作者:szx_spark
1. 经典网络
-
LeNet-5
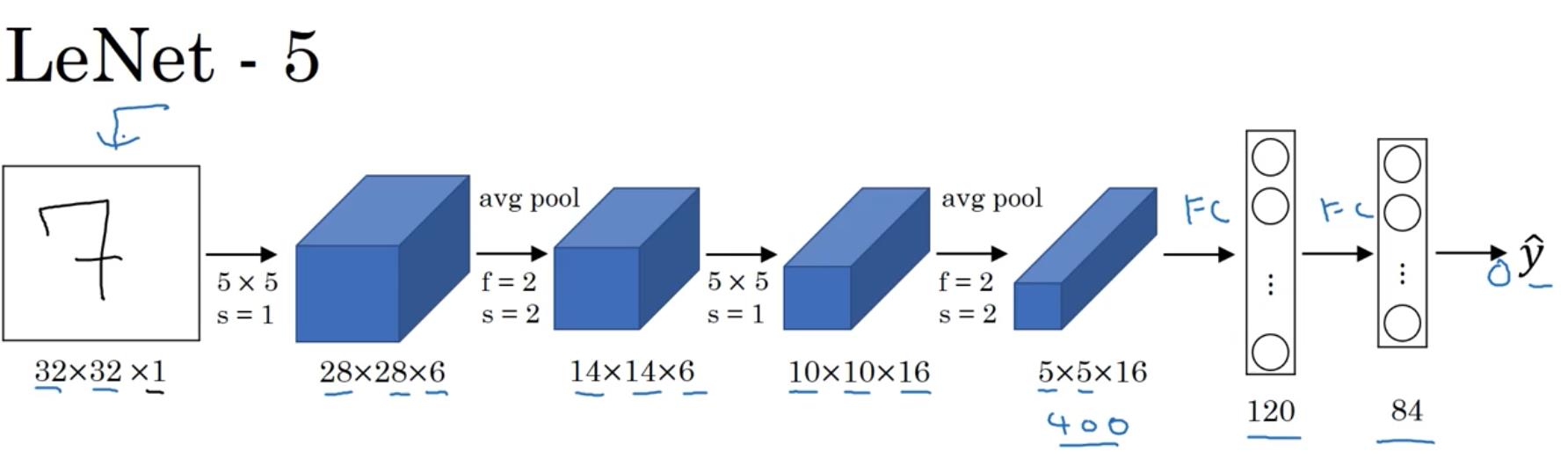
-
AlexNet
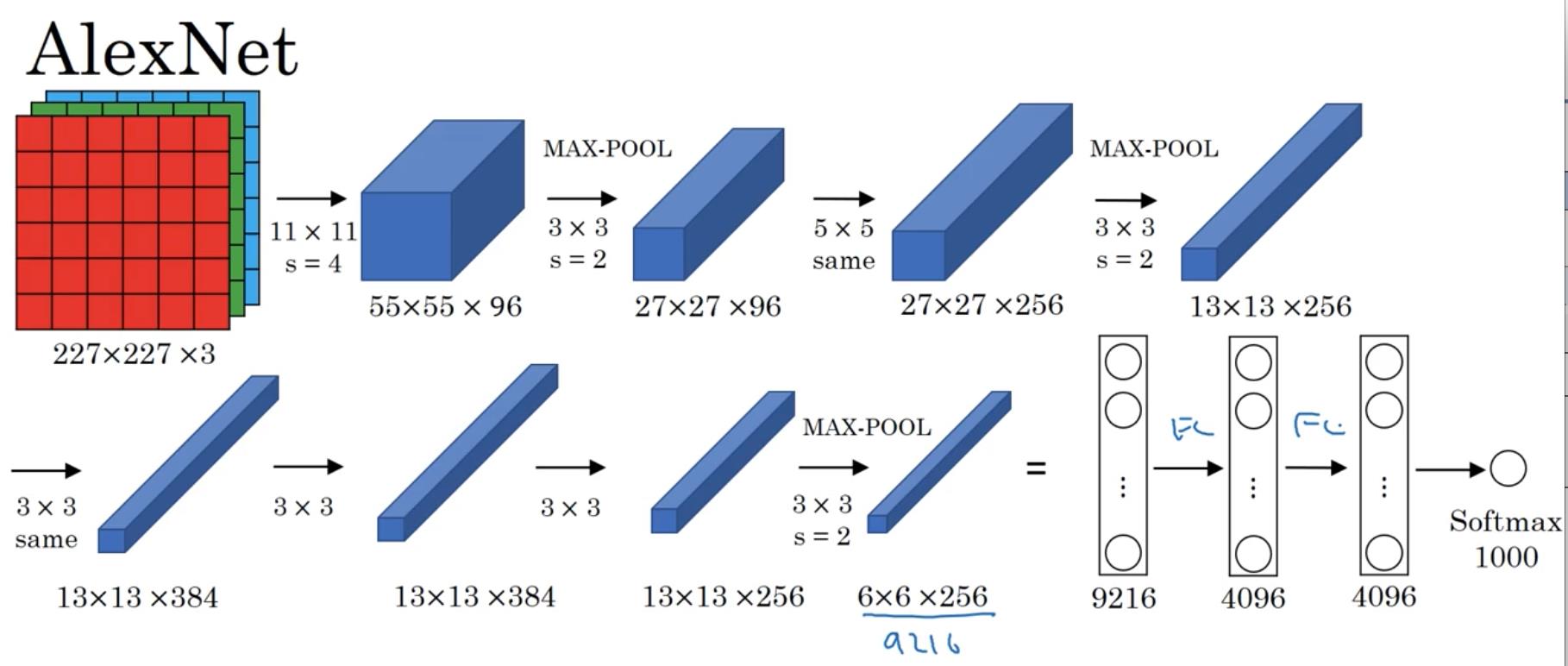
-
VGG
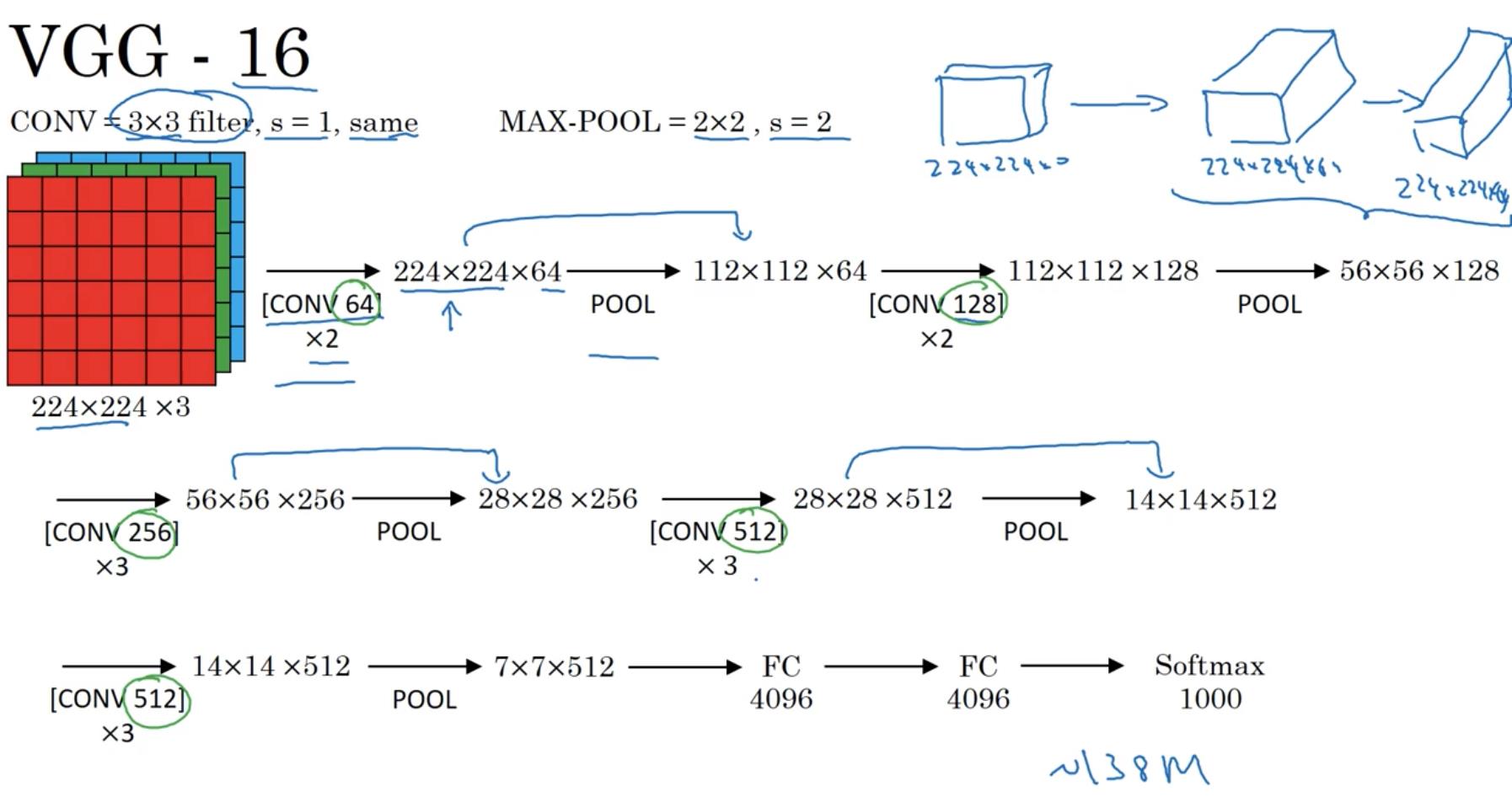
-
Ng介绍了上述三个在计算机视觉中的经典网络。网络深度逐渐增加,训练的参数数量也骤增。AlexNet大约6000万参数,VGG大约上亿参数。
-
从中我们可以学习到:
- 随着网络深度增加,模型的效果能够提升。
- 另外,VGG网络虽然很深,但是其结构比较规整。每经过一次池化层(过滤器大小为2,步长为2),图像的长度和宽度折半;每经过一次卷积层,输出数据的channel数量加倍,即卷积层中过滤器(filter)的数量。
2. 残差网络(ResNet)
-
