深入浅出高可靠性技术
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入浅出高可靠性技术相关的知识,希望对你有一定的参考价值。
一. 高可靠性技术概述
· 可靠性:Availability,可靠性=MTBF/ (MTBF+MTTR):
○ MTBF(Mean Time Between Failure:平均无故障时间):衡量稳定程度
○ MTTR(Mean Time to Repair:故障平均修复时间):衡量故障响应修复速度
· 高可靠性的应用:
○ 网络高可靠性主要是指当设备或网络出现故障时,网络提供服务的不间断性。
1.可靠性达到5 个9 以上;
2.可靠性99.999%意味着每年故障时间不超过5 分钟;
3.可靠性99.9999%意味着每年故障时间不超过30 秒。
○ 园区网高可靠性技术:
1.链路备份技术;
2.设备备份技术:包含设备自身备份技术以及设备间备份技术;
3.堆叠技术。
· 链路备份技术:
○ 链路备份技术用于避免由于单链路故障导致的网络通信中断。当主链路中断后,备用链路会成为新的主用链路。
○ 备份技术有三种:链路聚合、RRPP、Smart Link。
· 链路聚合:
○ 链路聚合是把多条物理链路聚合在一起,形成一条逻辑链路。
○ 采用链路聚合可以提供链路冗余性,又可以提高链路的带宽。
**· RRPP**:
○ RRPP(Rapid Ring Protection Protocol,快速环网保护协议)是一个专门应用于以太网环的链路层协议。
○ 在以太网环上一条链路断开时,RRPP能迅速恢复环网上各个节点之间的通信通路,具备较高的收敛速度。
** Smart Link**:
Smart Link 解决方案,实现了主备链路的冗余备份,具备快速收敛性能,收敛速度可达到亚秒级。
· 设备备份技术:
○ 设备备份技术用于避免由于单设备故障导致的网络通信中断。当主设备中断后,备用板卡或备用设备会成为新的主设备。
○ 技术:1.设备自身的备份技术;
2.设备间的备份技术VRRP。
· 设备自身的备份技术:
○ 主备备份指备用主控板作为主用主控板的一个完全映象,除了不处理业务,不控制系统外,其它与主用主控板保持完全同步。
○ 当主用板发生故障或者被拔出时,备用板将迅速自动取代主用板成为新的主用板,以保证设备的继续运行。
○ 主备备份应用于分布式网络产品的主控板,提高网络设备的可靠性。
· 设备间的备份技术VRRP:
VRRP 将可以承担网关功能的路由器加入到备份组中,形成一台虚拟路由器。
· **IRF**(Intelligent Resilient Framework,智能弹性架构)
是将多台设备通过堆叠口连接在一起形成一台“联合设备”。用户对这台“联合设备”进行管理,可以实现对堆叠中的所有设备进行管理。
· IRF 高可靠性:
○ 堆叠系统由多台成员设备组成,Master 设备负责堆叠的运行、管理和维护,Slave 设备在作为备份的同时也可以处理业务。
○ 一旦Master 设备故障,系统会迅速自动选举新的Master,以保证通过堆叠的业务不中断,从而实现了设备级的1:N 备份。
○ 成员设备之间物理堆叠口支持聚合功能,堆叠系统和上、下层设备之间的物理连接也支持聚合功能,这样通过多链路备份提高了堆叠系统的可靠性。二. 链路聚合
· 链路聚合的产生
○ 链路聚合是把多条物理链路聚合在一起,形成一条逻辑链路。
○ 采用链路聚合可以提供链路冗余性,又可以提高链路的带宽。
· 链路聚合在IEEE 802.3 结构中的位置,是处于MAC CLIENT 和MAC 之间,一个可选的子层。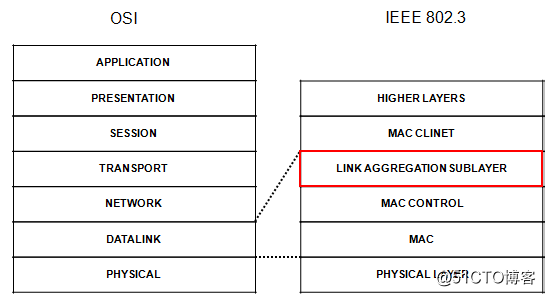
· 链路聚合的相关概念:
○ 聚合接口:是一个手工配置的逻辑接口,链路聚合组是随着聚合接口的创建而自动生成的。
○ 聚合组:是一组以太网接口的集合。
○ 聚合成员端口的状态:Selected状态(可以转发数据),Unselected状态(不能能转发数据)。
○ 操作Key:操作Key 是在链路聚合时,聚合控制根据成员端口的某些配置自动生成的一个配置组合,包括端口属性配置(包含端口速率、双工模式和链路状态配置)和第二类配置
○ 第一类配置:此类配置可以在聚合端口和成员端口上配置,但是不会参与操作Key的计算,如GVRP、MSTP等。
○ 第二类配置:包含:端口隔离、QinQ配置、VLAN配置、MAC地址学习配置,如果成员端口与聚合端口的第二类配置不同的,该成员端口不能成为Selected端口。
· LACP(Link Aggregation Control Protocol)链路聚合控制协议:
○ LACP 协议通过LACPDU(Link Aggregation ControlProtocol Data Unit,链路聚合控制协议数据单元)与对端交互信息。
○ 链路的两端分别称为Actor和Partner,双方通过交换LACPDU报文,与其他端口比较系统的优先级,系统MAC地址、端口优先级。端口号、 操作Key。选择能够汇聚的端口,从而双方可以对接口处于Selected 状态达成一致。
· 聚合接口的速率、双工状态由其Selected 成员端口决定:
聚合接口的速率是Selected 成员端口的速率之和,聚合接口的双工状态与Selected 成员端口的双工状态一致。
