你真的了解URL encode吗?
Posted MittyoO
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了你真的了解URL encode吗?相关的知识,希望对你有一定的参考价值。
最近因项目需要,需重写网络组件。在重写及review项目组的网络组件旧代码时,发现对URL编码有不严谨之处。当说到这种写法其实是有问题时,几个同事都表示非常诧异并几度辩驳。本人表示有点小心惊,在网上搜索时还真的很少有另外的写法。在此以自己的一些理解和经验,做一下URL编码的普及,希望对大家有所帮助,有问题也请不吝赐教。 (参考RFC1738,3986,6874,7320)
一、了解URL编码以及编码时机、运算过程
URI包括URL和URN,常用说法URL encode实际是遵循URI的相关文件。在URI的最初设计时,希望能通过书面转录,比如写在餐巾纸上告诉另外一人,因此URI的构成字符必须是可写的ASCII字符。在这些可书写的字符里,由于一些字符在不同操作系统的编码有不同的解析,被包含在Unsafe characters(图3)之中,要格外注意。最后,在URI的构成字符中,最安全的方案是正确使用Reserved Characters (图1)和 Unreserved Characters (图1)的并集。
在对非法字符编码到合法URI时,规定使用percent encode编码,对非法字符的编码结果为三个字节(%+16进制字符*2)。然而如何生成percent编码,没有明确的指导规定,这也是大部分开发者拷贝旧代码却不知其所以然的原因。
percent encode从字面上语义明确的指出其使用%做编码标识,URL encode的实质就是正确的使用percent encode.
正确完成URL encode的关键问题在于:什么时候,对哪些内容,采用何种过滤原则,以及如何生成percent编码?
在WWW最初时,做法是将字符流转换成字节流,按照ASCII字符与字节一一对应可相互转换,使用对应ASCII字符的整型值作为%的后两个16进制字符,构成percent编码。后来出现了多种percent编码生成方法,导致了URI的难以识别。
现下做法,包括ios使用percent相关的函数时,指定或系统默认的使用UTF8转成字节流,每个字节编成一个percent编码,例如中文“网易”的URL编码为%e7%bd%91%e6%98%93,而其UTF8字节流为e7 bd 91 e6 93,可以看出其一一对应关系。
那么percent编码是在对非法字符采用某种编码(约定为UTF8)转成字节流后,逐字节加上%构成percent编码。
由于不同scheme或协议对URI格式有不同的要求,RFC关于对哪些内容编码,采用何种过滤原则不做硬性规定。而将决定权延后到执行时由开发者根据需要决定。通常遵循以下原则:
1.不要对Unreserved Characters做percent encode编码。
2.除了保留字符和非保留字符外的所有字符,必须使用percent encode进行编码。
3.保留字符不用于URI分隔符,而是用于其它位置,比如query部分的value时,要对这时用到的保留字符做percent encode编码。
4.当两个URI的字符几乎对等,区别只在于一个对某些字符用的原有字符,另一个URI对这些字符做了percent encode时。绝大部分情况下,这两个URI应当被认为是不同的两个URI。因此,不应当对保留字在作为保留字的使用场景时使用percent encode编码。
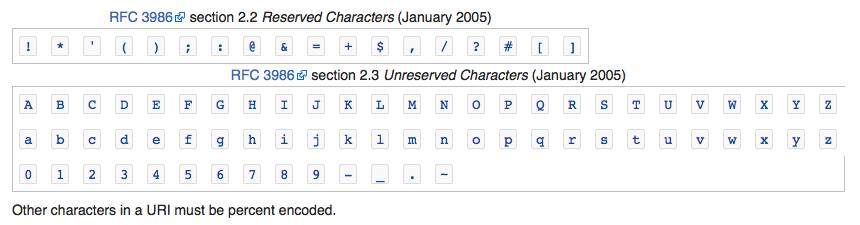
图1. 保留字和非保留字

图2 不安全字符
二、iOS开发中URL encode的方法编写
有三个函数或系统方法用于URL encode,CFURLCreateStringByAddingPercentEscapes(9.0废弃),stringByAddingPercentEscapesUsingencode(9.0废弃),
stringByAddingPercentencodeWithAllowedCharacters(系统推荐)。该系统推荐方法默认使用了UTF8编码然后再根据我们指定允许的字符集完成percent编码。通常我们在拼接GET请求URL时使用URL encode。
应用场景一般是传入URLString和一个参数NSDictionary, 这时需要传入方保证URLString是已正确编码的,然后遍历NSDictionary的key和value, 按需指定允许的字符集对key值和value做编码。结果输出为
+ (NSURL *) createGETURLFromString:(NSString *)urlString params:(NSDictionary *)params { NSURL *parsedURL = [NSURL URLWithString:urlString]; NSString* queryPrefix = parsedURL.query ? @"&" : @"?"; NSMutableArray* pairs = [NSMutableArray array]; for (NSString* key in [params keyEnumerator]) { if (![[params objectForKey:key] isKindOfClass:[NSString class]]) { continue; } NSString *value = (NSString *)[params objectForKey:key]; NSCharacterSet *allowedCharacterSet = [NSCharacterSet characterSetWithCharactersInString:@"ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789-_.~"]; NSString *urlEncodingKey = [key stringByAddingPercentEncodingWithAllowedCharacters:allowedCharacterSet]; NSString *urlEncodingValue = [value stringByAddingPercentEncodingWithAllowedCharacters:allowedCharacterSet]; [pairs addObject:[NSString stringWithFormat:@"%@=%@", urlEncodingKey, urlEncodingValue]]; } NSString* query = [pairs componentsJoinedByString:@"&"]; return [NSURL URLWithString:[NSString stringWithFormat:@"%@%@%@", urlString, queryPrefix, query]]; }
有的iOS开发者拿到 GET请求URLString和参数字典后,先拼接参数,然后再对整个字符串做URL encode,造成不能区分某些字符是处于分割组件的作用,或者是作为组件的content。这是千万不可取的,可能发生如下问题:
1.如果没有正确过滤,比如http://www.baidu.com做编码后变成了http%3a%2f%2fwww.baidu.com%2findex.htm,将不能正常访问。 也就是说,为了支持对拼接后的字符串作URL encode, 必须对整个拼接后的字符串禁止对所有URI的保留字作编码,比如&字符,这就造成了问题2和3。
以上是关于你真的了解URL encode吗?的主要内容,如果未能解决你的问题,请参考以下文章