浅入浅出数据结构(24)——最短路径问题
Posted 谢维的博客( ̄︶ ̄)
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了浅入浅出数据结构(24)——最短路径问题相关的知识,希望对你有一定的参考价值。
上一篇博文我们提到了图的最短路径问题:两个顶点间的最短路径该如何寻找?其实这个问题不应该叫“最短”路径问题,而应该叫“最便宜”路径问题,因为有时候我们会为图中的边赋权(weight),也叫权重,相当于经过一条边的“代价”,一般为正数。比如下图(边旁的数字即该边的权重)

如果单纯考虑一条路径上边的条数,那么从v0到v6的最短路径应该是:v0-v3-v6。但是如果考虑边的权重,从v0到v6的“最便宜”路径应该是:v0-v1-v4-v6,其总权重为3(路径中所有边的权重之和),而如果走v0-v3-v6的路径,总权重将是11。
边有权重的图我们称之为赋权图,反之称为无权图,赋权图显然可以比无权图应用于更多场合,比如用赋权图来表示城市间公路,权重越大路况越差,或者权重越大,过路费用越高等等。
其实不考虑权重的最短路径问题就是所有边的权重都是1的“最便宜”路径问题,比如将上图的所有边去掉权重后的无权图也可以这样表示:
方便起见,我们就将“最便宜”路径称为最短路径。
接下来让我们先从简单的无权情况开始,看看如何找两个顶点间的最短路径。不过到了这一步,一件有意思的事情需要说明一下,那就是:找X到Y的最短路径,比找X到所有顶点的最短路径更慢(有权无权都是如此)。
出现这个情况的原因我们可以简单的分析一波:找X到Y的最短路径,最直接的做法就是令程序从X出发沿着可行的边不断的走,直到走到Y处为止,但是当走到Y处时,没人能保证刚刚走的那条路就是最短的,除非你走遍了整个图的顶点,换句话说,你要确定走到Y处且走的路径是最短的,你就得走遍所有顶点,而且在这个过程中你必须不断记录各个路径的长度,不然当你发现到一个顶点有多条路径时怎么比较它们呢?所以,你要找X到Y的最短路径,你就得找出X到所有顶点的最短路径。
当然,也存在专门寻找点对点最短路径的思路,但是目前来说,单独找X到Y的最短路径不会比找X到所有顶点的最短路径更快,所以我们接下来探讨的问题其实都是:单源最短路径问题。即给定一个起点(源),求出其与所有顶点的最短路径。有了到所有顶点的最短路径,我们自然也就有了到给定顶点Y的最短路径。
对无权图进行单源最短路径寻找的思路,就是我们上面所说的“最直接的做法”。为了更方便讲解,我们假定若存在边(A,B),则B是被A“指向”的顶点。那么对无权图进行单源最短路径寻找就是这样的:
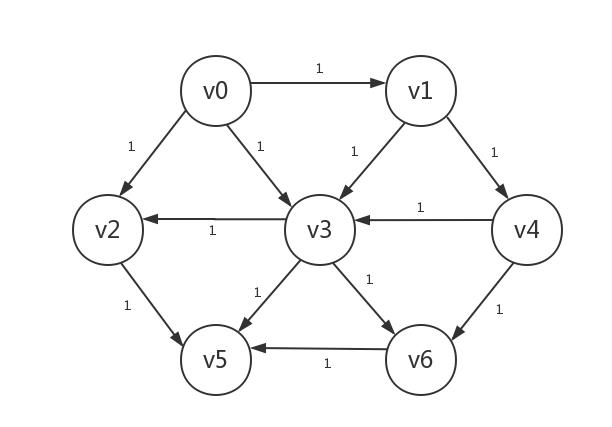