· 链路聚合模式:
○ 静态聚合模式:
§ 端口不与对端设备交互信息。
§ 选择参考端口根据本端设备信息。
§ 用户命令创建和删除静态聚合组。
○ 动态聚合模式:
§ 端口的LACP 协议自动使能,与对端设备交互LACP 报文。
§ 选择参考端口根据本端设备与对端设备交互信息。
§ 用户命令创建和删除动态聚合组。
· 静态聚合流程: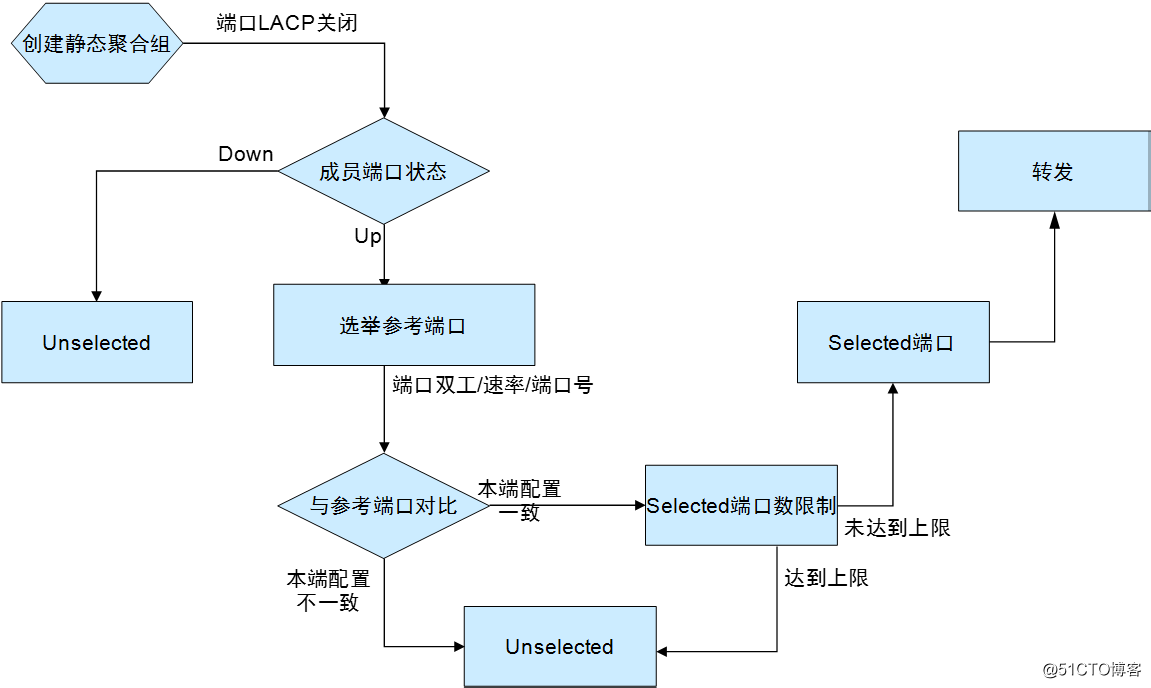
○ 当聚合组内有处于up 状态的端口时,系统按照端口全双工/高速率、全双工/低速率、半双工/高速率、半双工/低速率的优先次序,选择优先次序最高且处于up状态的、端口的第二类配置和对应聚合接口的第二类配置相同的端口作为该组的参考端口(优先次序相同的情况下,端口号最小的端口为参考端口)。
○ 与参考端口的端口属性配置和第二类配置一致且处于up状态的端口成为可能处于Selected状态的候选端口,其它端口将处于Unselected 状态。
○ 聚合组中处于Selected 状态的端口数是有限制的,当候选端口的数目未达到上限时,所有候选端口都为Selected 状态,其它端口为Unselected 状态;当候选端口的数目超过这一限制时,系统将按照端口号从小到大的顺序选择一些候选端口保持在Selected 状态,端口号较大的端口则变为Unselected 状态。
○ 因硬件限制(如不能跨板聚合)而无法与参考端口聚合的端口将处于Unselected 状态。
· 动态聚合流程: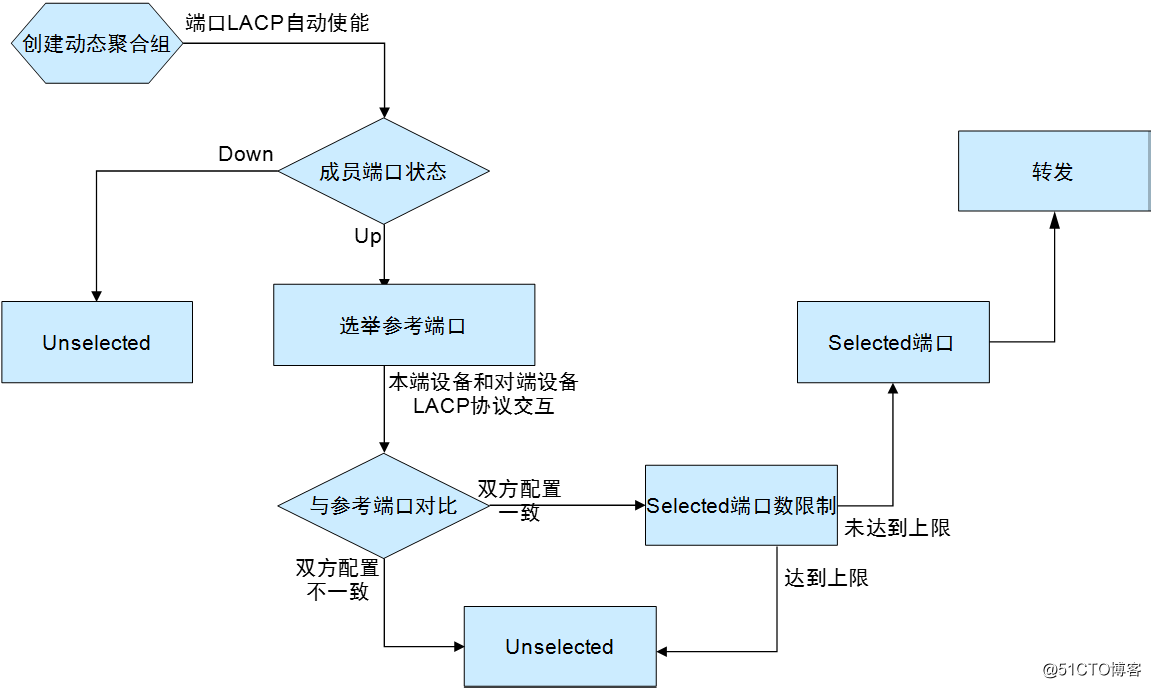
○ 比较两端系统的设备ID(设备ID=系统的LACP 协议优先级+系统MAC 地址)。先比较系统的LACP 协议优先级,如果相同再比较系统MAC 地址。设备ID 小的一端被认为较优(系统的LACP 协议优先级和MAC 地址越小,设备ID 越小)。
○ 比较设备ID 较优的一端的端口ID(端口ID=端口的LACP 协议优先级+端口号)。对于设备ID 较优的一端的各个端口,首先比较端口的LACP 协议优先级,如果优先级相同再比较端口号。端口ID 小的端口作为参考端口(端口的LACP 协议优先级和端口号越小,端口ID 越小)。
○ 与参考端口的端口属性配置和第二类配置一致且处于up 状态的端口、并且该端口的对端端口与参考端口的对端端口的配置也一致时,该端口才成为可能处于Selected 状态的候选端口。否则,端口将处于Unselected 状态。
○ 聚合组中处于Selected 状态的端口数是有限制的,当候选端口的数目未达到上限时,所有候选端口都为Selected 状态,其它端口为Unselected 状态;当候选端口的数目超过这一限制时,系统将按照端口ID 从小到大的顺序选择一些端口保持在Selected 状态,端口ID 较大的端口则变为Unselected 状态。同时,对端设备会感知这种状态的改变,相应端口的状态将随之变化。
○ 因硬件限制(如不能跨板聚合)而无法与参考端口聚合的端口将处于Unselected 状态。
· 静态聚合组配置命令:
○ 创建二层聚合端口,聚合组默认工作在静态聚合模式:
[Switch] interface bridge-aggregation interface-number
○ 将以太网端口加入聚合组:
[Switch-Ethernet1/0/1] port link-aggregation group number
· 动态聚合组配置命令:
○ 创建二层聚合端口:
[Switch] interface bridge-aggregation interface-number
○ 配置聚合组工作在动态聚合模式下:
[Switch-Bridge-Aggregation1] link-aggregation mode dynamic
○ 将以太网端口加入聚合组:
[Switch-Ethernet1/0/1] port link-aggregation group number
○ 配置系统的LACP 协议优先级:
[Switch] lacp system-priority system-priority
○ 配置端口的LACP 协议优先级:
[Switch-Ethernet1/0/1] lacp port-priority port-priority
○ 配置聚合组的聚合负载分担模式:
[Switch] link-aggregation load-sharing mode { destination-ip | destination-mac | destination-port | ingress-port | source-ip | source-mac | source-port }三. smart link和monitor link
· Smart Link:
Smart Link 解决方案,实现了主备链路的冗余备份,具备快速收敛性能,收敛速度可达到亚秒级。
· Smart Link相关概念:
○ Smart Link 组:也称为灵活链路组,一个Smart Link 组包含两个成员端口,其中一个被指定为主端口(Master Port),另一个被指定为副端口(Slave Port),不同的Smart Link 组可以包含同一个端口。正常情况下,只有一个端口(主端口或副端口)处于转发(ACTIVE)状态,另一个端口被阻塞(BLOCK),处于待命(STANDBY)状态。可能主端口被阻塞,但仍是主端口。
