一个简单地方法来实现两个对象的同步
2.能对非我们创建的对象做出反应
3.能够提供观察的属性的最新值和先前值
4.用keypaths 来观察属性,因此也可以观察嵌套对象
缺点:
1.观察的属性必须使用string来定义,因此编译器不会出现警告和检查
2.对属性的重构将导致观察不可用
3.复杂的“if”语句要求对象正在观察多个值,这是因为所有的观察都通过一个方法来指向
KVO有显著的使用场景,当你希望监视一个属性的时候,我们选用KVO
而notification和delegate有比较相似的用处,
当处理属性层的消息的事件时候,使用KVO,其他的尽量使用delegate,除非代码需要处理的东西确实很简单,那么用通知很方便
5.如何手动通知 KVO
重写Controller里面某个属性的setter方法,联动给View赋值,使用Controller监控Model里面某个值的变化,在controller的dealloc函数中用一行代码了结:removeObserver。
6.Objective-C 中的copy方法
对象的复制就是复制一个对象作为副本,他会开辟一块新的内存(堆内存)来存储副本对象,就像复制文件一样,即源对象和副本对象是两块不同的内存区域。对象要具备复制功能,必须实现<NSCopying>协议或者<NSMutableCopying>协议,常用的可复制对象有:NSNumber、NSString、NSMutableString、NSArray、NSMutableArray、NSDictionary、NSMutableDictionary
copy:产生对象的副本是不可变的
mutableCopy:产生的对象的副本是可变的
浅拷贝和深拷贝
浅拷贝值复制对象本身,对象里的属性、包含的对象不做复制
深拷贝则既复制对象本身,对象的属性也会复制一份
Foundation中支持复制的类,默认是浅复制
对象的自定义拷贝
对象拥有复制特性,须实现NSCopying,NSMutableCopying协议,实现该协议的CopyWithZone:方法或MutableCopyWithZone:方法。
浅拷贝实现
[cpp] view plain copy
- -(id)copyWithZone:(NSZone *)zone{
- Person *person = [[[self Class]allocWithZone:zone]init];
- p.name = _name;
- p.age = _age;
- return person;
- }
深拷贝的实现
[cpp] view plain copy
- -(void)copyWithZone:(NSZone *)zone{
- Person *person = [[[self Class]allocWithZone:zone]init];
- person.name = [_name copy];
- person.age = [_age copy];
- return person;
- }
深浅拷贝和retain之间的关系
copy、mutableCopy和retain之间的关系
Foundation中可复制的对象,当我们copy的是一个不可变的对象的时候,它的作用相当与retain(cocoa做的内存优化)
当我们使用mutableCopy的时候,无论源对象是否可变,副本是可变的
当我们copy的 是一个可变对象时,复本不可变
7.runtime 中,SEL 和 IMP 的区别
方法名 SEL – 表示该方法的名称;
一个 types – 表示该方法参数的类型;
一个IMP – 指向该方法的具体实现的函数指针,说白了IMP就是实现方法。
8.autoreleasepool 的使用场景和原理
Autorelease Pool全名叫做NSAutoreleasePool,是OC中的一个类。autorelease pool并不是天生就有的,你需要手动的去创建它。一般地,在新建一个iphone项目的时候,xcode会自动地为你创建一个Autorelease Pool,这个pool就写在Main函数里面。在NSAutoreleasePool中包含了一个可变数组,用来存储被声明为autorelease的对象。当NSAutoreleasePool自身被销毁的时候,它会遍历这个数组,release数组中的每一个成员(注意,这里只是release,并没有直接销毁对象)。若成员的retain count 大于1,那么对象没有被销毁,造成内存泄露。默认的NSAutoreleasePool 只有一个,你可以在你的程序中创建NSAutoreleasePool,被标记为autorelease的对象会跟最近的NSAutoreleasePool匹配。可以嵌套使用NSAutoreleasePool。
Objective-C Autorelease Pool 的实现原理
内存管理一直是学习 Objective-C 的重点和难点之一,尽管现在已经是 ARC 时代了,但是了解 Objective-C 的内存管理机制仍然是十分必要的。其中,弄清楚 autorelease 的原理更是重中之重,只有理解了 autorelease 的原理,我们才算是真正了解了 Objective-C 的内存管理机制。注:本文使用的 runtime 源码是当前的最新版本 objc4-646.tar.gz 。
autoreleased 对象什么时候释放
autorelease 本质上就是延迟调用 release ,那 autoreleased 对象究竟会在什么时候释放呢?为了弄清楚这个问题,我们先来做一个小实验。这个小实验分 3 种场景进行,请你先自行思考在每种场景下的 console 输出,以加深理解。注:本实验的源码可以在这里 AutoreleasePool 找到。
特别说明:在苹果一些新的硬件设备上,本实验的结果已经不再成立,详细情况如下:
- iPad 2
- iPad Air
- iPad Air 2
- iPad Pro
- iPad Retina
- iPhone 4s
- iPhone 5
- iPhone 5s
- iPhone 6
- iPhone 6 Plus
- iPhone 6s
- iPhone 6s Plus
-