由于存在梯度消失与梯度爆炸的现象,很难训练非常深的网络,因此引入了 “skip connections ”的概念,它可以从网络中的某一层获取激活值,并将信息传递给更深一层的网络(将输入流合并,点加),残差块可以训练更深的神经网络。
-
残差网络的结构如下:
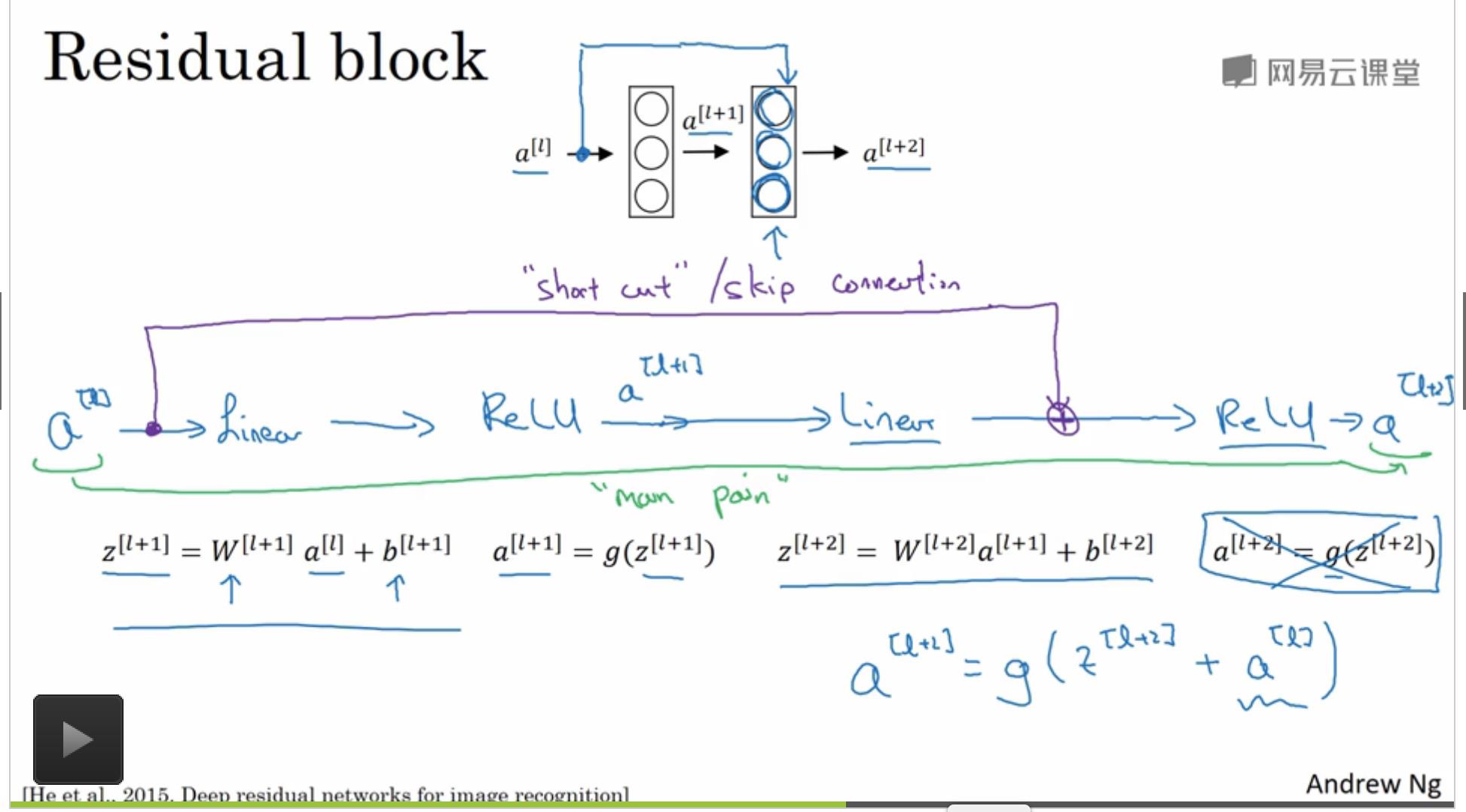
-
更加直观的理解是:
- 残差网络可以尽量避免梯度爆炸或消失的现象;
- 我认为级联相当于对网络加了双层保险,类似于物理中电路的并联,两个输入流只要有一个work,仍能推动网络进行正常的训练。
-
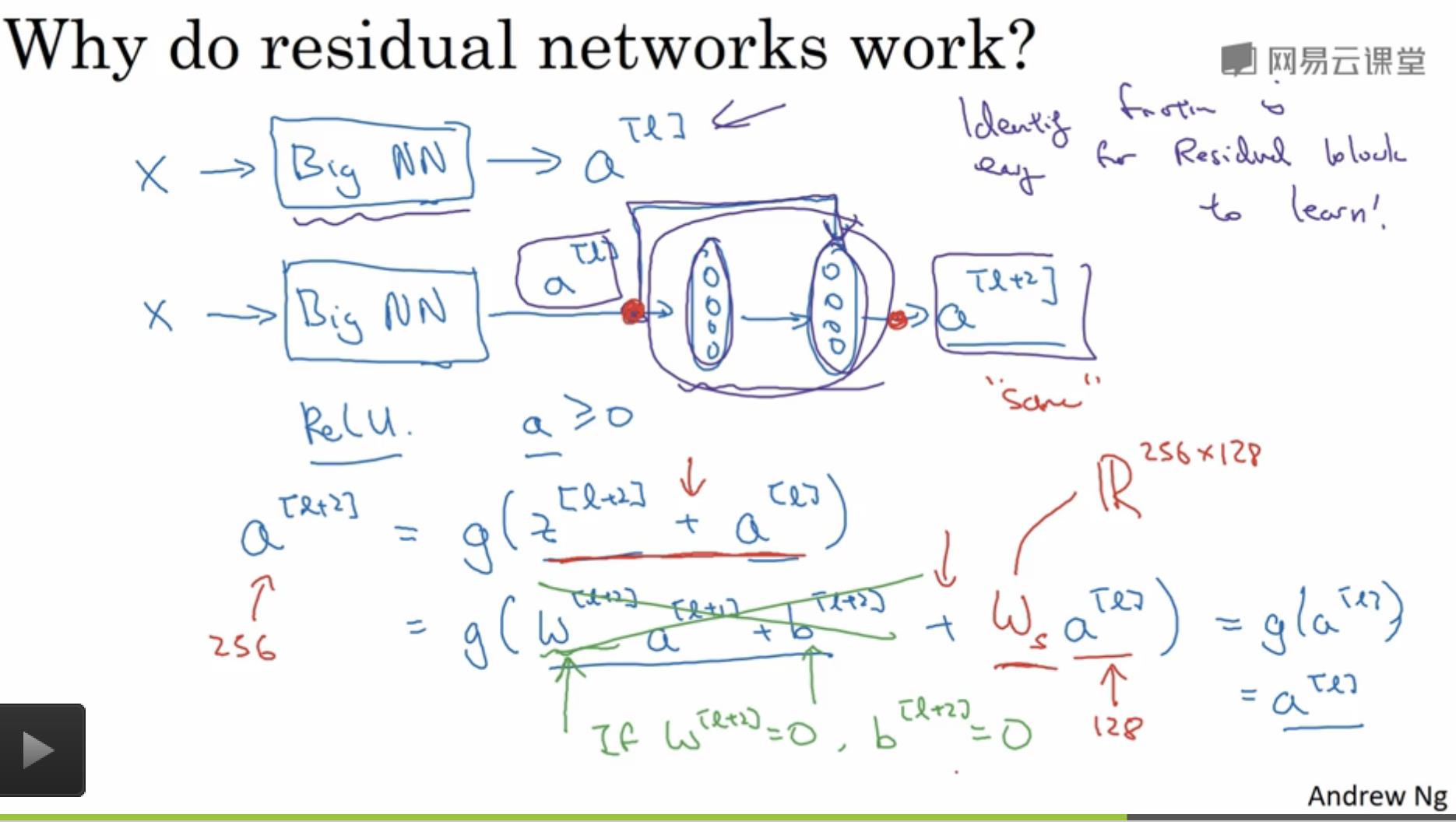
看完上文的描述,可能有人会问,当两个输入流维度不同怎么进行“点加”操作?为了解决上述问题,Ng在课上提到引入一个权重矩阵\\(W_s\\),课堂笔记如下图所示:
-