○ Flush报文:Smart Link组通过发送Flush报文通知其他设备进行MAC地址转发表和ARP/ND表项的刷新操作。
○ 保护VLAN: 是Smart Link 组内承载数据流量的用户数据VLAN。端口可以加入多个Smart Link 组,这些Smart Link 组保护不同的VLAN。各Smart Link 组分别独立计算组内端口的转发状态。是通过引用MSTP 实例来实现的。
○ 发送控制VLAN(Control VLAN):是Smart Link 组用于广播发送FLUSH 报文。
○ 接收控制VLAN: 是上游设备用于接收并处理FLUSH 报文的VLAN。
· FLUSH 报文格式:
○ Destination MAC :为未知组播地址。可以通过判断该地址是否为0x010FE200-0004 来区分该报文是否为FLUSH 报文。
○ Source MAC :表示发送FLUSH 报文的设备的桥MAC 地址。
○ Control Type: 表示控制类型。目前只有删除MAC 地址转发表项和ARP 表项一种(0x01)。
○ Control Version: 表示版本号。当前版本号为0x00,用于后续版本的扩展。
○ Device ID :表示发送FLUSH 报文的设备的桥MAC 地址。
○ Control VLAN ID :表示发送控制VLAN 的ID 号。
○ Auth-mode: 表示认证模式,和Password 一起使用,便于以后进行安全性扩展。
○ VLAN Bitmap :表示VLAN 位图,用于携带需要刷新地址表的VLAN 列表。
○ FCS :表示帧校验和,用于检查报文的合法性。
· MAC 及ARP 更新的机制目前有以下两种:
○ 由Smart Link 组从新的链路上发送FLUSH 报文进行刷新,流量不会中断:
与支持Smart Link功能的设备对接Smart Link功能,设备由Smart Link 组从新的链路上发送FLUSH 报文进行刷新表项
1.当上游设备收到FLUSH 报文时,判断该FLUSH 报文的发送控制VLAN 是否在收到报文的端口配置的接收控制VLAN 列表中。
2.如果不在接收控制VLAN 列表中,设备对该FLUSH 报文不做处理,直接转发;
3.如果在接收控制VLAN 列表中,设备将提取FLUSH 报文中的VLAN Bitmap 数据,将设备在这些VLAN 内学习到的MAC 及ARP 表项删除。
4.对于需要进行二层转发的报文,该设备会通过二层广播方式进行转发;
5.对于需要进行三层转发的报文,设备会通过ARP 探测方式先更新ARP 表项,然后将报文转发出去。
○ 自动通过流量刷新(表项自动老化、重新学习)但刷新期间流量会中断。
与不支持Smart Link功能的设备对接Smart Link功能,设备自动通过流量刷新表项。
· Smart Link 组支持两种模式:
○ 角色抢占模式、
当主用链路故障恢复后,主端口将抢占为转发状态,副端口则进入待命状态。
只有当主用链路故障时,副端口才会从待命状态切换到转发状态。
○ 非角色抢占模式
当主用链路故障恢复后,副端口将继续处于转发状态,主端口继续处于待命状态,这样可以保持流量的稳定。
· 通过Smart Link 实现流量的负载分担:
○ 在同一个双上行链路组网中,可能同时存在多个VLAN 的数据流量,Smart Link 可以实现流量的负载分担,即不同VLAN 的流量沿不同的路径进行转发。通过把上行链路的端口分别配置为两个Smart Link 组的成员(每个Smart Link 组的保护VLAN 不同),且端口在不同组中的转发状态不同,这样就能实现不同Smart Link 组保护VLAN 的流量转发路径不同,从而达到负载分担的目的。
○ 在实现负载分担时,建议将Smart Link 组配置为角色抢占模式,否则无法保证流量按照用户的想法一直在两条链路上进行分担。因为,如果配置为非角色抢占模式,刚开始可以实现流量分流,但链路故障后所有流量将集中在同一条链路上传输,链路恢复后流量继续在同一条链路上传输,这样就无法达到负载分担的目的。
· Monitor Link产生
当交换机的上行端口所在链路出现故障时配置,Smart Link 组的设备由于主端口未发生故障,不会出现链路切换,导致流量中断。
· Monitor Link 概念:
Monitor Link 组:也叫监控组,每个组由上行链路和下行链路共同组成,成员角色由用户决定。
上行链路(Uplink):是Monitor Link 组被监控的链路。
下行链路(Downlink):是Monitor Link 组的受动链路。
· Monitor Link 运作机制:
○ 当Monitor Link 组中所有上行链路成员端口都为Down 时,将强制使其下行链路成员端口都为Down 状态。
○ 当Monitor Link 组中只要有一个上行链路成员端口从Down 转为Up 状态时,将使下行链路成员端口都恢复为Up 状态。
即(下行端口(Downlink Port)的状态随上行端口(Uplink Port)状态的变化而变化)。