__weak NSString *string_weak_ = nil;- (void)viewDidLoad {[super viewDidLoad];// 场景 1NSString *string = [NSString stringWithFormat:@"leichunfeng"];string_weak_ = string;// 场景 2// @autoreleasepool {// NSString *string = [NSString stringWithFormat:@"leichunfeng"];// string_weak_ = string;// }// 场景 3// NSString *string = nil;// @autoreleasepool {// string = [NSString stringWithFormat:@"leichunfeng"];// string_weak_ = string;// }NSLog(@"string: %@", string_weak_);}- (void)viewWillAppear:(BOOL)animated {[super viewWillAppear:animated];NSLog(@"string: %@", string_weak_);}- (void)viewDidAppear:(BOOL)animated {[super viewDidAppear:animated];NSLog(@"string: %@", string_weak_);}思考得怎么样了?相信在你心中已经有答案了。那么让我们一起来看看 console 输出:
-
// 场景 12015-05-30 10:32:20.837 AutoreleasePool[33876:1448343] string: leichunfeng2015-05-30 10:32:20.838 AutoreleasePool[33876:1448343] string: leichunfeng2015-05-30 10:32:20.845 AutoreleasePool[33876:1448343] string: (null)// 场景 22015-05-30 10:32:50.548 AutoreleasePool[33915:1448912] string: (null)2015-05-30 10:32:50.549 AutoreleasePool[33915:1448912] string: (null)2015-05-30 10:32:50.555 AutoreleasePool[33915:1448912] string: (null)// 场景 32015-05-30 10:33:07.075 AutoreleasePool[33984:1449418] string: leichunfeng2015-05-30 10:33:07.075 AutoreleasePool[33984:1449418] string: (null)2015-05-30 10:33:07.094 AutoreleasePool[33984:1449418] string: (null)
- 跟你预想的结果有出入吗?Any way ,我们一起来分析下为什么会得到这样的结果。
分析:3 种场景下,我们都通过 [NSString stringWithFormat:@"leichunfeng"] 创建了一个 autoreleased 对象,这是我们实验的前提。并且,为了能够在 viewWillAppear 和 viewDidAppear中继续访问这个对象,我们使用了一个全局的 __weak 变量 string_weak_ 来指向它。因为 __weak 变量有一个特性就是它不会影响所指向对象的生命周期,这里我们正是利用了这个特性。场景 1:当使用 [NSString stringWithFormat:@"leichunfeng"] 创建一个对象时,这个对象的引用计数为 1 ,并且这个对象被系统自动添加到了当前的 autoreleasepool 中。当使用局部变量 string 指向这个对象时,这个对象的引用计数 +1 ,变成了 2 。因为在 ARC 下 NSString *string 本质上就是 __strong NSString *string 。所以在 viewDidLoad 方法返回前,这个对象是一直存在的,且引用计数为 2 。而当 viewDidLoad 方法返回时,局部变量 string 被回收,指向了 nil 。因此,其所指向对象的引用计数 -1 ,变成了 1 。而在 viewWillAppear 方法中,我们仍然可以打印出这个对象的值,说明这个对象并没有被释放。咦,这不科学吧?我读书少,你表骗我。不是一直都说当函数返回的时候,函数内部产生的对象就会被释放的吗?如果你这样想的话,那我只能说:骚年你太年经了。开个玩笑,我们继续。前面我们提到了,这个对象是一个 autoreleased 对象,autoreleased 对象是被添加到了当前最近的 autoreleasepool 中的,只有当这个 autoreleasepool 自身 drain 的时候,autoreleasepool 中的 autoreleased 对象才会被 release 。另外,我们注意到当在 viewDidAppear 中再打印这个对象的时候,对象的值变成了 nil ,说明此时对象已经被释放了。因此,我们可以大胆地猜测一下,这个对象一定是在 viewWillAppear 和 viewDidAppear 方法之间的某个时候被释放了,并且是由于它所在的 autoreleasepool 被 drain 的时候释放的。你说什么就是什么咯?有本事你就证明给我看你妈是你妈。额,这个我真证明不了,不过上面的猜测我还是可以证明的,不信,你看!在开始前,我先简单地说明一下原理,我们可以通过使用 lldb 的 watchpoint 命令来设置观察点,观察全局变量 string_weak_ 的值的变化,string_weak_ 变量保存的就是我们创建的 autoreleased 对象的地址。在这里,我们再次利用了 __weak 变量的另外一个特性,就是当它所指向的对象被释放时,__weak 变量的值会被置为 nil 。了解了基本原理后,我们开始验证上面的猜测。我们先在第 35 行打一个断点,当程序运行到这个断点时,我们通过 lldb 命令 watchpoint set v string_weak_ 设置观察点,观察 string_weak_ 变量的值的变化。如下图所示,我们将在 console 中看到类似的输出,说明我们已经成功地设置了一个观察点:
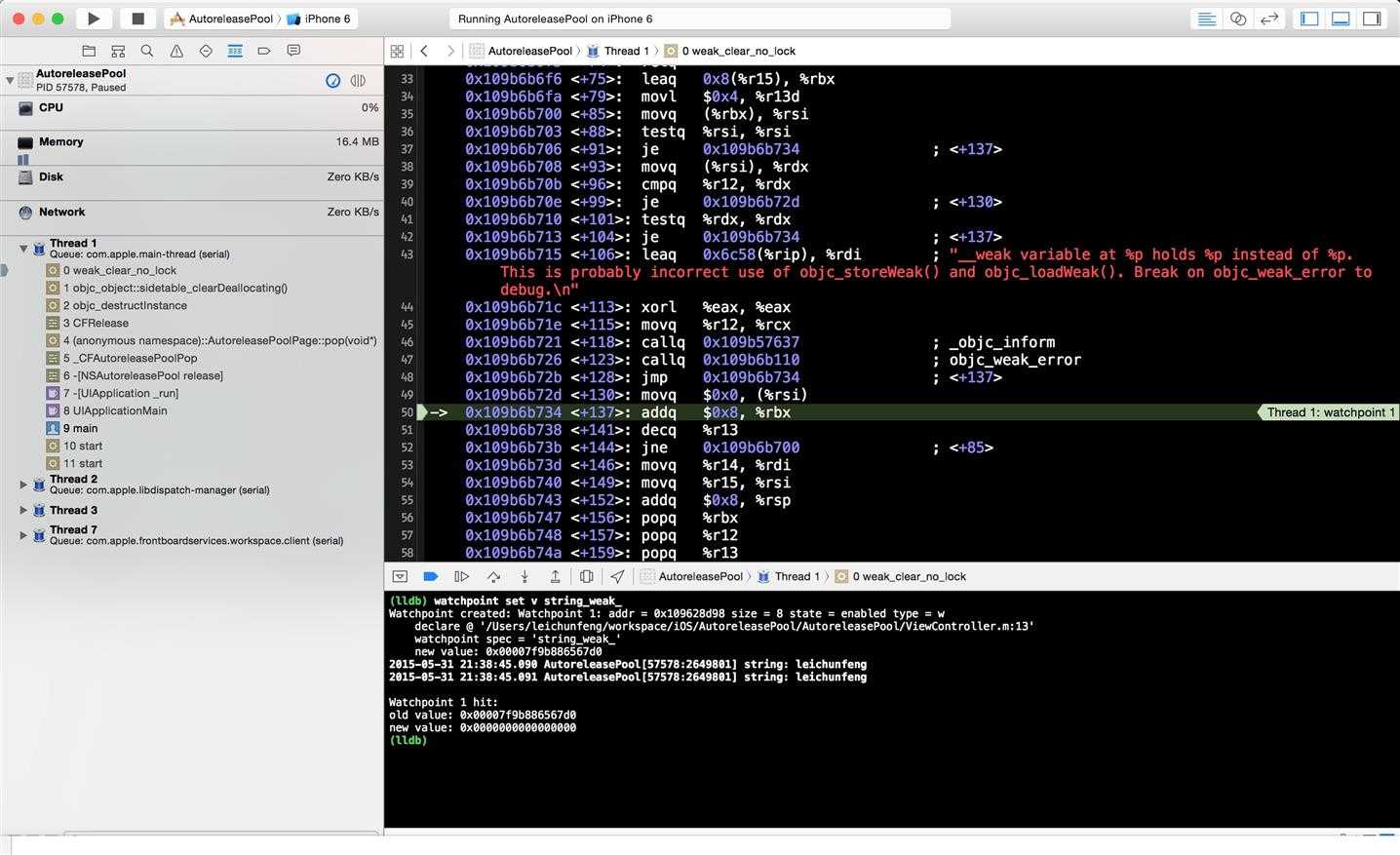
-
设置好观察点后,点击 Continue program execution 按钮,继续运行程序,我们将看到如下图所示的界面:
-
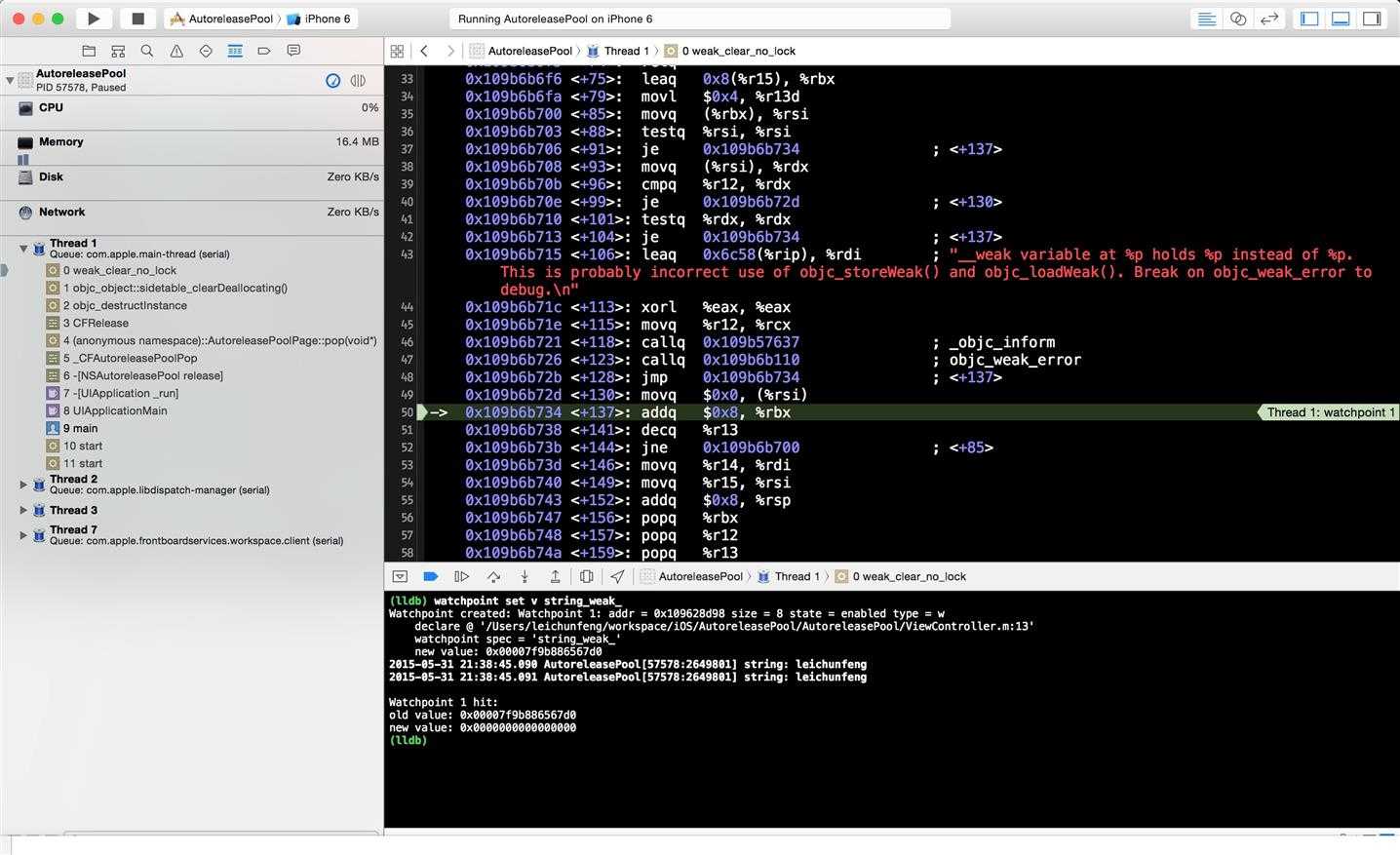
我们先看 console 中的输出,注意到 string_weak_ 变量的值由 0x00007f9b886567d0 变成了 0x0000000000000000 ,也就是 nil 。说明此时它所指向的对象被释放了。另外,我们也可以注意到一个细节,那就是 console 中打印了两次对象的值,说明此时 viewWillAppear 也已经被调用了,而 viewDidAppear 还没有被调用。