该矩阵可以作为网络的参数进行训练;也可以是一个固定矩阵,对 “skip connections ”的数据进行zero padding,补齐到相同维度。之后将两个相同维度的数据进行”点加“操作。
3. \\(1\\times 1\\)卷积网络

-
该图对卷积核大小为1的CNN的解释是, 对输入的channel方向上的某一切片的所有数据与过滤器(\\(1\\times 1\\times 32\\))进行点乘再相加的操作,相当于对channel维度上的数据乘以不同的权重。
-
\\(1\\times 1\\)的卷积从根本上可以理解为一个全连接网络,将数据的第三个维度,即channel大小的维度映射为 #filter(过滤器的数量)大小的维度。这种\\(1\\times 1\\)网络也被称之为Network in Network。
-
应用\\(1\\times 1\\)卷积将 \\(28\\times 28\\times 192\\) 维度的数据,压缩为\\(28\\times 28\\times 32\\)维度。这里只是压缩了第三个维度,而池化操作则对前两个维度进行了压缩。具体说明如图所示。

4. Inception
- 当设计卷积网络时,你需要决定过滤器的大小是\\(1\\times 1\\)还是\\(3\\times 3\\),要不要添加池化层等等。而Inception网络的作用就是代替人工来确定卷积层的过滤器类型,是否需要池化层。
Inception 网络的思想如图所示:

- 基本思想是Inception网络可以让网络自己学习他需要什么样的参数:过滤器大小、是否需要池化层。
- 你可以对网络添加这些参数的所有可能值。 比如图中1、3、5的数值。图中网络分别经过3个不同过滤器大小的卷积、1个池化操作,之后将4个输出流进行合并,作为Inception网络的输出。
但是,Inception网络会带来一个问题——计算成本大大提升。下面我们先对上图\\(5\\times 5\\)卷积的计算成本进行计算:
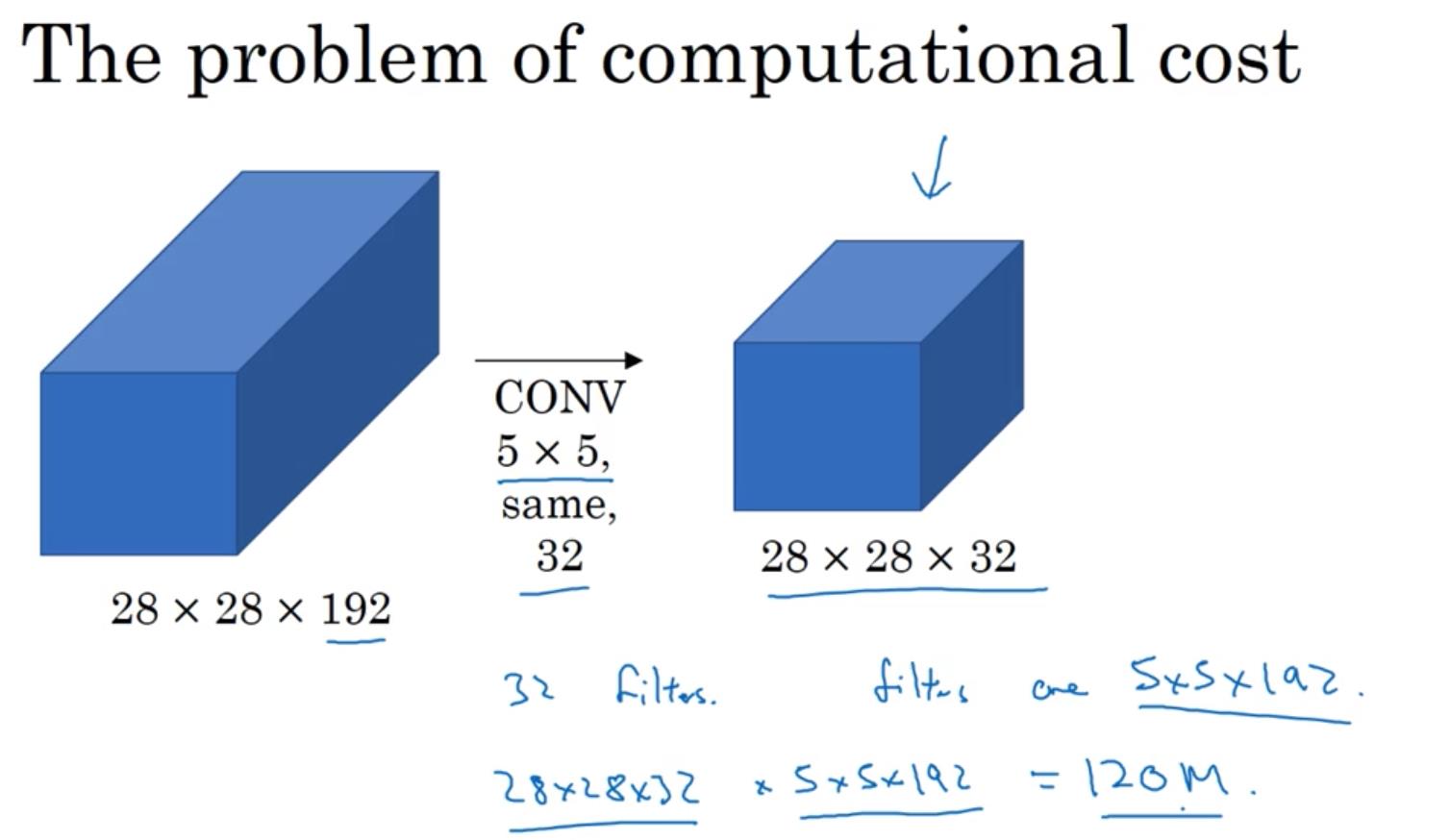
- 图中卷积操作采用了same卷积——使用padding,让卷积不改变图片数据的长和宽(输入数据的前两个维度)大小。该卷积使用了32个过滤器,且过滤器大小为\\(5\\times 5\\times 192\\),这样卷积的最终输出是\\(28\\times 28\\times 32\\)。经过计算,该卷积的计算成本约为1.2亿(乘法次数)。
为了减少计算成本,采用Section 3所讲的\\(1\\times 1\\)卷积,计算过程如下图所示:
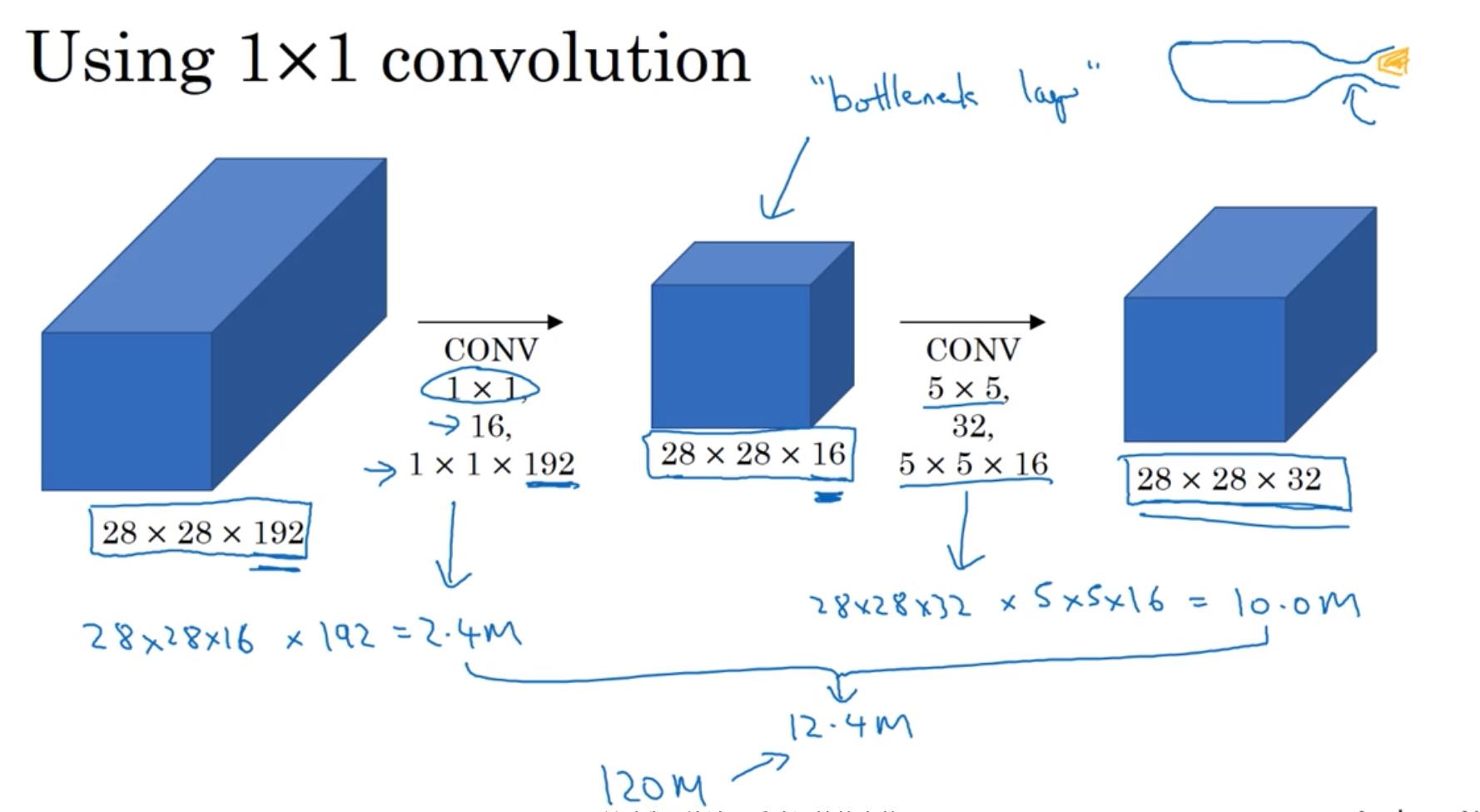
- 图中的\\(1\\times 1\\)维卷积也称为bottleneck layer。由此可见,改进后的网络,计算成本由1.2亿,减少至1.24千万。