· Smart Link 组配置命令:
○ 创建Smart Link 组:
[Switch] smart-link group group-id
○ 配置Smart Link 组的保护VLAN:
[Switch-smlk-group1] protected-vlan reference-instance instance-id-list
○ 开启发送Flush 报文功能:
[Switch-smlk-group1] flush enable [ control-vlan vlan-id ]
○ 配置Smart Link 组成员端口:
[Switch-smlk-group1] port interface-type interface-number { master | slave }
○ 端口视图下配置Smart Link 组的成员端口:
[Switch-Ethernet1/0/1] port smart-link group group-id { master | slave }
○ 配置Smart Link 抢占功能:
[Switch-smlk-group1] preemption mode role
· Monitor Link 组配置命令:
○ 创建Monitor Link 组:
[Switch] monitor-link group group-id
○ 在Monitor Link 组视图下配置上行链路成员:
[Switch-mtlk-group1] port interface-type interface-number uplink
○ 在Monitor Link 组视图下配置下行链路成员:
[Switch-mtlk-group1] port interface-type interface-number downlink
○ 在端口视图下配置Monitor Link 组上行链路成员:
[Switch-Ethernet1/0/1] port monitor-link group group-id uplink
○ 在端口视图下配置Monitor Link 组下行链路成员:
[Switch-Ethernet1/0/1] port monitor-link group group-id downlink四. RRPP
· RRPP功能:
○ RRPP(Rapid Ring Protection Protocol,快速环网保护协议)是一个专门应用于以太网环的链路层协议。
○ 拓扑收敛速度快(低于50ms),收敛时间与环网上节点数无关。
· H3C 所实现的RRPP 协议还有如下特点:
○ 在相交环拓扑中,一个环拓扑的变化不会引起其他环的拓扑振荡,数据传输更为稳定。
○ 支持RRPP 环网的负载分担,充分利用了物理链路的带宽。
· RRPP基本概念:
○ RRPP域:具有相同的域ID和控制VLAN且相互连通的设备构成一个RRPP域。
○ RRPP 环:是一个环形连接的以太网网络拓扑。
○ 节点:RRPP环上的每一台设备都是一个节点。
○ 主节点:每个环有且仅有一个主节点,主节点是环网状态主动检测机制的发起者,也是检测到RRPP环故障后执行操作的决策者。
○ 传输节点:RRPP 环上除主节点外的所有其它节点是传输节点,传输节点负责透传主节点的HELLO 报文,并监测自己的直连RRPP 链路的状态,把链路DOWN 事件通知主节点。
○ 边缘节点:同时位于主环和子环上的节点,在主环上是传输节点,在子环上是边缘节点。
○ 辅助边缘节点:同时位于主环和子环上的节点,在主环上是传输节点,在子环上是辅助边缘节点。用于检测主环完整性和进行环路预防。
○ 控制VLAN:是用来传递RRPP 协议报文的VLAN。
○ 数据VLAN:是用来传递数据报文的VLAN。
○ 主端口和副端口:主节点和传输节点个子有两个端口接入RRPP环,其中一个为主端口,另一个为副端口,主节点上的主端口用来发送探测环路的报文,副端口用来接受该报文,在RRPP环处于健康状态时,副端口处在逻辑上阻塞数据VLAN,只允许控制VLAN报文通过,当RRPP换处于撕裂状态时,主节点的副端口将解除数据VLAN的阻塞状态,传输节点的主端口和副端口都用来传输数据VLAN和控制VLAN的。
○ 公共端口和边缘端口:公共端口是边缘节点和辅助边缘节点接入主环的端口,边缘端口是边缘节点和辅助边缘节点接入子环的端口。
· 环形物理拓扑常见的三种组网形式为:
○ 每个RRPP 环都是其所在的RRPP 域的一个局部单元。
○ 单环、相交环、相切环。
· 主节点有如下两种状态:
○ Complete State(完整状态):当环网上所有的链路都处于UP 状态,主节点可以从副端口收到自己发送的HELLO 报文,就说主节点处于Complete 状态,此时主节点会阻塞副端口以防止数据报文在环形拓扑上形成广播环路。
○ Failed State(故障状态):当环网上有链路处于故障状态时,主节点处于Failed 状态,此时主节点的副端口放开对数据报文的阻塞,以保证环网上的通信不中断。
○ 主节点的状态代表了整个RRPP 环的状态。即,主节点处于Complete(Failed)状态时,RRPP 环也处于Complete(Failed)状态。
· 传输节点有如下3 种状态:
○ Link-Up State(UP 状态):传输节点的主端口和副端口都处于UP 状态时,就说传输节点处于Link-Up 状态。