接着,我们来看看左侧的线程堆栈。我们看到了一个非常敏感的方法调用 -[NSAutoreleasePool release] ,这个方法最终通过调用 AutoreleasePoolPage::pop(void *) 函数来负责对 autoreleasepool 中的 autoreleased 对象执行 release 操作。结合前面的分析,我们知道在 viewDidLoad 中创建的 autoreleased 对象在方法返回后引用计数为 1 ,所以经过这里的 release 操作后,这个对象的引用计数 -1 ,变成了 0 ,该 autoreleased 对象最终被释放,猜测得证。另外,值得一提的是,我们在代码中并没有手动添加 autoreleasepool ,那这个 autoreleasepool 究竟是哪里来的呢?看完后面的章节你就明白了。场景 2:同理,当通过 [NSString stringWithFormat:@"leichunfeng"] 创建一个对象时,这个对象的引用计数为 1 。而当使用局部变量 string 指向这个对象时,这个对象的引用计数 +1 ,变成了 2 。而出了当前作用域时,局部变量 string 变成了 nil ,所以其所指向对象的引用计数变成 1 。另外,我们知道当出了 @autoreleasepool {} 的作用域时,当前 autoreleasepool 被 drain ,其中的 autoreleased 对象被 release 。所以这个对象的引用计数变成了 0 ,对象最终被释放。场景 3:同理,当出了 @autoreleasepool {} 的作用域时,其中的 autoreleased 对象被 release ,对象的引用计数变成 1 。当出了局部变量 string 的作用域,即 viewDidLoad 方法返回时,string 指向了 nil ,其所指向对象的引用计数变成 0 ,对象最终被释放。理解在这 3 种场景下,autoreleased 对象什么时候释放对我们理解 Objective-C 的内存管理机制非常有帮助。其中,场景 1 出现得最多,就是不需要我们手动添加 @autoreleasepool {} 的情况,直接使用系统维护的 autoreleasepool ;场景 2 就是需要我们手动添加 @autoreleasepool {} 的情况,手动干预 autoreleased 对象的释放时机;场景 3 是为了区别场景 2 而引入的,在这种场景下并不能达到出了 @autoreleasepool {} 的作用域时 autoreleased 对象被释放的目的。PS:请读者参考场景 1 的分析过程,使用 lldb 命令 watchpoint 自行验证下在场景 2 和场景 3 下 autoreleased 对象的释放时机,you should give it a try yourself 。AutoreleasePoolPage
细心的读者应该已经有所察觉,我们在上面已经提到了 -[NSAutoreleasePool release] 方法最终是通过调用 AutoreleasePoolPage::pop(void *) 函数来负责对 autoreleasepool 中的 autoreleased 对象执行 release 操作的。那这里的 AutoreleasePoolPage 是什么东西呢?其实,autoreleasepool 是没有单独的内存结构的,它是通过以 AutoreleasePoolPage 为结点的双向链表来实现的。我们打开 runtime 的源码工程,在 NSObject.mm 文件的第 438-932 行可以找到 autoreleasepool 的实现源码。通过阅读源码,我们可以知道:- 每一个线程的 autoreleasepool 其实就是一个指针的堆栈;
- 每一个指针代表一个需要 release 的对象或者 POOL_SENTINEL(哨兵对象,代表一个 autoreleasepool 的边界);
- 一个 pool token 就是这个 pool 所对应的 POOL_SENTINEL 的内存地址。当这个 pool 被 pop 的时候,所有内存地址在 pool token 之后的对象都会被 release ;
- 这个堆栈被划分成了一个以 page 为结点的双向链表。pages 会在必要的时候动态地增加或删除;
- Thread-local storage(线程局部存储)指向 hot page ,即最新添加的 autoreleased 对象所在的那个 page 。
一个空的 AutoreleasePoolPage 的内存结构如下图所示: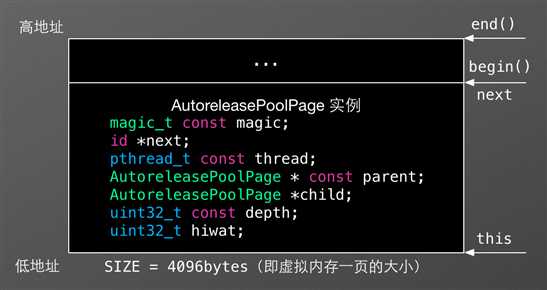
-
- magic 用来校验 AutoreleasePoolPage 的结构是否完整;
- next 指向最新添加的 autoreleased 对象的下一个位置,初始化时指向 begin() ;
- thread 指向当前线程;
- parent 指向父结点,第一个结点的 parent 值为 nil ;
- child 指向子结点,最后一个结点的 child 值为 nil ;
- depth 代表深度,从 0 开始,往后递增 1;
- hiwat 代表 high water mark 。
另外,当 next == begin() 时,表示 AutoreleasePoolPage 为空;当 next == end() 时,表示 AutoreleasePoolPage 已满。Autorelease Pool Blocks
我们使用 clang -rewrite-objc 命令将下面的 Objective-C 代码重写成 C++ 代码: -
123@autoreleasepool {}
将会得到以下输出结果(只保留了相关代码):
|
extern "C" __declspec(dllimport) void * objc_autoreleasePoolPush(void);
extern "C" __declspec(dllimport) void objc_autoreleasePoolPop(void *);
struct __AtAutoreleasePool {
__AtAutoreleasePool() {atautoreleasepoolobj = objc_autoreleasePoolPush();}
~__AtAutoreleasePool() {objc_autoreleasePoolPop(atautoreleasepoolobj);}
void * atautoreleasepoolobj;
};
/* @autoreleasepool */ { __AtAutoreleasePool __autoreleasepool;
}
|