总的来说,当我们不知道该设计多大的卷积核大小时,Inception网络是很好的选择。经过实验证明,只要合理构建bottleneck layer,减少计算成本的同时,不会降低网络的性能。
5. Inception 网络具体实现
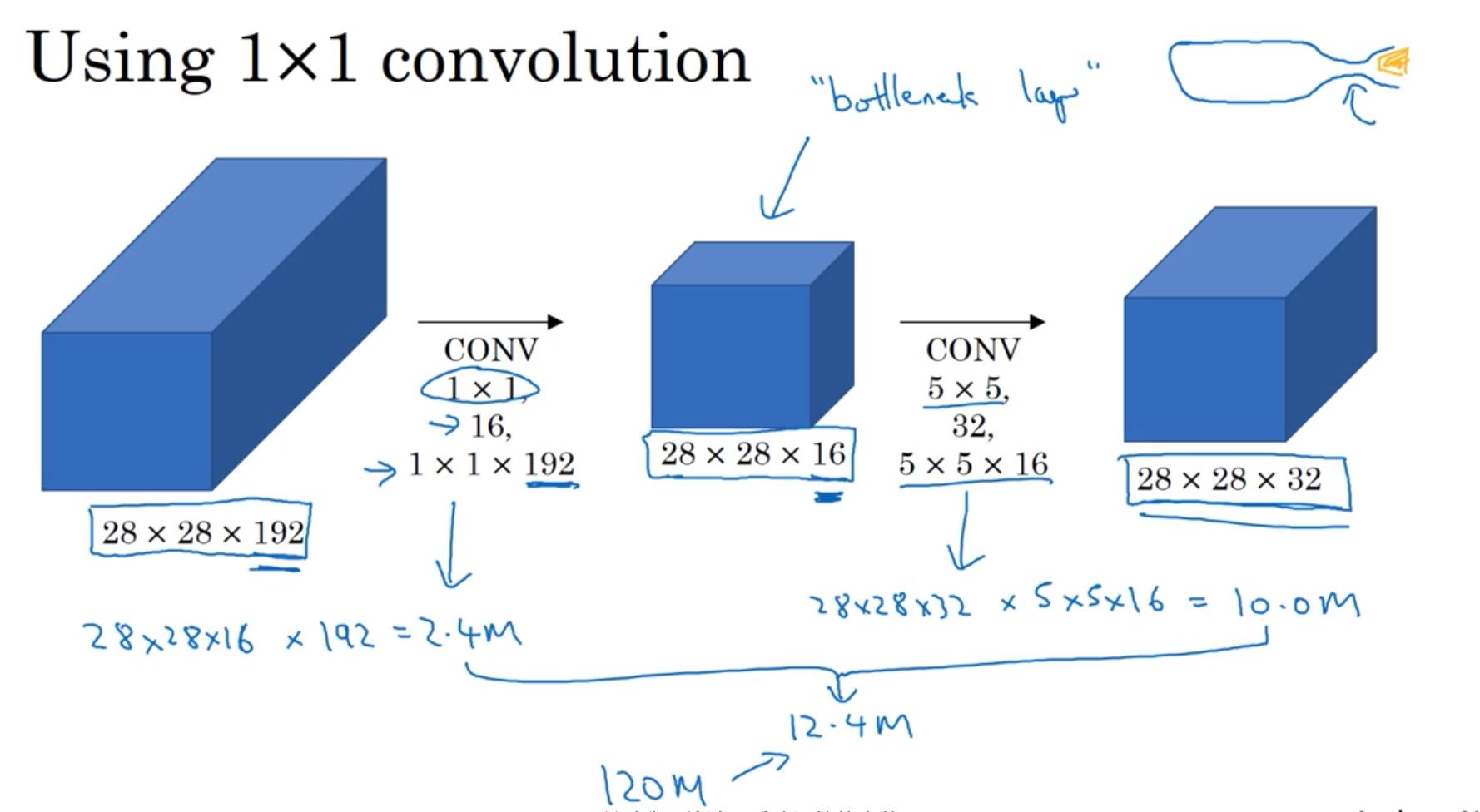
上图介绍了 Inception 模块的实现细节,输入数据(\\(28\\times 28\\times 192\\))分别经过四个处理过程,分别是:
- 64个\\(1\\times 1\\)过滤器(严格来讲,应该是\\(1\\times 1\\times 192\\))。
- 96个\\(1\\times 1\\)过滤器,128个\\(3\\times 3\\)过滤器。
- 16个\\(1\\times 1\\)过滤器,32个\\(5\\times 5\\)过滤器。