首先,我们将起点的路径长设为0,其他顶点路径长设为负数(也可以是其他不可能的值,图例中用?表示),下例以v1作为起点
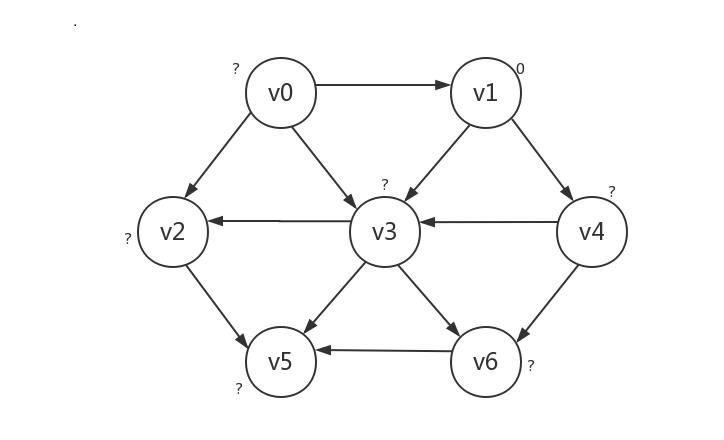
接着我们将起点所指向的顶点的路径长设为1,可以肯定的是,只有被路径长为0的起点所指向的顶点的路径长为1,本例中即v3和v4:
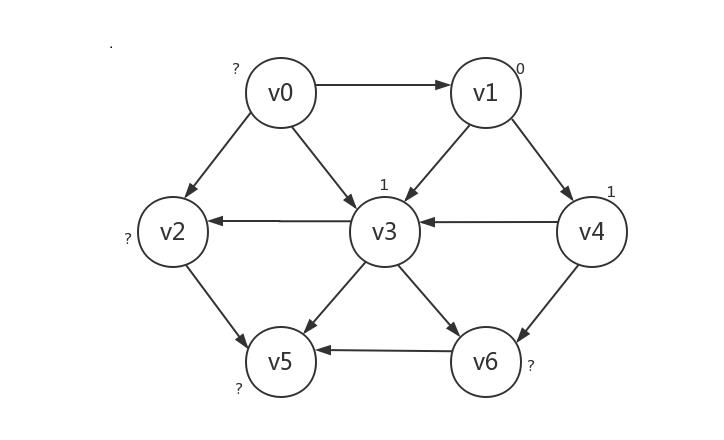
接下来,我们将路径长为1的顶点(v3和v4)所指向的顶点的路径长设为2,同样可以肯定,只有被路径长为1的顶点所指向的顶点的路径长为2。不过此时会遇到一个问题:v3是v4所指向的顶点,但v3的路径长显然不应该被设为2。所以我们需要对已知路径长的顶点设一个“已知”标记,已知的顶点不再更改其路径长,具体做法在给出代码时将写明。本例中,路径长要被设为2的顶点是v2、v5、v6:
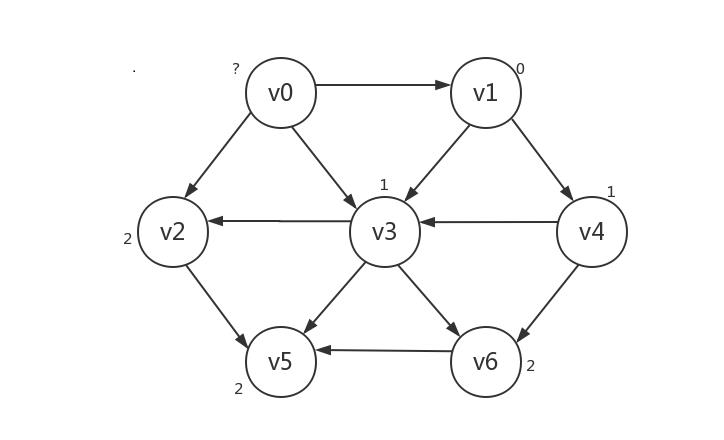
然后我们继续这样的步骤,将路径长为2的顶点所指向的顶点的路径长设为3。不过本例中路径长为2的顶点所指向的顶点中已经没有未知顶点了,所以算法结束。
上述步骤随着图的规模变大而变多,但不难发现其规律就是:将路径长为i的顶点所指向的未知顶点的路径长设为i+1,i从0开始,结束条件即:当前路径长为i的顶点没有指向其它顶点,或所指向的顶点均为已知。
需要注意的是结束条件的说法,我们并没有要求所有顶点都变为已知,因为确定某顶点为起点后,是有可能存在某个顶点无法由起点出发然后到达的,比如我们的例子中的v0,不存在从v1到v0的路径。
接下来要做的事情就是用代码实现我们所说的思路,此时我们需要注意是我们并不想在图上直接动手脚,因为图可能还有他用,并且直接在图上动手脚也不方便,因为图中顶点可能并没有用于表示是否已知的域和用于表示从起点到自身的最短路径长的域。
所以我们的做法是将最短路径的计算结果存于一个线性表中,其结构如下:

其中“一行”为线性表中的一个元素,每一行的四个单元格就是一个元素中的四个域:顶点、是否已知、与起点最短路径长、最短路径中自身的前一个顶点。
那么之前计算最短路径的过程用这个表来表示的话,就是下面这样:
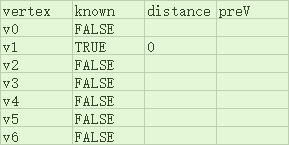
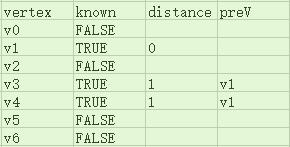
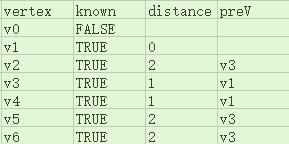
当我们想知道从起点到顶点Y的最短路径时,我们只需要找到Y顶点,查看其distance域即可知道,而想知道整条路径是怎么走的,我们也只要追溯Y的preV直到起点即可知道。下面是输出起点到给定终点的最短路径的一个例子:
//路径表中的元素定义,我们假设顶点vx即数字x,所以元素没有vertex域 struct pathNode { bool known; int distance; size_t preV; } //路径表 struct pathNode pathTable[numVertex];
void printPath(size_t end,struct node* pathTable) { size_t preV=pathTable[end].preV; if(pathTable[preV].distance!=0) printPath(preV,pathTable); else printf("%d",preV); printf("->"); printf("%d",end); }
下面是上述无权最短路径思路的一个简单伪代码实现:
//无权最短路径计算,图存于邻接表graph,结果存入pathTable,起点即start void unweightedPath(Node* graph,struct pathNode* pathTable,size_t start) { pathTable[start].known=true; pathTable[start].distance=0; //若pathTable[x].distance为0,则其preV是无用的,我们不予理睬 //初始化pathTable中的其他元素 //curDis即当前距离,我们要做的是令distance==curDis的顶点所指的未知顶点的distance=curDis+1 for(int curDis=0;curDis<numVertex;++curDis) { for(int i=0;i<numVertex;++i) { if(!pathTable[i].known&&pathTable[i].distance==curDis) { pathTable[i].known=true; //遍历pathTable[i]所指向的顶点X { if(!pathTable[X].known) { pathTable[X].preV=i; pathTable[X].distance=curDis+1; } } } } } }
与上一篇博文的拓扑排序一样,上面的最短路径算法还有改进空间。当我们寻找符合distance==curDis条件的顶点时,我们用的是直接遍历数组的方法,这使得我们的算法时间复杂度达到了O(nv2)(nv为顶点个数),所以我们要改进的就是“寻找符合条件的顶点”的过程。我们可以创建一个队列来存储“需要处理的顶点”,该队列初始时只有起点,当我们修改了某个未知顶点的distance后,我们就将该顶点入队,而当我们令curDis递增后再次寻找distance==curDis的顶点时,我们只需要令队列元素出队即可获取到想要的顶点。这个过程口述难以表达清楚,下面是应该足够清晰了的伪代码:
//无权最短路径计算,图存于邻接表graph,结果存入pathTable,起点即start void unweightedPath(Node* graph,struct pathNode* pathTable,size_t start) { //初始化pathTable //创建队列pendingQueue //将起点start入队 size_t curVertex;while(!empty(pendingQueue)) { curVertex=Dequeue(pendingQueue); pathTable[curVertex].known=true; //遍历curVertex指向的顶点X { if(!pathTable[X].known) { pathTable[X].distance=pathTable[curVertex].distance+1; pathTable[X].preV=curVertex; Enqueue(X,pendingQueue); } } } }
这样一来,我们就将无权最短路径算法的时间复杂度由O(nv2)降低到了O(nv+ne)(ne即边的条数)。此外,上述算法对于无向有圈图也是一样生效的,原因就不赘述了,道理是简单的。
接下来的问题是如何对有权图进行单源最短路径的寻找。有权图的最短路径显然比无权图要难找,原因在于我们不能套用无权算法的思路,直接令已知顶点所指未知顶点的distance=curDis+weight(weight即两顶点间路径的权重,此处简写),以下图为例:
若我们令v0作为起点,然后令v0所指的未知顶点的distance=v0.distance+weight,那么v3的distance就会变成5,可是实际上v3的distance应改为2。
解决的思路是:我们罗列出所有已知顶点指向的所有未知顶点,看这些未知顶点中谁的distance被修改后会是最小的,最小的那个我们就修改其distance,并认为它已知。
以上图为例,我们一步步走一遍来加深一下理解:
首先是正常的初始化(我们将边的权重也标识出来),假设起点为v0:
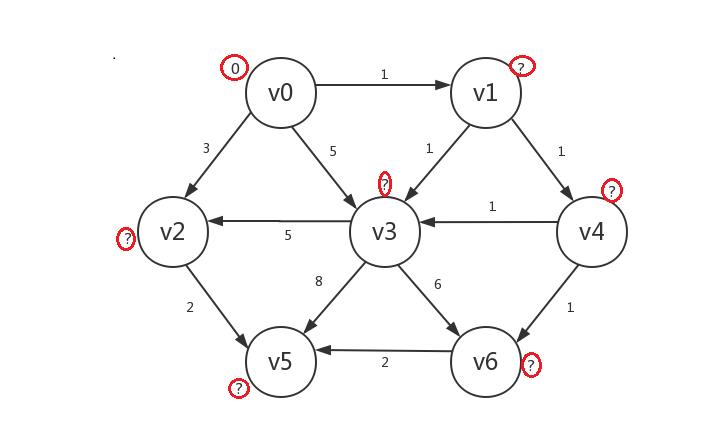
接着我们罗列出所有已知顶点(只有v0)指向的所有未知顶点:v1、v2、v3。然后发现若修改它们的distance,则v1.distance=v0.distance+1=1,v2.distance=v0.distance+3=3,v3.distance=v0.distance+5=5。显然v1被修改后的distance是未知顶点中最小的,所以我们只修改v1的distance,并将v1设为已知,v2、v3不动:
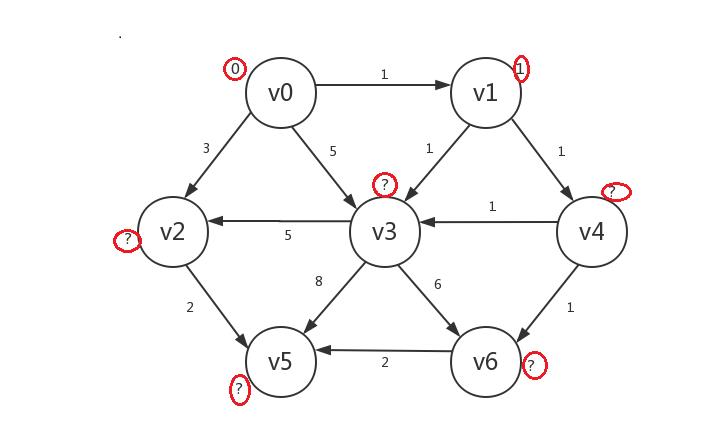
接着我们继续罗列出所有已知顶点(v0、v1)指向的所有未知顶点:v2、v3、v4。然后发现若修改它们的distance,则v2.distance=v0.distance+3=3,v4.distance=v1.distance+1=2,v3.distance=v1.distance+1=2(虽然v0也指向v3,但是通过v0到v3的路径长大于从v1到v3,所以v3的distance取其小者),其中v3和v4的新distance并列最小,我们任选其一比如v4,然后只修改v4的distance,并将v4设为已知,其它不动:
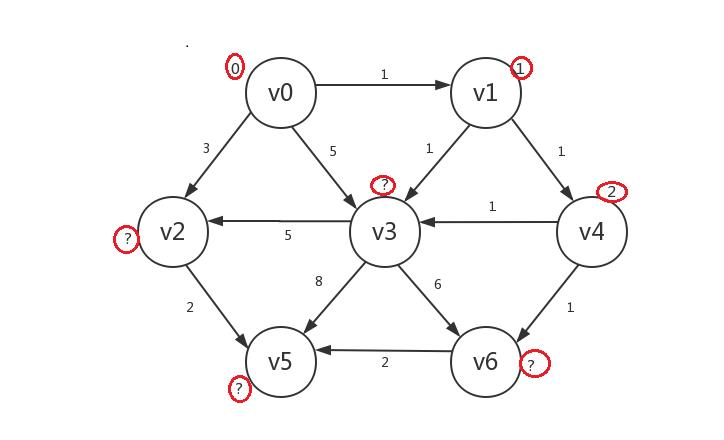
继续,我们罗列出所有已知顶点(v0、v1、v4)指向的所有未知顶点:v2、v3、v6,发现若修改,则v2.distance=3,v3.distance=2,v6.distance=3,所以我们只修改v3的distance,并将v3设为已知:
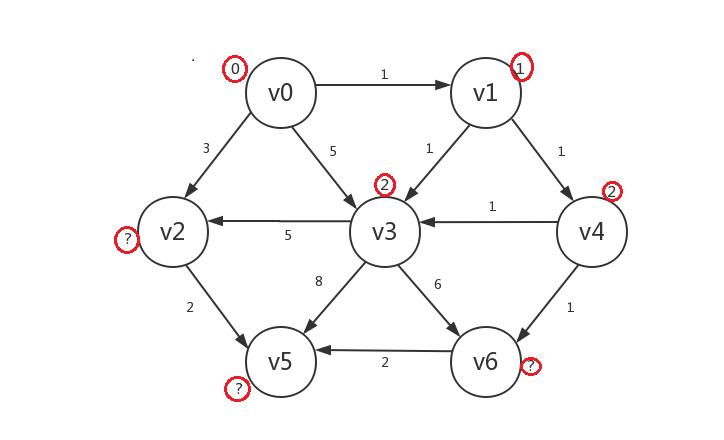
继续,我们罗列出所有已知顶点(v0、v1、v3、v4)指向的所有未知顶点:v2、v5、v6,发现若修改,则v2.distance=3,v5.distance=10,v6.distance=3,我们在v2和v6中任选一个如v2,只修改v2.distance,并将v2设为已知:

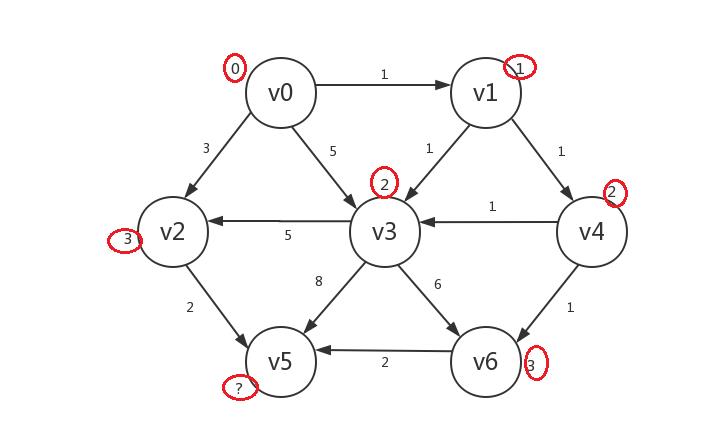
继续,我们罗列出所有已知顶点指向的所有未知顶点:v5、v6,发现若修改,则v5.distance=5,v6.distance=3,所以我们只修改v6:
最后,罗列出的未知顶点只有v5,若修改,其distance=5,我们将其修改并设为已知,算法结束:
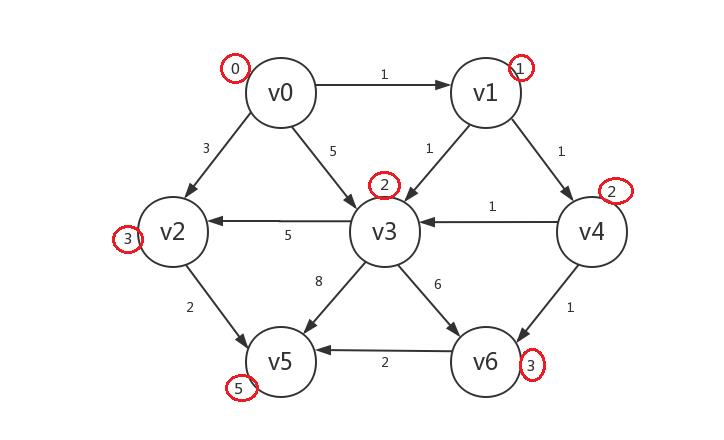
其实上述算法的核心部分就是:
1.找到所有已知顶点
2.将所有已知顶点指向的所有未知顶点罗列出来
3.计算这些未知顶点的最小distance,然后再确定其中新distance最小的顶点X
4.只修改X的distance,并将X设为已知
5.回到第二步,若所有已知顶点都没有指向未知顶点,则结束
而这个算法就是Dijkstra算法的雏形。
Dijkstra算法核心部分简化的说法就是:找到所有可确定distance的未知顶点中新distance最小的那个,修改它并将它设为已知。