○ Link-Down State(Down 状态):传输节点的主端口或副端口处于Down 状态时,就说传输节点处于Link-Down 状态。
○ Preforwarding State(临时阻塞状态):传输节点的主端口或副端口处于阻塞状态时,就说传输节点处于Pre-forwarding 状态。
· RRPP 运作机制:
○ Polling 机制:RRPP 环的主节点主动检测环网健康状态的机制。
○ 链路状态变化通知机制:提供了比Polling机制更快环网拓扑改变的处理机制,发起者是传输节点。
· 环网故障可以通过两种方式检测出来:
○ 轮询机制:主节点通过轮询机制来主动检测环网状态:主节点周期性的从其主端口发送HELLO 报文,依次经过各传输节点在环上传播。如果主节点在规定时间内收不到自己发送的HELLO 报文,认为环网发生链路故障。主节点将状态切换到Failed 状态,放开副端口,并从主、副端口发送COMMON-FLUSH-FDB 报文通知环上所有传输节点刷新MAC 表项和ARP/ND 表项。
○ Link Down 通知机制:节点总是在监测自己的端口链路状态,一旦发现端口Down 将立即采取措施:当传输节点上的RRPP 端口发生链路DOWN 时,该节点将从与故障端口配对的状态为UP 的RRPP 端口发送LINK-DOWN 报文通知主节点(LINK-DOWN 上主节点收到LINK-DOWN 报文后,放开副端口,立即将状态切换到Failed 状态。由于网络拓扑发生改变,主节点还需要刷新MAC 表项和ARP/ND表项, 并从主、副端口发送COMMON-FLUSH-FDB 报文通知所有传输节点刷新MAC 表项ARP/ND 表项。
· 环网故障恢复检测及处理机制:
○ 传输节点端口恢复的瞬间,主节点还不能马上知道这一信息,因此其副端口还处于放开状态。这时如果传输节点立即迁移回Link-Up 状态,势必造成数据报文在环网上形成瞬时环路,因此处于Link-Down 状态的传输节点的主、副端口都恢复时,传输节点立即阻塞刚刚恢复的端口,迁移到Pre-forwarding状态。环网恢复的过程是由主节点主动发起的。环上所有链路恢复正常后,当处于Failed 状态的主节点重新收到自己发出的HELLO 报文,将阻塞副端口,将状态迁移回Complete状态。
○ 链路状态变化通知机制的缺陷:
若双归属的两个子环借助边缘节点相互连接,则当主环故障发生后,两个子环的主节点副端口都放开,会形成环路。
○ 主环上子环协议报文通道状态检查机制:
主环上子环协议报文通道状态检测机制,是在子环主节点副端口放开之前,阻塞边缘节点的边缘端口,从而避免子环间形成数据环路。
○ 环组机制:
为减少Edge-Hello 报文的收发数量,将边缘节点和辅助边缘节点上的两个RRPP环配置为一个环组。
· 报文类型说明
○ Health(Hello) :健康检测报文,由主节点发起,对网络进行环路完整性检测。
○ Link-Down:链路Down 报文,由发生直连链路状态Down的传输节点、边缘节点或者辅助边缘节点发起,通知主节点环路上有链路Down,物理环路消失。
○ Common-Flush-Fdb:刷新Fdb 报文,由主节点发起,通知传输节点、边缘节点或者辅助边缘节点更新各自Mac地址转发表。
○ Complete-Flush-Fdb:环网恢复刷新Fdb 报文,由主节点发起,通知传输节点、边缘节点或者辅助边缘节点更新各自Mac 地址转发表,同时通知传输节点放开临时阻塞端口。
○ Edge-Hello:主环完整性检查报文,由子环的边缘节点发起,同子环的辅助边缘节点接收,子环通过此报文检查其所在域主环的环路完整性。
○ Major-Fault:主环故障通知报文,当子环的辅助边缘节点在规定时间内收不到边缘节点发送的
○ Edge-Hello:报文时发起,向边缘节点报告其所在域主环发生故障。
· RRPP 配置命令:
○ 创建RRPP 域:
[Switch] rrpp domain domain-id
○ 配置控制VLAN:
[Switch-rrpp-domain1] control-vlan vlan-id
○ 配置保护VLAN:
[Switch-rrpp-domain1] protected-vlan reference-instance instance-id-list
○ 配置主节点:
[Switch-rrpp-domain1] ring ring-id node-mode master [ primary-port interface-type interface-number ] [ secondary-port interface-type interface-number ] level level-value
○ 配置传输节点:
[Switch-rrpp-domain1] ring ring-id node-mode transit [ primary-port interface-type interface-number ] [ secondary-port interface-type interface-number ] level level-value
○ 配置边缘节点:
[Switch-rrpp-domain1] ring ring-id node-mode edge [ edge-port interface-type interface-number ]
○ 配置辅助边缘节点:
[Switch-rrpp-domain1] ring ring-id node-mode assistant-edge [ edge-port interface-type interface-number ]
○ 使能RRPP 协议:
[Switch] rrpp enable
○ 使能RRPP 环:
[Switch-rrpp-domain1] ring ring-id enable
○ 创建RRPP 环组:
[Switch] rrpp ring-group ring-group-id
○ 将子环加入RRPP 环组:
[Switch-rrpp-ring-group1] domain domain-id ring ring-id-list五. VRRP
· VRRP 负载分担:
VRRP 将多台路由器同时承担业务,形成多台虚拟路由器,分担内网与外网之间的流量。
· VRRP 概述:
○ RFC 3768 定义的VRRPv2是一种容错协议,在提高可靠性的同时,简化了主机的配置。
○ VRRP 协议报文使用固定的组播地址224.0.0.18进行发送。
○ 虚拟路由器由LAN 上唯一的VirtualRouter ID 标识。并具有虚MAC 地址:00-00-5E-00-01-{vrid}。
· VRRP相关概念:
○ VRRP 备份组:将局域网内的一组运行VRRP协议路由器划分在一起,称为一个备份组,功能相当于一台虚拟路由器。
○ 虚拟路由器号(VRID):虚拟路由器的标识。有相同VRID 的一组路由器构成一个虚拟路由器。
○ Master 路由器:虚拟路由器中承担报文转发任务的路由器(优先级最高)。
○ Backup 路由器:Master 路由器出现故障时,能够代替Master 路由器工作的路由器。
○ 虚拟MAC地址(Virtual MAC Address):一个虚拟路由器有一个虚拟MAC地址,格式为:00-00-5E-00-01-{vrid},当虚拟路由器回应ARP请求时,回应的是虚拟MAC地址。
○ IP 地址拥有者:接口IP 地址与虚拟IP 地址相同的路由器被称为IP 地址拥有者。
○ 优先级(Priority):VRRP根据优先级来确定参与备份组的Master(优先级最优)和Backup路由器,缺省值:100,范围1-254,0 为系统保留给路由器放弃Master 位置时候使用,255保留给IP地址拥有者。
○ 非抢占方式:如果Backup 路由器工作在非抢占方式下,则只要Master 路由器没有出现故障,Backup 路由器即使随后被配置了更高的优先级也不会成为Master 路由器。
○ 抢占方式:如果Backup 路由器工作在抢占方式下,当它收到VRRP 报文后,会将自己的优先级与通告报文中的优先级进行比较。如果自己的优先级比当前的Master 路由器的优先级高,就会主动抢占成为Master 路由器;否则,将保持Backup 状态。
○ 认证类型(Authentication Type):无认证、简单字符认证、MD5认证。
· VRRP 监视接口功能:
○ 当Master 路由器连接上行链路的接口处于Down 状态时,路由器主动降低自己的优先级,使得备份组内重新选择Master,承担转发任务。
§ VRRP 可以利用NQA技术监视上行链路连接的远端主机或者网络状况。例如,Master 设备上启动NQA的ICMP-echo 探测功能,探测远端主机的可达性。当ICMP echo 探测失败时,它可以通知本设备探测结果,达到降低VRRP优先级的目的。
§ VRRP 也可以利用BFD技术监视上行链路连接的远端主机或者网络状况。由于BFD的精度可以到达10ms,通过BFD能够快速检测到链路状态的变化,达到快速抢占的目的。
§ Backup 路由器在Master 路由器坏掉之后,正常情况下需要等待Master_Down_Interval 才能切换为新的Master 的位置,这段时间内主机将无法正常通信。Backup 路由器监视Master 路由器采用的是具有快速检测功能的BFD 技术。在Backup 设备上使用该技术监视Master 路由器的状态,一旦Master 路由器发生故障,Backup就可以自动切换成为新的Master路由器,将切换时间缩短到毫秒级。
· VRRP 协议状态机:
○ Master 状态:定期发送VRRP广播报文,响应对虚拟IP地址的ARP请求。
○ Backup 状态:接受Master发送的VRRP广播报文,不响应对虚拟IP地址的ARP请求,丢弃目的地址为虚拟MAC地址的IP报文。
○ Initialize(初始化)状态:不对VRRP报文做任何处理。
· VRRP 相关命令:
○ 配置虚拟IP 地址和MAC 地址的对应关系:
[Switch] vrrp method { real-mac | virtual-mac }此关系需在备份组创建之前设定,否则不允许修改此关系。
○ 创建VRRP 备份组并配置虚拟IP 地址:
[Switch-Ethernet1/0/1] vrrp vrid virtual-router-id virtual-ip virtual-address