- 为了不改变模型的前两个维度大小,这里使用same pooling,过滤器大小为\\(3\\times 3\\)。池化后数据的维度不发生改变,仍然为\\(28\\times 28\\times 192\\),为了避免最终合并的输出大部分被pooling输出填满,又添加了32个\\(1\\times 1\\)过滤器,将channel维度从192压缩至32。
该Inception 模块四个输出分别为\\(28\\times 28\\times 64\\)、\\(28\\times 28\\times 128\\)、\\(28\\times 28\\times 32\\)、\\(28\\times 28\\times 32\\)。合并后输出为\\(28\\times 28\\times 256\\)。
原论文的模型结构如下所示:
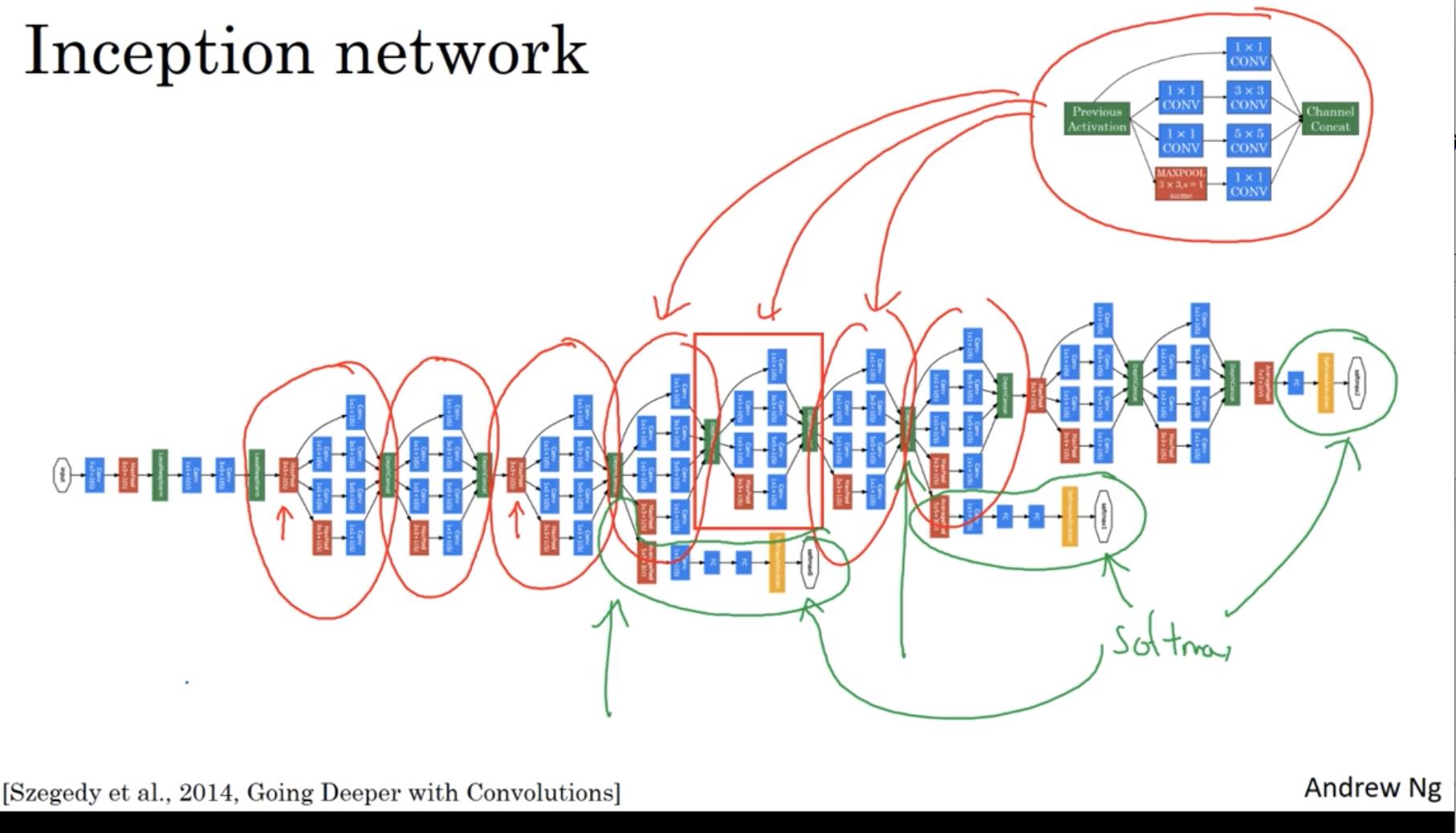
- 该结构看起来很复杂,其实使用很多重复的Inception模块,关于该模块,我们已经进行了非常详细的介绍。
- 原论文中 Inception 网络的一个细节是,他在模型中添加了几个隐藏层、softmax分支。它确保了网络的中间单元也参与了特征计算,并起到了一种调整的效果,能防止网络发生过拟合。
- 另外,在我看来,从某些程度上讲,这样也可以防止梯度消失现象的发生。
感兴趣的同学可以自行阅读发表在CVPR2015上的原始论文Going Deeper with Convolutions。
在这之后又衍生出Inception V2、V3、V4等网络结构,也有与之前提到的skip connections相结合的版本,模型的精度得到了提升。
想了解更多可以参考如下链接:
https://www.zhihu.com/question/50370954/answer/138938524
https://zhuanlan.zhihu.com/p/30756181