Spark篇---SparkStreaming算子操作transform和updateStateByKey
Posted L先生AI课堂
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark篇---SparkStreaming算子操作transform和updateStateByKey相关的知识,希望对你有一定的参考价值。
一、前述
今天分享一篇SparkStreaming常用的算子transform和updateStateByKey。
- 可以通过transform算子,对Dstream做RDD到RDD的任意操作。其实就是DStream的类型转换。
算子内,拿到的RDD算子外,代码是在Driver端执行的,每个batchInterval执行一次,可以做到动态改变广播变量。
-
为SparkStreaming中每一个Key维护一份state状态,通过更新函数对该key的状态不断更新。
二、具体细节
1、transform 是一个transformation类算子
package com.spark.sparkstreaming; import java.util.ArrayList; import java.util.List; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaPairRDD; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.function.Function; import org.apache.spark.api.java.function.PairFunction; import org.apache.spark.api.java.function.VoidFunction; import org.apache.spark.streaming.Durations; import org.apache.spark.streaming.api.java.JavaDStream; import org.apache.spark.streaming.api.java.JavaPairDStream; import org.apache.spark.streaming.api.java.JavaReceiverInputDStream; import org.apache.spark.streaming.api.java.JavaStreamingContext; import com.google.common.base.Optional; import scala.Tuple2; /** * 过滤黑名单 * transform操作 * DStream可以通过transform做RDD到RDD的任意操作。 * @author root * */ public class TransformOperator { public static void main(String[] args) { SparkConf conf = new SparkConf(); conf.setMaster("local[2]").setAppName("transform"); JavaStreamingContext jsc = new JavaStreamingContext(conf,Durations.seconds(5)); //模拟黑名单 List<Tuple2<String,Boolean>> blackList = new ArrayList<Tuple2<String,Boolean>>(); blackList.add(new Tuple2<String,Boolean>("zhangsan",true)); //将黑名单转换成RDD final JavaPairRDD<String, Boolean> blackNameRDD = jsc.sparkContext().parallelizePairs(blackList); //接受socket数据源 JavaReceiverInputDStream<String> nameList = jsc.socketTextStream("node5", 9999); JavaPairDStream<String, String> pairNameList = nameList.mapToPair(new PairFunction<String, String, String>() { /** *这块代码在Driver端执行。 */ private static final long serialVersionUID = 1L; @Override public Tuple2<String, String> call(String s) throws Exception { return new Tuple2<String, String>(s.split(" ")[1], s); } }); JavaDStream<String> transFormResult = pairNameList.transform(new Function<JavaPairRDD<String,String>, JavaRDD<String>>() { /** * */ private static final long serialVersionUID = 1L; @Override public JavaRDD<String> call(JavaPairRDD<String, String> nameRDD) throws Exception { /** * nameRDD: * ("zhangsan","1 zhangsan") * ("lisi","2 lisi") * ("wangwu","3 wangwu") * blackNameRDD: * ("zhangsan",true) * * ("zhangsan",("1 zhangsan",[true])) * */ JavaPairRDD<String, Tuple2<String, Optional<Boolean>>> leftOuterJoin = nameRDD.leftOuterJoin(blackNameRDD); //打印下leftOuterJoin /*leftOuterJoin.foreach(new VoidFunction<Tuple2<String,Tuple2<String,Optional<Boolean>>>>() { *//** * *//* private static final long serialVersionUID = 1L; @Override public void call(Tuple2<String, Tuple2<String, Optional<Boolean>>> t) throws Exception { System.out.println(t); } });*/ //过滤:true的留下,false的过滤 //("zhangsan",("1 zhangsan",[true])) JavaPairRDD<String, Tuple2<String, Optional<Boolean>>> filter = leftOuterJoin.filter(new Function<Tuple2<String,Tuple2<String,Optional<Boolean>>>, Boolean>() { /** * */ private static final long serialVersionUID = 1L; @Override public Boolean call(Tuple2<String, Tuple2<String, Optional<Boolean>>> tuple)throws Exception { if(tuple._2._2.isPresent()){ return !tuple._2._2.get(); } return true; } }); JavaRDD<String> resultJavaRDD = filter.map(new Function<Tuple2<String,Tuple2<String,Optional<Boolean>>>, String>() { /** * */ private static final long serialVersionUID = 1L; @Override public String call( Tuple2<String, Tuple2<String, Optional<Boolean>>> tuple) throws Exception { return tuple._2._1; } }); //返回过滤好的结果 return resultJavaRDD; } }); transFormResult.print(); jsc.start(); jsc.awaitTermination(); jsc.stop(); } }
2、UpdateStateByKey算子(相当于对不同批次的累加和更新)
UpdateStateByKey的主要功能:
* 1、为Spark Streaming中每一个Key维护一份state状态,state类型可以是任意类型的, 可以是一个自定义的对象,那么更新函数也可以是自定义的。
* 2、通过更新函数对该key的状态不断更新,对于每个新的batch而言,Spark Streaming会在使用updateStateByKey的时候为已经存在的key进行state的状态更新
* 使用到updateStateByKey要开启checkpoint机制和功能。
* 多久会将内存中的数据写入到磁盘一份?
如果batchInterval设置的时间小于10秒,那么10秒写入磁盘一份。如果batchInterval设置的时间大于10秒,那么就会batchInterval时间间隔写入磁盘一份。
java代码:
package com.spark.sparkstreaming; import java.util.Arrays; import java.util.List; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.FlatMapFunction; import org.apache.spark.api.java.function.Function2; import org.apache.spark.api.java.function.PairFunction; import org.apache.spark.streaming.Durations; import org.apache.spark.streaming.api.java.JavaDStream; import org.apache.spark.streaming.api.java.JavaPairDStream; import org.apache.spark.streaming.api.java.JavaReceiverInputDStream; import org.apache.spark.streaming.api.java.JavaStreamingContext; import com.google.common.base.Optional; import scala.Tuple2; /** * UpdateStateByKey的主要功能: * 1、为Spark Streaming中每一个Key维护一份state状态,state类型可以是任意类型的, 可以是一个自定义的对象,那么更新函数也可以是自定义的。 * 2、通过更新函数对该key的状态不断更新,对于每个新的batch而言,Spark Streaming会在使用updateStateByKey的时候为已经存在的key进行state的状态更新 * * hello,3 * spark,2 * * 如果要不断的更新每个key的state,就一定涉及到了状态的保存和容错,这个时候就需要开启checkpoint机制和功能 * * 全面的广告点击分析 * @author root * * 有何用? 