不得不说,苹果对 @autoreleasepool {} 的实现真的是非常巧妙,真正可以称得上是代码的艺术。苹果通过声明一个 __AtAutoreleasePool 类型的局部变量 __autoreleasepool 来实现 @autoreleasepool {} 。当声明 __autoreleasepool 变量时,构造函数 __AtAutoreleasePool()被调用,即执行 atautoreleasepoolobj = objc_autoreleasePoolPush(); ;当出了当前作用域时,析构函数 ~__AtAutoreleasePool() 被调用,即执行 objc_autoreleasePoolPop(atautoreleasepoolobj); 。也就是说 @autoreleasepool {} 的实现代码可以进一步简化如下:
|
/* @autoreleasepool */ {
void *atautoreleasepoolobj = objc_autoreleasePoolPush();
// 用户代码,所有接收到 autorelease 消息的对象会被添加到这个 autoreleasepool 中
objc_autoreleasePoolPop(atautoreleasepoolobj);
}
|
因此,单个 autoreleasepool 的运行过程可以简单地理解为 objc_autoreleasePoolPush()、[对象 autorelease] 和 objc_autoreleasePoolPop(void *) 三个过程。
push 操作
上面提到的 objc_autoreleasePoolPush() 函数本质上就是调用的 AutoreleasePoolPage 的 push 函数。
void *
objc_autoreleasePoolPush(void)
{
if (UseGC) return nil;
return AutoreleasePoolPage::push();
}
因此,我们接下来看看 AutoreleasePoolPage 的 push 函数的作用和执行过程。一个 push 操作其实就是创建一个新的 autoreleasepool ,对应 AutoreleasePoolPage 的具体实现就是往 AutoreleasePoolPage 中的 next 位置插入一个 POOL_SENTINEL ,并且返回插入的 POOL_SENTINEL 的内存地址。这个地址也就是我们前面提到的 pool token ,在执行 pop 操作的时候作为函数的入参。
static inline void *push()
{
id *dest = autoreleaseFast(POOL_SENTINEL);
assert(*dest == POOL_SENTINEL);
return dest;
}push 函数通过调用 autoreleaseFast 函数来执行具体的插入操作。
![技术分享图片]()
|
1
2
3
4
5
6
7
8
9
10
11
|
static inline id *autoreleaseFast(id obj)
{
AutoreleasePoolPage *page = hotPage();
if (page && !page->full()) {
return page->add(obj);
} else if (page) {
return autoreleaseFullPage(obj, page);
} else {
return autoreleaseNoPage(obj);
}
}
|
autoreleaseFast 函数在执行一个具体的插入操作时,分别对三种情况进行了不同的处理:
- 当前 page 存在且没有满时,直接将对象添加到当前 page 中,即 next 指向的位置;
- 当前 page 存在且已满时,创建一个新的 page ,并将对象添加到新创建的 page 中;
- 当前 page 不存在时,即还没有 page 时,创建第一个 page ,并将对象添加到新创建的 page 中。
每调用一次 push 操作就会创建一个新的 autoreleasepool ,即往 AutoreleasePoolPage 中插入一个 POOL_SENTINEL ,并且返回插入的 POOL_SENTINEL 的内存地址。
autorelease 操作
通过 NSObject.mm 源文件,我们可以找到 -autorelease 方法的实现:
|
1
2
3
|
- (id)autorelease {
return ((id)self)->rootAutorelease();
}
|
通过查看 ((id)self)->rootAutorelease() 的方法调用,我们发现最终调用的就是 AutoreleasePoolPage 的 autorelease 函数。
|
1
2
3
4
5
6
7
|
__attribute__((noinline,used))
id
objc_object::rootAutorelease2()
{
assert(!isTaggedPointer());
return AutoreleasePoolPage::autorelease((id)this);
}
|
AutoreleasePoolPage 的 autorelease 函数的实现对我们来说就比较容量理解了,它跟 push 操作的实现非常相似。只不过 push 操作插入的是一个 POOL_SENTINEL ,而 autorelease 操作插入的是一个具体的 autoreleased 对象。
|
1
2
3
4
5
6
7
8
|
static inline id autorelease(id obj)
{
assert(obj);
assert(!obj->isTaggedPointer());
id *dest __unused = autoreleaseFast(obj);
assert(!dest || *dest == obj);
return obj;
}
|
pop 操作
同理,前面提到的 objc_autoreleasePoolPop(void *) 函数本质上也是调用的 AutoreleasePoolPage 的 pop 函数。
|
1
2
3
4
5
6
7
8
9
10
|
void
objc_autoreleasePoolPop(void *ctxt)
{
if (UseGC) return;
// fixme rdar://9167170
if (!ctxt) return;
AutoreleasePoolPage::pop(ctxt);
}
|
pop 函数的入参就是 push 函数的返回值,也就是 POOL_SENTINEL 的内存地址,即 pool token 。当执行 pop 操作时,内存地址在 pool token 之后的所有 autoreleased 对象都会被 release 。直到 pool token 所在 page 的 next 指向 pool token 为止。
