Scrapy 安装与使用
Posted 微甜心语
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Scrapy 安装与使用相关的知识,希望对你有一定的参考价值。
当前环境win10,python_3.6.4,64bit。在命令提示符窗口运行pip install Scrapy,出现以下结果:
building \'twisted.test.raiser\' extension error: Microsoft Visual C++ 14.0 is required. Get it with "Microsoft Visual C++ Build Tools": http://landinghub.visualstudio.com/visual-cpp-build-tools
按报错提示安装之后错误依旧存在;
http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted> 下载Twisted对应版本的whl文件,cp后面是python版本,amd64代表64位,重新运行pip install命令:
pip install C:\\Users\\E5-573G\\Desktop\\2018寒假\\Python\\爬虫\\scrapy\\Twisted-17.5.0-cp36-cp36m-win_amd64.whl1
其中install后面为下载的whl文件的完整路径名 。
然后再次运行 pip install scrapy 命令即可安装成功。
Scrapy命令行格式:

Scrapy常用命令:
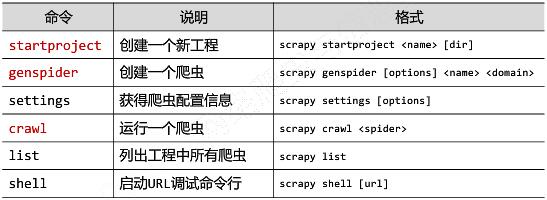
应用Scrapy爬虫框架主要是编写配置型代码。
Scrapy的第一个实例:演示html地址。
演示HTML页面地址:http://python123.io/ws/demo.html
文件名称:demo.html

产生步骤:
步骤1:建立一个Scrapy爬虫工程;
选取一个目录(C:\\Users\\E5-573G\\Desktop\\2018寒假\\Python\\爬虫\\scrapy),然后执行如下命令:

生成的工程目录:
python123demo/ ——————— 外层目录
scrapy.cfg ——————— 部署Scrapy爬虫的配置文件
python123demo/ ——————— Scrapy框架的用户自定义python代码
init.py ——————— 初始化脚本
items.py ——————— Items代码模板(继承类)
middlewares.py ————— Middlewares代码模块(继承类)
pipelines.py ————— Pipelines.py代码模块(继承类)
settings.py ————— Scrapy爬虫的配置文件
spiders/ ————— Spiders代码模块目录(继承类)
目录结构 pycache/ ————— 缓存目录,无需修改
spiders/ ————— Spiders代码模块目录(继承类)
init.py ————— 初始化脚本
pycache/ ————— 缓存目录,无需修改
内层目录结构 用户自定义的spider代码增加在此处
步骤2:在工程中产生一个Scrapy爬虫
进入工程目录(C:\\Users\\E5-573G\\Desktop\\2018寒假\\Python\\爬虫\\scrapy\\python123demo)。然后执行如下命令:

该命令行作用:
生成一个名称为demo的spider
在spiders目录下增加代码文件demo.py
#demo.py # -*- coding : utf-8 -*- import scrapy class DemoSpider(scrapy.Spider) : name = "demo" allowed_domains = ["python123.io"] start_urls = [\'heep://python123.io/\'] def parse (self,response): #parse()用于处理响应,解析内容形成字典,发现新的URL爬取请求 pass
步骤3:配置产生spider爬虫
配置:(1)初始URL地址 (2)获取页面后的解析方式
#demo1.py # -*- coding : utf-8 -*- import scrapy class DemoSpider(scrapy.Spider) : name = "demo" # allowed_domains = ["python123.io"] #可选 start_urls = [\'heep://python123.io/ws/demo.html\'] def parse (self,response): #parse()用于处理响应,解析内容形成字典,发现新的URL爬取请求 fname = response.url.split(\'/\')[-1] with open (fname,\'wb\') as f: f.write(response.body) self.log(\'Saved file %s.\' % fname)
步骤4:运行爬虫,获取网页
在命令行,执行如下命令:

demo爬虫被执行,捕获页面存储在demo.html
回顾demo.py代码
#demo.py # -*- coding : utf-8 -*- import scrapy class DemoSpider(scrapy.Spider) : name = "demo" start_urls = [\'heep://python123.io/ws/demo.html\'] def parse (self,response): #parse()用于处理响应,解析内容形成字典,发现新的URL爬取请求 fname = response.url.split(\'/\')[-1] with open (fname,\'wb\') as f: f.write(response.body) self.log(\'Saved file %s.\' % fname)
demo.py代码的完整版本
#demo all.py import scrapy class DemoSpider(scrapy.Spider) : name = "demo" def start_urls(self): urls= [\'heep://python123.io/ws/demo.html\'] for url in urls: yield scrapy.Request(url = url,callback = self.parse) def parse (self,response): #parse()用于处理响应,解析内容形成字典,发现新的URL爬取请求 fname = response.url.split(\'/\')[-1] with open (fname,\'wb\') as f: f.write(response.body) self.log(\'Saved file %s.\' % fname)
yield关键字的作用
yield <---------->生成器:包含yield语句的函数是一个生成器;
生成器每次产生一个值(yield语句),函数被冻结,被唤醒后在产生一个值。生成器是一个不断产生值的函数。
生成器每调用一次在yield位置产生一个值,直到函数执行结束。
生成器相比一次列出所有内容的优势:
更节省存储空间;
响应更迅速;
使用更灵活;
Scrapy爬虫的使用步骤:
步骤1:创建一个工程和Spider模板;
步骤2:编写Spider
步骤3:编写Item Pipeline
步骤4:优化配置策略
Scrapy爬虫的数据类型:
Request类、Response类、Item类
Request类:class scrapy.http.Request()
Request对象表示一个HTTP请求,由Spider生成,由Downloader执行。
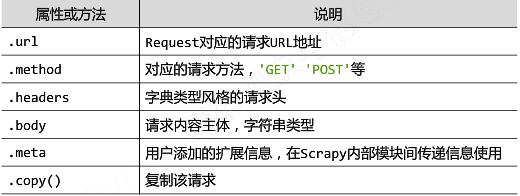
Response类:class scrapy.http.Response()
Response对象表示一个HTTP响应由Downloader生成,由Spider处理。
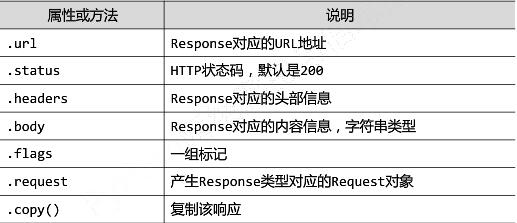
Item类: class scrapy.item.Item()
Item对象表示一个从HTML页面中提取的信息内容;由Spider生成,由Item Pipeline处理,Item类似字典类型,可以按照字典类型操作。
Scrapy爬虫提取信息的方法:
scrapy爬虫支持多种HTML信息提取方法:Beautiful Scoop、lxml、re、XPath Selector、CSS Selector
CSS Selector的基本使用:
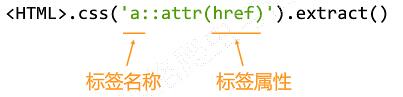
CSS Selector由W3C组织维护并规范。
”股票数据Scrapy爬虫”实例介绍
功能描述:
目标:获取上交所和深交所所有股票的名称和交易信息
输出:保存到文件中
技术路线:scrapy
数据网站的确定
获取股票列表:
东方财富网:http://quote.easymoney.com/stocklist.html
获取个股信息:
百度股票:http://gupiao.baidu.com/stock/
单个股票:http://gupiao.baidu..com/stock/sz002439.html
编写spider处理链接爬取和页面解析,编写pipelines处理信息存储
步骤:
步骤1:创建工程和Spider模板;
>scrapy startproject BaiduStocks
>cd BaiduStocks
>scrapy genspider stocks baidu.com
进一步修改spiders/stock.py文件
步骤2:编写Spider
配置stocks.py文件
修改对返回页面的处理
修改对新增URL爬取请求的处理
步骤3:编写Item Pipeline
以上是关于Scrapy 安装与使用的主要内容,如果未能解决你的问题,请参考以下文章