○ 配置路由器在备份组中的优先级:
[Switch-Ethernet1/0/1] vrrp vrid virtual-router-id priority priority-value
○ 配置备份组中的路由器工作在抢占方式,并配置抢占延迟时间:
[Switch-Ethernet1/0/1] vrrp vrid virtual-router-id preempt-mode [ timer delay delay-value ]
○ 配置监视指定接口:
[Switch-Ethernet1/0/1] vrrp vrid virtual-router-id track interface interface-type interface-number [ reduced priority-reduced ]
○ 配置备份组发送和接收VRRP 报文的认证:
[Switch-Ethernet1/0/1] vrrp vrid virtual-router-id authentication-mode { md5 | simple } key
○ 配置备份组中Master 路由器发送VRRP 通告报文的时间间隔:
[Switch-Ethernet1/0/1] vrrp vrid virtual-router-id timer advertise adver-interval
○ 显示VRRP 备份组的状态信息:
[Switch] display vrrp [ verbose ] [ interface interface-type interface-number [ vrid virtual-router-id ] ]
· 虚拟IP地址不能为0.0.0.0、255.255.255.255、Loopback地址、非A/B/C类地址和其它非法IP地址(0.0.0.1)。虚IP地址和接口ip地址在同一网段,且为合法的主机地址时,备份组才能够正常工作。否则备份组会始处于Initialize状态。六. IRF
· IRF产生背景:
○ 盒式设备成本低廉,缺乏不中断的业务保护,无法应用于重要的场合。
○ 框式分布式设备具有高可用性、高性能、高端口密度的优点,经常被应用于一些重要场合。
· IRF (Intelligent Resilient Framework:智能弹性架构)堆叠:
将多台设备通过堆叠口连接起来,形成一台虚拟的逻辑设备。其优点有:简化管理、提高性能、弹性扩展、高可靠性。
· IRF 堆叠相关概念:
○ Master 设备:IRF 堆叠中的成员设备,负责管理整个堆叠。
○ Slave 设备:IRF 堆叠中的成员设备,隶属于Master 设备,作为此设备的备份设备运行。
○ 物理堆叠口:成员设备上用于堆叠连接的物理端口。
○ 堆叠口:物理堆叠口需要和逻辑堆叠口绑定。
○ 聚合堆叠口:由多个物理堆叠口聚合的堆叠口。
· IRF 堆叠物理拓扑有两种:
○ 链形拓扑
○ 环形拓扑:具有较高的可靠性。
· IRF堆叠的形成
○ IRF 中的每台设备都是通过和自己直接相邻的其它成员设备之间交互IRF Hello 报文来收集整个IRF 的拓扑关系。Hello报文包括堆叠口连接关系、成员设备编号、成员设备优先级、成员设备的成员桥MAC地址等。
○ 拓扑收集完成后,会进入角色选举阶段,确定成员设备角色。
· 角色选举规则:
○ 当前Master优先于非Master成员。
○ 成员设备均是框式分布式设备时,本地主用板做于本地备用主控板。
○ 成员设备均是框式分布式设备时,原Master备用主控板做于非Master成员上的主控板。
○ 成员优先级大的优先。
○ 系统运行时间长的优先。
○ 成员桥MAC 小的优先。
○ 选举阶段Master会负责成员编号冲突处理、软件版本加载、堆叠合并管理
· IRF堆叠虚拟设备
○ 盒式设备堆叠后形成的虚拟设备相当于一台框式分布式设备,堆叠中的Master 相当于虚拟设备的主用主控板,Slave 设备相当于备用主控板。
○ 框式分布式设备堆叠后形成的虚拟设备拥有更多的备用主控板和接口板。
· IRF 堆叠维护的主要功能是:
○ 监控成员设备的加入和离开,并随时收集新的拓扑,维护现有拓扑。
○ 成员加入:
新加入设备本身未形成堆叠则选为Slave。如形成堆叠,相当于两个堆叠合并(Merge),进行堆叠竞选,失败的一方所有堆叠成员设备需要重启。然后全部作用Slave设备加入竞选获胜一方。
○ 判断成员离开方式:
直接相邻成员设备定期(200ms)交换Hello报文,如持续多个周期(通常为10个)未收到直接邻居的Hello报文,则认为该成员离开堆叠系统,将其从拓扑中隔离出来。
如发现堆叠口Down,则拥有该堆叠口的成员设备会紧急广播通知堆叠中其它成员,立即重新计算当前拓扑不用等到Hello超时。
如离开的是Master设备,会重新进行选举。
· IRF 的配置同步包括两个步骤:初始化时的批量同步和稳定运行时的实时同步:
○ 批量同步:
当多台设备组合形成IRF 时,先选举出Master 设备。Master 设备使用自己的启动配置文件启动,Master 设备启动完成后,将配置批量同步给所有Slave 设备,Slave 设备完成初始化,IRF 形成;在IRF 运行过程中,有新的成员设备加入时,也会进行批量同步。新设备重启以Slave 的身份加入IRF,Mater 会将当前的配置批量同步给新设备。新设备以同步过来的配置完成初始化,而不再读取本地的启动配置文件。