下面是某个线程的 autoreleasepool 堆栈的内存结构图,在这个 autoreleasepool 堆栈中总共有两个 POOL_SENTINEL ,即有两个 autoreleasepool 。该堆栈由三个 AutoreleasePoolPage 结点组成,第一个 AutoreleasePoolPage 结点为 coldPage() ,最后一个 AutoreleasePoolPage 结点为 hotPage() 。其中,前两个结点已经满了,最后一个结点中保存了最新添加的 autoreleased 对象 objr3 的内存地址。
此时,如果执行 pop(token1) 操作,那么该 autoreleasepool 堆栈的内存结构将会变成如下图所示:
NSThread、NSRunLoop 和 NSAutoreleasePool
根据苹果官方文档中对 NSRunLoop 的描述,我们可以知道每一个线程,包括主线程,都会拥有一个专属的 NSRunLoop 对象,并且会在有需要的时候自动创建。
Each NSThread object, including the application’s main thread, has an NSRunLoop object automatically created for it as needed.
同样的,根据苹果官方文档中对 NSAutoreleasePool 的描述,我们可知,在主线程的 NSRunLoop 对象(在系统级别的其他线程中应该也是如此,比如通过 dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0) 获取到的线程)的每个 event loop 开始前,系统会自动创建一个 autoreleasepool ,并在 event loop 结束时 drain 。我们上面提到的场景 1 中创建的 autoreleased 对象就是被系统添加到了这个自动创建的 autoreleasepool 中,并在这个 autoreleasepool 被 drain 时得到释放。
The Application Kit creates an autorelease pool on the main thread at the beginning of every cycle of the event loop, and drains it at the end, thereby releasing any autoreleased objects generated while processing an event.
另外,NSAutoreleasePool 中还提到,每一个线程都会维护自己的 autoreleasepool 堆栈。换句话说 autoreleasepool 是与线程紧密相关的,每一个 autoreleasepool 只对应一个线程。
Each thread (including the main thread) maintains its own stack of NSAutoreleasePool objects.
弄清楚 NSThread、NSRunLoop 和 NSAutoreleasePool 三者之间的关系可以帮助我们从整体上了解 Objective-C 的内存管理机制,清楚系统在背后到底为我们做了些什么,理解整个运行机制等。
总结
看到这里,相信你应该对 Objective-C 的内存管理机制有了更进一步的认识。通常情况下,我们是不需要手动添加 autoreleasepool 的,使用线程自动维护的 autoreleasepool 就好了。根据苹果官方文档中对 Using Autorelease Pool Blocks 的描述,我们知道在下面三种情况下是需要我们手动添加 autoreleasepool 的:
- 如果你编写的程序不是基于 UI 框架的,比如说命令行工具;
- 如果你编写的循环中创建了大量的临时对象;
- 如果你创建了一个辅助线程。
9.RunLoop 的实现原理和数据结构,什么时候会用到
答案一:
Run loops是线程的基础架构部分。一个run loop就是一个事件处理循环,用来不停的调配工作以及处理输入事件。使用run loop的目的是使你的线程在有工作的时候工作,没有的时候休眠。
Run loop的管理并不完全是自动的。你仍必须设计你的线程代码以在适当的时候启动run loop并正确响应输入事件。Cocoa和CoreFundation都提供了run loop对象方便配置和管理线程的run loop。你创建的程序不需要显示的创建run loop;每个线程,包括程序的主线程(main thread)都有与之相应的run loop对象。但是,自己创建的次线程是需要手动运行run loop的。在carbon和cocoa程序中,程序启动时,主线程会自行创建并运行run loop。
接下来的部分将会详细介绍run loop以及如何为你的程序管理run loop。关于run loop对象可以参阅sdk文档。
解析Run Loop
run loop,顾名思义,就是一个循环,你的线程在这里开始,并运行事件处理程序来响应输入事件。你的代码要有实现循环部分的控制语句,换言之就是要有while或for语句。在run loop中,使用run loop对象来运行事件处理代码:响应接收到的事件,启动已经安装的处理程序。
Run loop处理的输入事件有两种不同的来源:输入源(input source)和定时源(timer source)。输入源传递异步消息,通常来自于其他线程或者程序。定时源则传递同步消息,在特定时间或者一定的时间间隔发生。两种源的处理都使用程序的某一特定处理路径。
图1-1显示了run loop的结构以及各种输入源。输入源传递异步消息给相应的处理程序,并调用runUntilDate:方法退出。定时源则直接传递消息给处理程序,但并不会退出run loop。
参考答案二:
Run loops是线程的基础架构部分。一个run loop就是一个事件处理循环,用来不停的调配工作以及处理输入事件。使用run loop的目的是使你的线程在有工作的时候工作,没有的时候休眠。
Run loop的管理并不完全是自动的。你仍必须设计你的线程代码以在适当的时候启动run loop并正确响应输入事件。Cocoa和CoreFundation都提供了run loop对象方便配置和管理线程的run loop。你创建的程序不需要显示的创建run loop;每个线程,包括程序的主线程(main thread)都有与之相应的run loop对象。但是,自己创建的次线程是需要手动运行run loop的。在carbon和cocoa程序中,程序启动时,主线程会自行创建并运行run loop。