统计广告点击流量,统计这一天的车流量,统计点击量 */ public class UpdateStateByKeyOperator { public static void main(String[] args) { SparkConf conf = new SparkConf().setMaster("local[2]").setAppName("UpdateStateByKeyDemo"); JavaStreamingContext jsc = new JavaStreamingContext(conf, Durations.seconds(5)); /** * 设置checkpoint目录 * * 多久会将内存中的数据(每一个key所对应的状态)写入到磁盘上一份呢? * 如果你的batch interval小于10s 那么10s会将内存中的数据写入到磁盘一份 * 如果bacth interval 大于10s,那么就以bacth interval为准 * * 这样做是为了防止频繁的写HDFS */ JavaSparkContext sparkContext = jsc.sparkContext(); sparkContext.setCheckpointDir("./checkpoint"); // jsc.checkpoint("hdfs://node1:9000/spark/checkpoint"); // jsc.checkpoint("./checkpoint"); JavaReceiverInputDStream<String> lines = jsc.socketTextStream("node5", 9999); JavaDStream<String> words = lines.flatMap(new FlatMapFunction<String, String>() { /** * */ private static final long serialVersionUID = 1L; @Override public Iterable<String> call(String s) { return Arrays.asList(s.split(" ")); } }); JavaPairDStream<String, Integer> ones = words.mapToPair(new PairFunction<String, String, Integer>() { /** * */ private static final long serialVersionUID = 1L; @Override public Tuple2<String, Integer> call(String s) { return new Tuple2<String, Integer>(s, 1); } }); JavaPairDStream<String, Integer> counts = ones.updateStateByKey(new Function2<List<Integer>, Optional<Integer>, Optional<Integer>>() { /** * */ private static final long serialVersionUID = 1L; @Override public Optional<Integer> call(List<Integer> values, Optional<Integer> state) throws Exception { /** * values:经过分组最后 这个key所对应的value [1,1,1,1,1] * state:这个key在本次之前之前的状态 */ Integer updateValue = 0 ; if(state.isPresent()){ updateValue = state.get(); } for (Integer value : values) { updateValue += value; } return Optional.of(updateValue); } });
//output operator counts.print(); jsc.start(); jsc.awaitTermination(); jsc.close(); } }
scala代码:
package com.bjsxt.sparkstreaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.Durations
import org.apache.spark.streaming.StreamingContext
object Operator_UpdateStateByKey {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local[2]").setAppName("updateStateByKey")
val jsc = new StreamingContext(conf,Durations.seconds(5))
//设置日志级别
jsc.sparkContext.setLogLevel("WARN")
//设置checkpoint路径
jsc.checkpoint("hdfs://node1:9000/spark/checkpoint")
val lineDStream = jsc.socketTextStream("node5", 9999)
val wordDStream = lineDStream.flatMap { _.split(" ") }
val pairDStream = wordDStream.map { (_,1)}
val result = pairDStream.updateStateByKey((seq:Seq[Int],option:Option[Int])=>{
var value = 0
value += option.getOrElse(0)
for(elem <- seq){
value +=elem
}
Option(value)
})
result.print()
jsc.start()
jsc.awaitTermination()
jsc.stop()
}
}
结果:

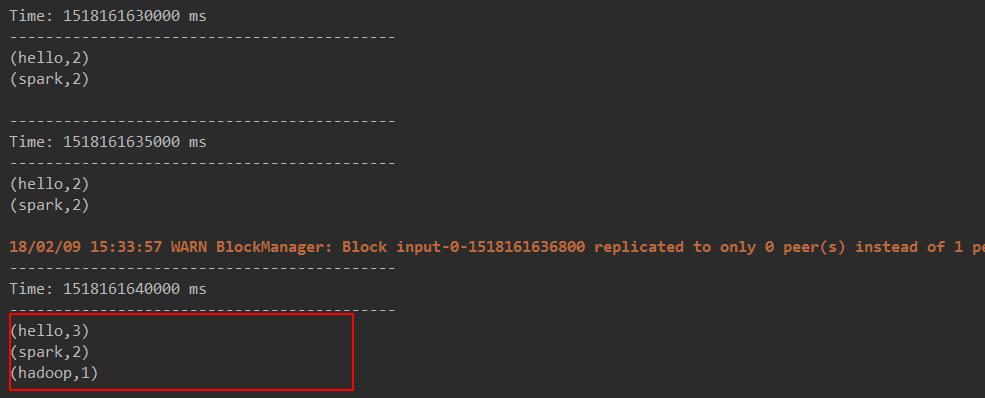
可见从启动以来一直维护这个累加状态!!!
