Elasticsearch 横向扩容以及容错机制
Posted Hello
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch 横向扩容以及容错机制相关的知识,希望对你有一定的参考价值。
写在前面的话:读书破万卷,编码如有神
--------------------------------------------------------------------
参考内容:
《Elasticsearch顶尖高手系列-快速入门篇》,中华石杉
--------------------------------------------------------------------
主要内容包括:
- 横向扩容
- 容错机制
--------------------------------------------------------------------
1、Elasticsearch横向扩容
1.1、primary shard 和 replica shard自动负载均衡
目前情况:2个node, 3个primary shard,3个replica shard
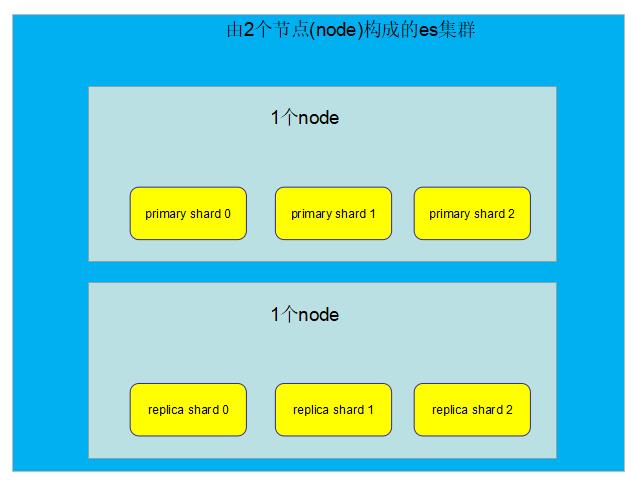
如果此时给es集群增加一个节点(node),es会自动对primary shard和replica shard进行负载均衡
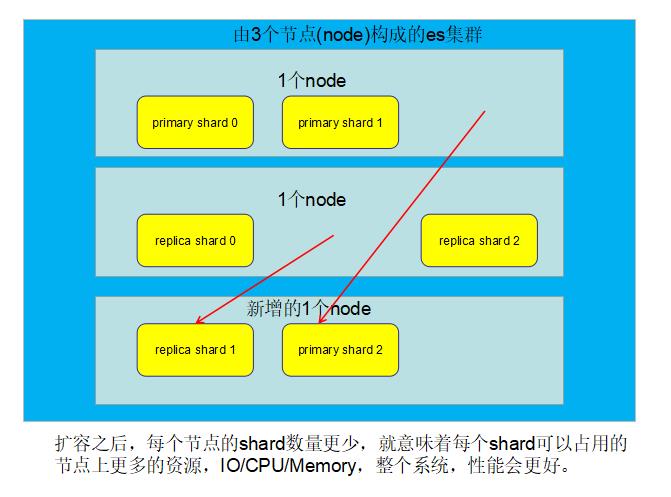
1.2、每个Node有更少的shard, IO/CPU/Memory资源给每个shard分配更多,每个shard性能更好
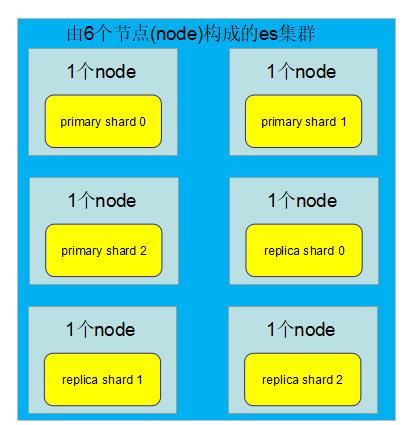
1.3、扩容的极限,6个shard(3个primary shard,3个replica shard),最多扩容到6台机器,每个shard可以占用单台服务器的所有资源,性能最好
--------------------------------------------------------------------
2、Elasticsearch容错机制
2.1、master选举、replica容错、数据恢复
目前es集群情况:3个node,9个shard(3个primary shard,6个replica shard)
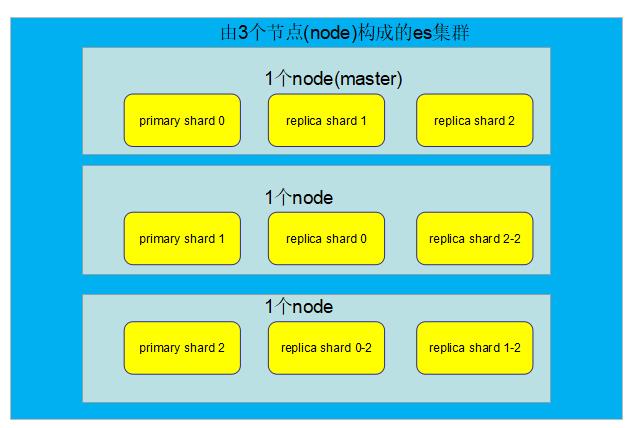
如果此时master node宕机:
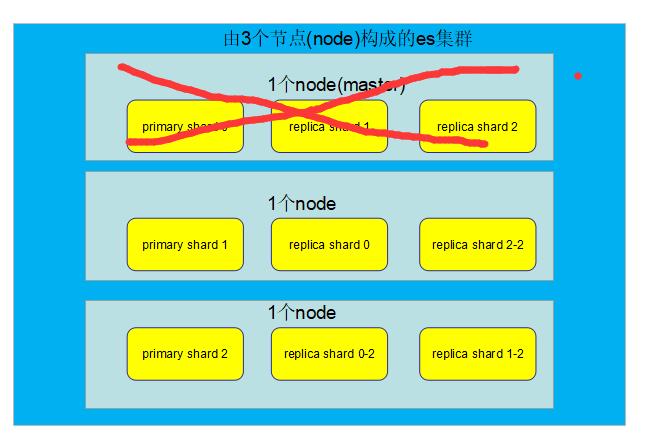
因为Node1节点宕机了,所以primary shard0、replica shard1、replica shard2三个3shard就丢失了。master node宕机的一瞬间,primary shard0这个shard就没有了,此时就不是active status,所以集群的状态为red.