接下来的部分将会详细介绍run loop以及如何为你的程序管理run loop。关于run loop对象可以参阅sdk文档。
解析Run Loop
run loop,顾名思义,就是一个循环,你的线程在这里开始,并运行事件处理程序来响应输入事件。你的代码要有实现循环部分的控制语句,换言之就是要有while或for语句。在run loop中,使用run loop对象来运行事件处理代码:响应接收到的事件,启动已经安装的处理程序。
Run loop处理的输入事件有两种不同的来源:输入源(input source)和定时源(timer source)。输入源传递异步消息,通常来自于其他线程或者程序。定时源则传递同步消息,在特定时间或者一定的时间间隔发生。两种源的处理都使用程序的某一特定处理路径。
图1-1显示了run loop的结构以及各种输入源。输入源传递异步消息给相应的处理程序,并调用runUntilDate:方法退出。定时源则直接传递消息给处理程序,但并不会退出run loop。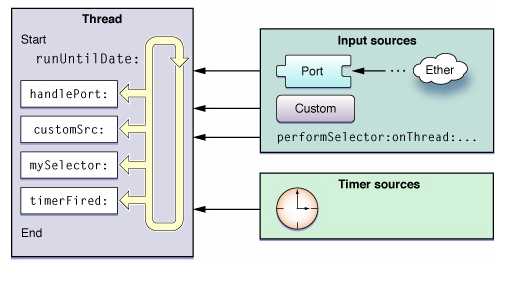
图1-1 run loop结构和几种源
除了处理输入源,run loop也会生成关于run loop行为的notification。注册的run-loop 观察者可以收到这些notification,并做相应的处理。可以使用Core Foundation在你的线程注册run-loop观察者。
下面介绍run loop的组成,以及其运行的模式。同时也提及在处理程序中不同时间发送不同的notification。
Run Loop Modes
Run loop模式是所有要监视的输入源和定时源以及要通知的注册观察者的集合。每次运行run loop都会指定其运行在哪个模式下。以后,只有相应的源会被监视并允许接收他们传递的消息。(类似的,只有相应的观察者会收到通知)。其他模式关联的源只有在run loop运行在其模式下才会运行,否则处于暂停状态。
通常代码中通过指定名字来确定模式。Cocoa和core foundation定义了默认的以及一系列常用的模式,都是用字符串来标识。当然你也可以指定字符串来自定义模式。虽然你可以给模式指定任何名字,但是所有的模式内容都是相同的。你必须添加输入源,定时器或者run loop观察者到你定义的模式中。
通过指定模式可以使得run loop在某一阶段只关注感兴趣的源。大多数时候,run loop都是运行在系统定义的默认模式。但是模态面板(modal panel)可以运行在 “模态”模式下。在这种模式下,只有和模态面板相关的源可以传递消息给线程。对于次线程,可以使用自定义模式处理时间优先的操作,即屏蔽优先级低的源传递消息。
Note:模式区分基于事件的源而非事件的种类。例如,你不可以使用模式只选择处理鼠标按下或者键盘事件。你可以使用模式监听端口,暂停定时器或者其他对源或者run loop观察者的处理,只要他们在当前模式下处于监听状态。
表1-1列出了cocoa和Core Foundation预先定义的模式。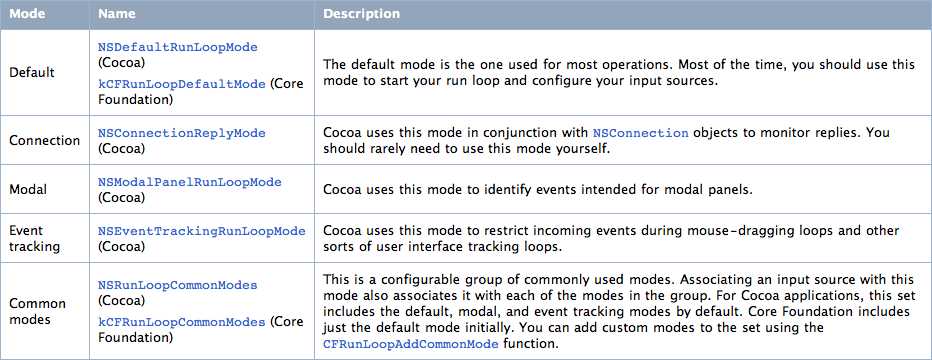
![技术分享图片]()
![技术分享图片]() Creating a run loop observer
Creating a run loop observer
![技术分享图片]() Listing 3-2 Running a run loop
Listing 3-2 Running a run loop
表1-1
输入源
输入源向线程发送异步消息。消息来源取决于输入源的种类:基于端口的输入源和自定义输入源。基于端口的源监听程序相应的端口,而自定义输入源则关注自定义的消息。至于run loop,它不关心输入源的种类。系统会去实现两种源供你使用。两类输入源的区别在于如何显示的:基于端口的源由内核自动发送,而自定义的则需要人工从其他线程发送。
当你创建输入源,你需要将其分配给run loop中的一个或多个模式。模式只会在特定事件影响监听的源。大多数情况下,run loop运行在默认模式下,但是你也可以使其运行在自定义模式。若某一源在当前模式下不被监听,那么任何其生成的消息只有当run loop运行在其关联的模式下才会被传递。
下面讨论这几种输入源。
基于端口的源:
cocoa和core foundation为使用端口相关的对象和函数创建的基于端口的源提供了内在支持。Cocoa中你从不需要直接创建输入源。你只需要简单的创建端口对象,并使用NSPort的方法将端口对象加入到run loop。端口对象会处理创建以及配置输入源。
在core foundation,你必须手动的创建端口和源,你都可以使用端口类型(CFMachPortRef,CFMessagePortRef,CFSocketRef)来创建。
更多例子可以看 配置基于端口的源。
自定义输入源:
在Core Foundation程序中,必须使用CFRunLoopSourceRef类型相关的函数来创建自定义输入源,接着使用回调函数来配置输入源。Core Fundation会在恰当的时候调用回调函数,处理输入事件以及清理源。
除了定义如何处理消息,你也必须定义源的消息传递机制——它运行在单独的进程,并负责传递数据给源和通知源处理数据。消息传递机制的定义取决于你,但最好不要过于复杂。
关于创建自定义输入源的例子,见 定义自定义输入源。关于自定义输入源的信息参见CFRunLoopSource。
Cocoa Perform Selector Sources:
除了基于端口的源,Cocoa提供了可以在任一线程执行函数(perform selector)的输入源。和基于端口的源一样,perform selector请求会在目标线程上序列化,减缓许多在单个线程上容易引起的同步问题。而和基于端口的源不同的是,perform selector执行完后会自动清除出run loop。
当perform selector在其它线程中执行时,目标线程须有一活动中的run loop。对于你创建的线程而言,这意味着线程直到你显示的开始run loop否则处于等待状态。然而,由于主线程自己启动run loop,在程序调用applicationDidFinishlaunching:的时候你会遇到线程调用的问题。因为Run loop通过每次循环来处理所有排列的perform selector调用,而不时通过每次的循环迭代来处理perform selector。
表1-2列出了NSObject可以在其它线程使用的perform selector。由于这些方法时定义在NSObject的,你可以在包括POSIX的所有线程中使用只要你有objc对象的访问权。注意这些方法实际上并没有创建新的线程以运行perform selector。
表1-2
定时源
定时源在预设的时间点同步地传递消息。定时器时线程通知自己做某事的一种方法。例如,搜索控件可以使用定时器,当用户连续输入的时间超过一定时间时,就开始一次搜索。这样,用户就可以有足够的时间来输入想要搜索的关键字。