用伪代码描述就是这样:
//有权最短路径计算,图存于邻接表graph,结果存入pathTable,起点即start void weightedPath(Node* graph,struct pathNode* pathTable,size_t start) { //初始化pathNode数组 size_t curV; while(true) { //找到可确定distance的未知顶点中新distance最小的那个,存入curV,若没有则跳出循环 //令pathNode[curV].distance和pathNode[curV].prev修改为正确的值 pathNode[curV].known=true; } }
可以确定的是,Dijkstra算法也可以应用于无权图,只要给无权图中的每条边加个值为1的权重即可。并且如果你将无权算法与Dijkstra算法进行对比,就会发现那个无权算法其实就是Dijkstra算法的“特例”,在无权算法中,我们之所以不需要去找“distance最小的未知顶点”,是因为我们可以肯定已知顶点所指向的未知顶点就是“distance最小的未知顶点”。
不用想都知道,Dijkstra算法中的循环中的两行伪代码其实意味着大量的操作:找到可以确定distance的未知顶点,计算它们的distance,比较出最小的那个,修改……
显然,Dijkstra算法的核心部分是可以改进的,改进的思路与无权算法也很相像,即“加快寻找符合条件的顶点的过程”。其中一种改进方式是计算出未知顶点的新distance后,将{未知顶点,新distance}对插入到以distance为关键字的优先队列中,而不是直接抛弃非最小distance的那些未知顶点(这是一个很大的浪费)。这样在下一次寻找“distance最小的未知顶点”时,我们可以通过优先队列的出队来获得,从而避免了遍历整个数组来寻找目标的情况。这个想法要细化实现的话,还有不少坑要避开,不过我写到这儿时深感表达之困难与疲惫,所以这篇博文就此打住,如果博文中有什么不对之处,可以在评论区指出,谢谢~
附:如果有权图中存在权重为负值的情况,则计算单源最短路径将会更加困难,不过可以确定的是,如果有权图中存在圈与负权边,且负权边在圈中,使得圈的路径长为负,那么单源最短路径的计算是无法进行的,因为你可以在这个圈中永远走下去来使路径长不断“减小”。解决有负值权重边的图的最短路径算法是在Dijkstra的算法上进行改进得来的,本文不予讲解(或许以后会有一篇文章介绍),有兴趣的可以自行搜索。
以上是关于浅入浅出数据结构(24)——最短路径问题的主要内容,如果未能解决你的问题,请参考以下文章