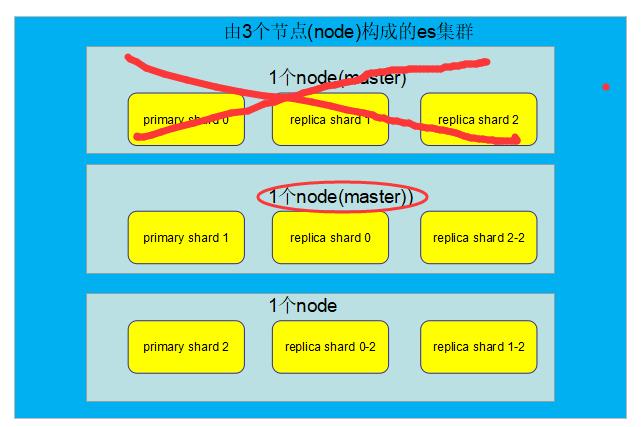
容错第一步:master选举,自动选举另外一个node成为新的master,承担起master的责任来:
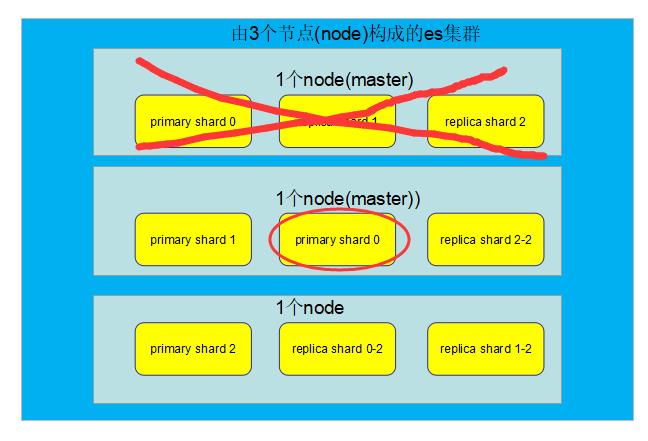
容错第二步:新master将丢失的primary shard的某个replica shard提升为primary shard,此时cluster status会变为Yellow,因为所有的primary shard都变成了active status,但是,少了一个replica shard,所以不是所有的replica shard都是active。
容错第三步:重启故障的node, new master节点将会把缺失的副本都copy一份到该node上去,而且该node会使用之前已有的shard数据,只是同步一下宕机之后发生的改变。
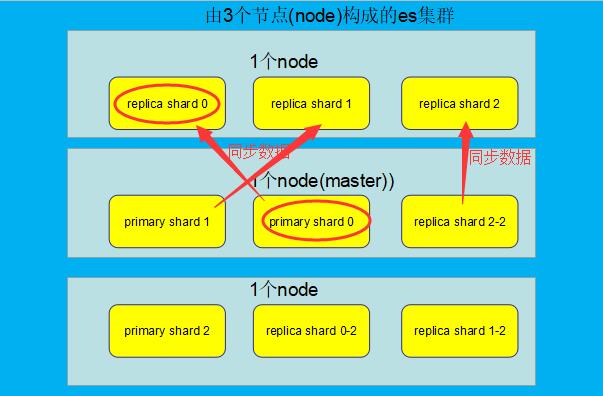
此时es cluster的状态为green,因为所有的primary shard和replica shard都是active状态。
--------------------------------------------------------------------
以上是关于Elasticsearch 横向扩容以及容错机制的主要内容,如果未能解决你的问题,请参考以下文章