尽管定时器和时间有关,但它并不是实时的。和输入源一样,定时器也是和run loop的运行模式相关联的。如果定时器所在的模式未被run loop监视,那么定时器将不会开始直到run loop运行在相应的模式下。类似的,如果定时器在run loop处理某一事件时开始,定时器会一直等待直到下次run loop开始相应的处理程序。如果run loop不再运行,那定时器也将永远不开始。
你可以选择定时器工作一次还是定时工作。如果定时工作,定时器会基于安排好的时间而非实际时间,自动的开始。举个例子,定时器在某一特定时间开始并设置5秒重复,那么定时器会在那个特定时间后5秒启动,即使在那个特定时间定时器延时启动了。如果定时器延迟到接下来设定的一个会多个5秒,定时器在这些时间段中也只会启动一次,在此之后,正常运行。(假设定时器在时间1,5,9。。。运行,如果最初延迟到7才启动,那还是从9,13,。。。开始)。
Run Loop观察者
源是同步或异步的传递消息,而run loop观察者则是在运行run loop的时候在特定的时候开始。你可以使用run loop观察者来为某一特定事件或是进入休眠的线程做准备。你可以将观察者将以下事件关联:
- Run loop入口
- Run loop将要开始定时
- Run loop将要处理输入源
- Run loop将要休眠
- Run loop被唤醒但又在执行唤醒事件前
- Run loop终止
你可以给cocoa和carbon程序随意添加观察者,但是如果你要定义观察者的话就只能使用core fundation。使用CFRunLoopObserverRed类型来创建观察者实例,它会追踪你自定义的回调函数以及其它你感兴趣的地方。
和定时器类似,观察者可以只用一次或循环使用。若只用一次,那在结束的时候会移除run loop,而循环的观察者则不会。你需要制定观察者是一次/多次使用。
消息的run loop顺序
每次启动,run loop会自动处理之前未处理的消息,并通知观察者。具体的顺序,如下:
- 通知观察者,run loop启动
- 通知观察者任何即将要开始的定时器
- 通知观察者任何非基于端口的源即将启动
- 启动任何准备好的非基于端口的源
- 如果基于端口的源准备好并处于等待状态,立即启动;并进入步骤9。
- 通知观察者线程进入休眠
- 将线程之于休眠直到任一下面的事件发生
- 某一事件到达基于端口的源
- 定时器启动
- 设置了run loop的终止时间
- run loop唤醒
- 通知观察者线程将被唤醒。
- 处理未处理的事件
- 如果用户定义的定时器启动,处理定时事件并重启run loop。进入步骤2
- 如果输入源启动,传递相应的消息
- run loop唤醒但未终止,重启。进入步骤2
- 通知观察者run loop结束。
(标号应该连续,不知道怎么改)
因为观察者的消息传递是在相应的事件发生之前,所以两者之间可能存在误差。如果需要精确时间控制,你可以使用休眠和唤醒通知以此来校对实际发生的事件。
因为定时器和其它周期性事件那是在run loop运行后才启动,撤销run loop也会终止消息传递。典型的例子就是鼠标路径追踪。因为你的代码直接获取到消息而不是经由程序传递,从而不会在实际的时间开始而须使得鼠标追踪结束并将控制权交给程序后才行。
使用run loop对象可以唤醒Run loop。其它消息也可以唤醒run loop。例如,添加新的非基于端口的源到run loop从而可以立即执行输入源而不是等待其他事件发生后再执行。
何时使用Run Loop
只有在为你的程序创建次线程的时候,才需要运行run loop。对于程序的主线程而言,run loop是关键部分。Cocoa和carbon程序提供了运行主线程run loop的代码同时也会自动运行run loop。IOS程序UIApplication中的run方法在程序正常启动的时候就会启动run loop。同样的这部分工作在carbon程序中由RunApplicationEventLoop负责。如果你使用xcode提供的模板创建的程序,那你永远不需要自己去启动run loop。
而对于次线程,你需要判断是否需要run loop。如果需要run loop,那么你要负责配置run loop并启动。你不需要在任何情况下都去启动run loop。比如,你使用线程去处理一个预先定义好的耗时极长的任务时,你就可以毋需启动run loop。Run loop只在你要和线程有交互时才需要,比如以下情况:
- 使用端口或自定义输入源和其他线程通信
- 使用定时器
- cocoa中使用任何performSelector
- 使线程履行周期性任务
如果决定在程序中使用run loop,那么配置和启动都需要自己完成。和所有线程编程一样,你需要计划好何时退出线程。在退出前结束线程往往是比被强制关闭好的选择。详细的配置和推出run loop的信息见 使用run loop对象。
使用Run loop对象
run loop对象提供了添加输入源,定时器和观察者以及启动run loop的接口。每个线程都有唯一的与之关联的run loop对象。在cocoa中,是NSRunLoop对象;而在carbon或BSD程序中则是指向CFRunLoopRef类型的指针。
获得run loop对象
获得当前线程的run loop,可以采用:
- cocoa:使用NSRunLoop的currentRunLoop类方法
- 使用CFRunLoopGetCurrent函数
虽然CFRunLoopRef类型和NSRunLoop对象并不完全等价,你还是可以从NSRunLoop对象中获取CFRunLoopRef类型。你可以使用NSRunLoop的getCFRunLoop方法,返回CFRunLoopRef类型到Core Fundation中。因为两者都指向同一个run loop,你可以任一替换使用。
配置run loop
在次线程启动run loop前,你必须至少添加一类源。因为如果run loop没有任何源需要监视的话,它会在你启动之际立马退出。
此外,你也可以添加run loop观察者来监视run loop的不同执行阶段。首先你可以创建CFRunLoopObserverRef类型并使用CFRunLoopAddObserver将它添加金run loop。注意即使是cocoa程序,run loop观察者也需要由core foundation函数创建。
以下代码3-1实现了添加观察者进run loop,代码简单的建立了一个观察者来监视run loop的所有活动,并将run loop的活动打印出来。
- (void)threadMain
{
// The application uses garbage collection, so no autorelease pool is needed.