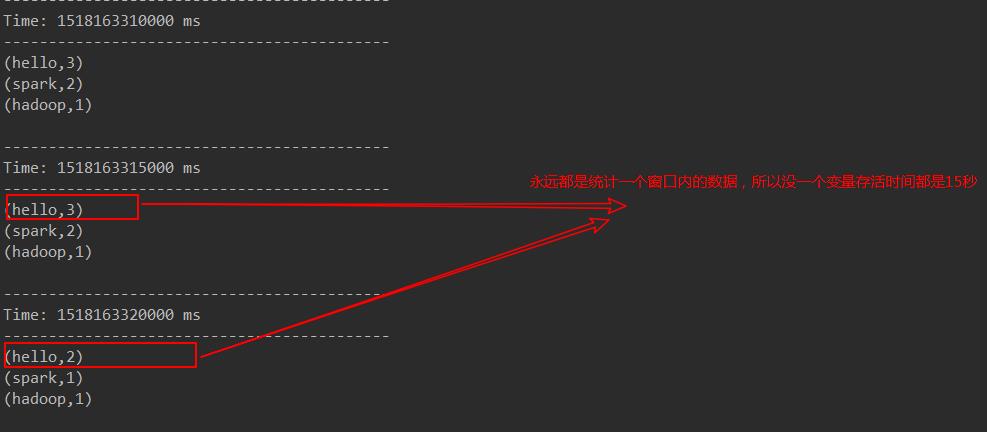
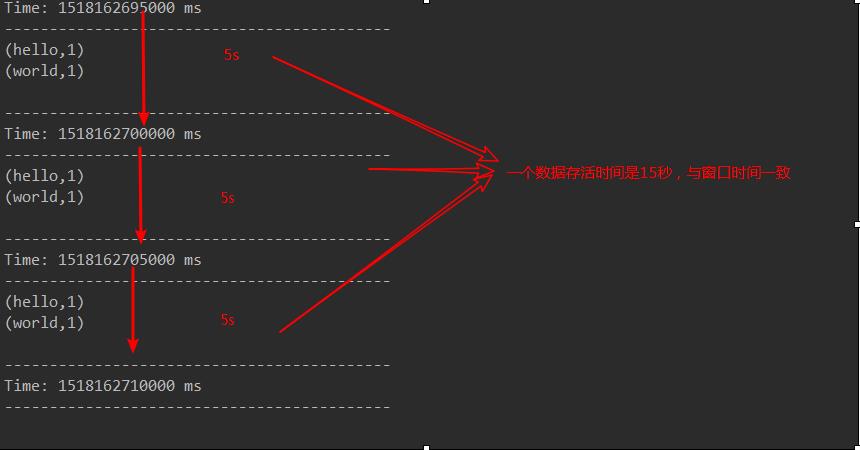
2、windows窗口函数(实现一阶段内的累加 ,而不是程序启动时)

假设每隔5s 1个batch,上图中窗口长度为15s,窗口滑动间隔10s。
窗口长度和滑动间隔必须是batchInterval的整数倍。如果不是整数倍会检测报错。
优化后的window操作要保存状态所以要设置checkpoint路径,没有优化的window操作可以不设置checkpoint路径。
package com.spark.sparkstreaming; import java.util.Arrays; import org.apache.spark.SparkConf; import org.apache.spark.api.java.function.FlatMapFunction; import org.apache.spark.api.java.function.Function2; import org.apache.spark.api.java.function.PairFunction; import org.apache.spark.streaming.Durations; import org.apache.spark.streaming.api.java.JavaDStream; import org.apache.spark.streaming.api.java.JavaPairDStream; import org.apache.spark.streaming.api.java.JavaReceiverInputDStream; import org.apache.spark.streaming.api.java.JavaStreamingContext; import scala.Tuple2; /** * 基于滑动窗口的热点搜索词实时统计 * @author root * */ public class WindowOperator { public static void main(String[] args) { SparkConf conf = new SparkConf() .setMaster("local[2]") .setAppName("WindowHotWord"); JavaStreamingContext jssc = new JavaStreamingContext(conf, Durations.seconds(5)); /** * 设置日志级别为WARN * */ jssc.sparkContext().setLogLevel("WARN"); /** * 注意: * 没有优化的窗口函数可以不设置checkpoint目录 * 优化的窗口函数必须设置checkpoint目录 */ // jssc.checkpoint("hdfs://node1:9000/spark/checkpoint"); jssc.checkpoint("./checkpoint"); JavaReceiverInputDStream<String> searchLogsDStream = jssc.socketTextStream("node04", 9999); //word 1 JavaDStream<String> searchWordsDStream = searchLogsDStream.flatMap(new FlatMapFunction<String, String>() { /** * */ private static final long serialVersionUID = 1L; @Override public Iterable<String> call(String t) throws Exception { return Arrays.asList(t.split(" ")); } }); // 将搜索词映射为(searchWord, 1)的tuple格式 JavaPairDStream<String, Integer> searchWordPairDStream = searchWordsDStream.mapToPair( new PairFunction<String, String, Integer>() { private static final long serialVersionUID = 1L; @Override public Tuple2<String, Integer> call(String searchWord) throws Exception { return new Tuple2<String, Integer>(searchWord, 1); } }); /** * 每隔10秒,计算最近60秒内的数据,那么这个窗口大小就是60秒,里面有12个rdd,在没有计算之前,这些rdd是不会进行计算的。 * 那么在计算的时候会将这12个rdd聚合起来,然后一起执行reduceByKeyAndWindow操作 , * reduceByKeyAndWindow是针对窗口操作的而不是针对DStream操作的。 */ JavaPairDStream<String, Integer> searchWordCountsDStream = searchWordPairDStream.reduceByKeyAndWindow(new Function2<Integer, Integer, Integer>() { private static final long serialVersionUID = 1L; @Override public Integer call(Integer v1, Integer v2) throws Exception { return v1 + v2; } }, Durations.seconds(15), Durations.seconds(5)); //窗口长度,滑动间隔 /** * window窗口操作优化:不用设置checkpoint目录。 */ // JavaPairDStream<String, Integer> searchWordCountsDStream = // // searchWordPairDStream.reduceByKeyAndWindow(new Function2<Integer, Integer, Integer>() { // // private static final long serialVersionUID = 1L; // // @Override // public Integer call(Integer v1, Integer v2) throws Exception { // return v1 + v2; // } // // },new Function2<Integer, Integer, Integer>() { // // private static final long serialVersionUID = 1L; // // @Override // public Integer call(Integer v1, Integer v2) throws Exception { // return v1 - v2; // } // // }, Durations.seconds(15), Durations.seconds(5)); searchWordCountsDStream.print(); jssc.start(); jssc.awaitTermination(); jssc.close(); } }
Scala代码:
package com.bjsxt.sparkstreaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.Durations
import org.apache.spark.streaming.StreamingContext
object Operator_Window {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local[2]").setAppName("updateStateByKey")
val jsc = new StreamingContext(conf,Durations.seconds(5))
//设置日志级别
jsc.sparkContext.setLogLevel("WARN")
//设置checkpoint路径
jsc.checkpoint("hdfs://node1:9000/spark/checkpoint")
val lineDStream = jsc.socketTextStream("node04", 9999)
val wordDStream = lineDStream.flatMap { _.split(" ") }
val mapDStream = wordDStream.map { (_,1)}
//window没有优化后的
val result = mapDStream.reduceByKeyAndWindow((v1:Int,v2:Int)=>{
v1+v2
}, Durations.seconds(60), Durations.seconds(10))
//优化后的
// val result = mapDStream.reduceByKeyAndWindow((v1:Int,v2:Int)=>{
// v1+v2
// }, (v1:Int,v2:Int)=>{
// v1-v2
// }, Durations.seconds(60), Durations.seconds(10))
result.print()
jsc.start()
jsc.awaitTermination()
jsc.stop()
}
}
结果:
以上是关于Spark篇---SparkStreaming算子操作transform和updateStateByKey的主要内容,如果未能解决你的问题,请参考以下文章