BeautifulSoup库的安装与使用
Posted 微甜心语
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了BeautifulSoup库的安装与使用相关的知识,希望对你有一定的参考价值。
Win平台:“以管理员身份运行” cmd
执行 pip install beautifulsoup4
演示html页面地址:http://python123.io/ws//demo.html
文件名称:demo.html

网页源代码:HTML 5.0 格式代码

BeautifulSoup库的安装小测:
>>> import requests >>> r = requests.get("http://python123.io/ws//demo.html") >>> r.text \'<html><head><title>This is a python demo page</title></head>\\r\\n<body>\\r\\n<p class="title"><b>The demo python introduces several python courses.</b></p>\\r\\n<p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:\\r\\n<a href="http://www.icourse163.org/course/BIT-268001" class="py1" id="link1">Basic Python</a> and <a href="http://www.icourse163.org/course/BIT-1001870001" class="py2" id="link2">Advanced Python</a>.</p>\\r\\n</body></html>\' >>> demo = r.text >>> from bs4 import BeautifulSoup >>> soup = BeautifulSoup(demo,\'html.parser\') >>> print(soup.prettify()) <html> <head> <title> This is a python demo page </title> </head> <body> <p class="title"> <b> The demo python introduces several python courses. </b> </p> <p class="course"> Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses: <a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1"> Basic Python </a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2"> Advanced Python </a> . </p> </body> </html> >>>
Beautiful Soup库的基本元素:
Beautiful Soup库的理解:

Beautiful Soup库是解析、遍历、维护“标签树”的功能库。
<p>..</p> : 标签Tag

Beautiful Soup库的引用:
from bs4 import BeautifulSoup
import bs4
Beautiful Soup库解析器:
soup = BeautifulSoup (\'<html>data</html>\',\'html.parser\')

BeautifulSoup类的基本元素:
< p class = "title" > ... </p>

Tag标签:
>>> from bs4 import BeautifulSoup >>> soup = BeautifulSoup(demo,\'html.parser\') >>> soup.title <title>This is a python demo page</title> >>> tag = soup.a >>> tag <a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>
任何存在于HTML语法中的标签都可以用soup.<tag>访问获得当HTML文档中存在多个相同<tag>对应内容时,soup.<tag>返回第一个
Tag的name:
>>> from bs4 import BeautifulSoup >>> soup = BeautifulSoup(demo,\'html.parser\') >>> soup.a.name \'a\' >>> soup.a.parent.name \'p\' >>> soup.a.parent.parent.name \'body\' >>>
每个<tag>都有自己的名字,通过<tag>.name获取,字符串类型
Tag的attrs(属性):
>>> tag = soup.a >>> tag.attrs {\'href\': \'http://www.icourse163.org/course/BIT-268001\', \'class\': [\'py1\'], \'id\': \'link1\'} >>> tag.attrs[\'class\'] [\'py1\'] >>> tag.attrs[\'href\'] \'http://www.icourse163.org/course/BIT-268001\' >>> type(tag.attrs) <class \'dict\'> >>> type(tag) <class \'bs4.element.Tag\'>
一个<tag>可以有0或多个属性,字典类型
Tag的NavigableString:
>>> soup.a <a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> >>> soup.a.string \'Basic Python\' >>> soup.p <p class="title"><b>The demo python introduces several python courses.</b></p> >>> soup.p.string \'The demo python introduces several python courses.\' >>> type(soup.p.string) <class \'bs4.element.NavigableString\'>
NavigableString可以跨越多个层次
Tag的Comment:
>>> newsoup = BeautifulSoup("<b><!--This is a comment--></b><p>This is not a comment</p>","html.parser") >>> newsoup.b.string \'This is a comment\' >>> type(newsoup.b.string) <class \'bs4.element.Comment\'> >>> newsoup.p.string \'This is not a comment\' >>> type(newsoup.p.string) <class \'bs4.element.NavigableString\'>
Comment是一种特殊类型
标签<tag>

基于bs4库的HTML内容遍历方法:
HTML基本格式:
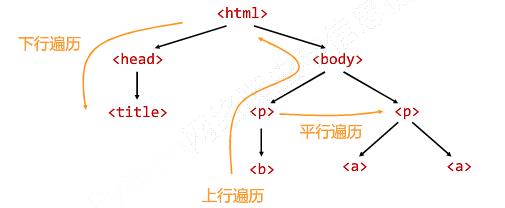
<>...</>构成了所属关系,形成了标签的树形结构
标签树的下行遍历:

BeautifulSoup类型是标签树的根节点
标签树的下行遍历
>>> soup = BeautifulSoup(demo,\'html.parser\') >>> soup.head <head><title>This is a python demo page</title></head> >>> soup.head.contents [<title>This is a python demo page</title>] >>> soup.body.contents [\'\\n\', <p class="title"><b>The demo python introduces several python courses.</b></p>, \'\\n\', <p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses: <a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p>, \'\\n\'] >>> len(soup.body.contents) 5 >>> soup.body.contents[1] <p class="title"><b>The demo python introduces several python courses.</b></p>
遍历儿子节点:
for child in soup.body.children: print(child)
遍历子孙节点:
for child in soup.body.descendants: print(child)
标签树的上行遍历:

soup = BeautifulSoup(demo,\'html.parser\') for parent in soup.a.parents: #标签树的上行遍历 if parent is None: print(parent) else: print(parent.name)
遍历所有先辈节点,包括soup本身,所以要区别判断
运行结果:

标签树的平行遍历:
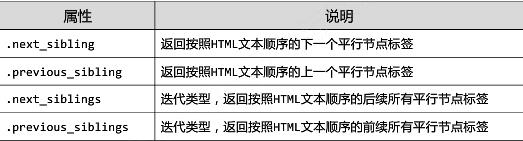
平行遍历发生在同一个父节点下的各节点间
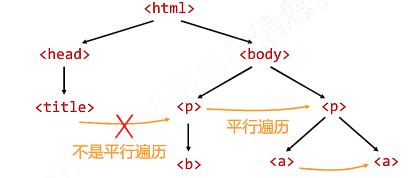
遍历的判断:
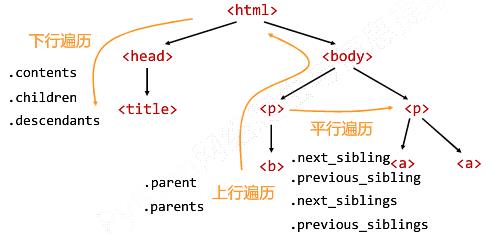
让HTML内容更加“友好”的显示:
bs4库的prettify()方法:
>>> import requests >>> r = requests.get("http://python123.io/ws//demo.html") >>> demo = r.text >>> demo \'<html><head><title>This is a python demo page</title></head>\\r\\n<body>\\r\\n<p class="title"><b>The demo python introduces several python courses.</b></p>\\r\\n<p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:\\r\\n<a href="http://www.icourse163.org/course/BIT-268001" class="py1" id="link1">Basic Python</a> and <a href="http://www.icourse163.org/course/BIT-1001870001" class="py2" id="link2">Advanced Python</a>.</p>\\r\\n</body></html>\' >>> soup = BeautifulSoup(demo,\'html.parser\') >>> soup.prettify() \'<html>\\n <head>\\n <title>\\n This is a python demo page\\n </title>\\n </head>\\n <body>\\n <p class="title">\\n <b>\\n The demo python introduces several python courses.\\n </b>\\n </p>\\n <p class="course">\\n Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:\\n <a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">\\n Basic Python\\n </a>\\n and\\n <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">\\n Advanced Python\\n </a>\\n .\\n </p>\\n </body>\\n</html>\' >>> print(soup.prettify()) <html> <head> <title> This is a python demo page </title> </head> <body> <p class="title"> <b> The demo python introduces several python courses. </b> </p> <p class="course"> Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses: <a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1"> Basic Python </a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2"> Advanced Python </a> . </p> </body> </html>
.prettify()为HTML文本<>及其内容增加\'\\n\'
.prettify()可用于标签,方法:<tag>.prettify()
>>> print(soup.a.prettify()) <a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1"> Basic Python </a>
bs4库的编码:
bs4库将任何HTML输入都变为utf-8编码,Python 3.x默认支持编码是utf-8,解析无障碍。
>>> soup = BeautifulSoup("<p>中文</p>",\'html.parser\') >>> soup.p.string \'中文\' >>> print(soup.p.prettify()) <p> 中文 </p>
以上是关于BeautifulSoup库的安装与使用的主要内容,如果未能解决你的问题,请参考以下文章