NSRunLoop* myRunLoop = [NSRunLoop currentRunLoop];
// Create a run loop observer and attach it to the run loop.
CFRunLoopObserverContext context = {0, self, NULL, NULL, NULL};
CFRunLoopObserverRef observer = CFRunLoopObserverCreate(kCFAllocatorDefault,
kCFRunLoopAllActivities, YES, 0, &myRunLoopObserver, &context);
if (observer)
{
CFRunLoopRef cfLoop = [myRunLoop getCFRunLoop];
CFRunLoopAddObserver(cfLoop, observer, kCFRunLoopDefaultMode);
}
// Create and schedule the timer.
[NSTimer scheduledTimerWithTimeInterval:0.1 target:self
selector:@selector(doFireTimer:) userInfo:nil repeats:YES];
NSInteger loopCount = 10;
do
{
// Run the run loop 10 times to let the timer fire.
[myRunLoop runUntilDate:[NSDate dateWithTimeIntervalSinceNow:1]];
loopCount--;
}
while (loopCount);
}
如果线程运行事件长,最好添加一个输入源到run loop以接收消息。虽然你可以使用定时器,但是定时器一旦启动后当它失效时也会使得run loop退出。虽然定时器可以循环使得run loop运行相对较长的时间,但是也会导致周期性的唤醒线程。与之相反,输入源会等待某事件发生,于是线程只有当事件发生后才会从休眠状态唤醒。
启动run loop
run loop只对程序的次线程有意义,并且必须添加了一类源。如果没有,在启动后就会退出。有几种启动的方法,如:
- 无条件的
- 预设的时间
- 特定的模式
无条件的进入run loop是最简单的选择,但也最不提倡。因为这样会使你的线程处在一个永久的run loop中,这样的话你对run loop本身的控制就会很小。你可以添加或移除源,定时器,但是只能通过杀死进程的办法来退出run loop。并且这样的run loop也没有办法运行在自定义模式下。
用预设时间来运行run loop是一个比较好的选择,这样run loop在某一事件发生或预设的事件过期时启动。如果是事件发生,消息会被传递给相应的处理程序然后run loop退出。你可以重新启动run loop以处理下一个事件。如果是时间过期,你只需重启run loop或使用定时器做任何的其他工作。**
此外,使run loop运行在特定模式也是一个比较好的选择。模式和预设时间不是互斥的,他们可以同时存在。模式对源的限制在run loop模式部分有详细说明。
Listing3-2代码描述了线程的整个结构。代码的关键是说明了run loop的基本结构。必要时,你可以添加自己的输入源或定时器,然后重复的启动run loop。每次run loop返回,你要检查是否有使线程退出的条件发生。代码中使用了Core Foundation的run loop程序,这样就能检查返回结果从而判断是否要退出。若是cocoa程序,也不需要关心返回值,你也可以使用NSRunLoop的方法运行run loop(代码见listing3-14)
- (void)skeletonThreadMain
{
// Set up an autorelease pool here if not using garbage collection.
BOOL done = NO;
// Add your sources or timers to the run loop and do any other setup.
do
{
// Start the run loop but return after each source is handled.
SInt32 result = CFRunLoopRunInMode(kCFRunLoopDefaultMode, 10, YES);
// If a source explicitly stopped the run loop, or if there are no
// sources or timers, go ahead and exit.
if ((result == kCFRunLoopRunStopped) || (result == kCFRunLoopRunFinished))
done = YES;
// Check for any other exit conditions here and set the
// done variable as needed.
}
while (!done);
// Clean up code here. Be sure to release any allocated autorelease pools.
}
因为run loop有可能迭代启动,也就是说你可以使用CFRunLoopRun,CFRunLoopRunInMode或者任一NSRunLoop的方法来启动run loop。这样做的时候,你可以使用任何模式启动迭代的run loop,包括被外层run loop使用的模式。
退出run loop
在run loop处理事件前,有两种方法使其退出:
- 设置超时限定
- 通知run loop停止
如果可以配置的话,使用第一种方法是较好的选择。这样,可以使run loop完成所有正常操作,包括发送消息给run loop观察者,最后再退出。
使用CFRunLoopStop来停止run loop也有类似的效果。Run loop也会把所有未发送的消息发送完后再退出。与设置时间的区别在于你可以在任何情况下停止run loop。
尽管移除run loop的输入源和定时器也可以使run loop退出,但这并不是可靠的退出run loop的办法。一些系统程序会添加输入源来处理必须的事件。而你的代码未必会考虑到这些,这样就没有办法从系统程序中移除,从而就无法退出run loop。
线程安全和run loop对象
线程是否安全取决于你使用哪种API操纵run loop。Core Foundation中的函数通常是线程安全的可以被任意线程调用。但是,如果你改变了run loop的配置然后需要进行某些操作,你最好还是在run loop所在线程去处理。如果可能的话,这样是个好习惯。
至于Cocoa的NSRunLoop则不像Core Foundation具有与生俱来的线程安全性。你应该只在run loop所在线程改变run loop。如果添加yuan或定时器到属于另一个线程的run loop,程序会崩溃或发生意想不到的错误。
Run loop 源的配置
下面的例子说明了如果使用cocoa和core foundation来建立不同类型的输入源。
定义自定义输入源
遵循下列步骤来创建自定义的输入源:
- 输入源要处理的信息
- 使感兴趣的客户知道如何和输入源交互的调度程序
- 处理客户发送请求的程序
- 使输入源失效的取消程序
由于你自己创建源来处理消息,实际配置设计得足够灵活。调度,处理和取消程序是你创建你得自定义输入源时总会需要用到得关键程序。但是,输入源其他的大部分行为都是由其他程序来处理。例如,由你决定数据传输到输入源的机制,还有输入源和其他线程的通信机制。
图3-2列举了自定义输入源的配置。在这个例子中,程序的主线程保持了输入源,输入源所需的命令缓冲区和输入源所在的run loop的引用。当主线程有任务,需要分发给目标线程,主线程会给命令缓冲区发送命令和必须的信息,这样活动线程就可以开始执行任务。(因为主线程和输入源所在线程都须访问命令缓冲区,所以他们的操作要注意同步。)一旦命令传送了,主线程会通知输入源并且唤醒活动线程的run loop。而一收到唤醒命令,run loop会调用输入源的处理部分,由它来执行命令缓冲区中相应的命令。