○ 实时同步:
所有设备初始化完成后,IRF 作为单一网络设备在网络中运行。用户使用Console 口或者Telnet 方式登录到IRF 中任意一台成员设备,都可以对整个IRF 进行管理和配置。Master 设备作为IRF 系统的管理中枢,负责响应用户的登录请求,即用户无论使用什么方式,通过哪台成员设备登录IRF,最终都是对Master 设备进行配置。
· IRF 中采用的是1:N 冗余
Master 负责处理业务,多个Slave 作为Master 的备份,随时与Master 保持同步。
· IRF 堆叠协议热备份:
在1:N 冗余环境下,协议热备份负责将协议的配置信息以及支撑协议运行的数据(比如状态机或者会话表项等)备份到其它所有成员设备,从而使得IRF 系统能够作为一台独立的设备在网络中运行。
· IRF 堆叠上/下行链路的冗余备份:
IRF 支持的新型分布式聚合技术则可以跨设备配置链路备份,用户可以将不同成员设备上的物理以太网端口配置成一个聚合端口,防止单点故障导致的网络中断。
· IRF 堆叠堆叠口的冗余备份:
IRF 采用聚合技术来实现IRF 端口的冗余备份。IRF 端口的连接可以由多条IRF 物理链路聚合而成,多条物理链路之间可以对流量进行负载分担。
· IRF 堆叠报文转发原理:
IRF 采用分布式弹性转发技术实现报文的二/三层转发。IRF 系统中的每个成员设备都有完整的二/三层转发能力,当它收到待转发的二/三层报文时,可以通过查询本机的二/三层转发表得到报文的出接口(以及下一跳),然后将报文从正确的出接口送出去,这个出接口可以在本机上也可以在其它成员设备上,并且将报文从本机送到另外一个成员设备是一个纯粹内部的实现,对外界是完全屏蔽的,即对于三层报文来说,不管它在IRF 系统内部穿过了多少成员设备,在跳数上只增加1,即表现为只经过了一个网络设备。
· IRF 典型应用:
○ IRF 堆叠扩展端口数量:
当接入的用户数增加到原交换机端口密度不能满足接入需求时,可以通过可以增加新交换机与原交换机组成堆叠系统来实现。
○ IRF 堆叠扩展系统处理能力:
当中心的交换机转发能力不能满足需求时,可以增加新交换机与原交换机组成堆叠系统来实现。
○ IRF 堆叠扩展带宽:
当边缘交换机上行带宽增加时,可以增加新交换机与原交换机组成堆叠系统来实现。
○ 跨越空间使用IRF:
IRF 堆叠可以通过光纤将相距遥远的设备连接形成堆叠设备。(1 楼、2 楼、3 楼)
· IRF 堆叠配置命令:
○ 绑定设备的逻辑堆叠口和物理堆叠口,同时开启当前设备的堆叠功能:
[Switch] irf member member-id irf-port irf-port-id port port-list
○ 配置IRF 成员编号:
[Switch] irf member member-id renumber new-member-id
○ 配置堆叠中指定成员设备的优先级:
[Switch] irf member member-id priority priority 配置堆叠口命令和配置成员优先级命令需要重启设备才能生效。
○ 访问IRF 堆叠:
<Switch> irf switch-to member-id
○ 在Slave 设备上只允许执行以下命令:
display
quit
return
system-view
debugging
terminal debugging
terminal trapping
terminal logging
· 成员设备之间IRF 物理端口支持聚合功能,IRF 系统和上、下层设备之间的物理连接也支持聚合功能,这样通过多链路备份提高了IRF 系统的可靠性;IRF 系统由多台成员设备组成,Master 设备负责IRF 系统的运行、管理和维护,Slave 设备在作为备份的同时也可以处理业务,一旦Master 设备故障,系统会迅速自动选举新的Master,以保证通过IRF 系统的业务不中断,从而实现了设备的1:N 备份。IRF 是网络可靠性保障的最优解决方案。一个IRF 中同时只能存在一台Master,其它成员设备都是Slave。
· 两个IRF 各自已经稳定运行,通过物理连接和必要的配置,形成一个IRF,这个过程称为IRF 合并(merge)。一个IRF 形成后,由于IRF 链路故障,导致IRF 中两相邻成员设备物理上不连通,一个IRF 变成两个IRF,这个过程称为IRF 分裂(split)。
· 当IRF 端口状态变为up 后,成员设备会将已知的拓扑信息周期性的从up 状态的IRF 端口发送出去。成员设备收到直接邻居的拓扑信息后,会更新本地记录的拓扑信息。经过一段时间的收集,所有设备上都会收集到完整的拓扑信息(称为拓扑收敛)。此时会进入角色选举阶段。
· 使用IRF 专用线缆连接IRF 物理端口。专用线能够为成员设备间报文的传输提供很高的可靠性和性能。如果使用以太网接口作为IRF 物理端口,则使用交叉网线连接IRF 物理端口即可。这种连接方式提高了现有资源的利用率,有利于节约成本(不需要购置IRF 专用接口卡或者光模块等)。以上是关于深入浅出高可靠性技术的主要内容,如果未能解决你的问题,请参考以下文章
[深入研究4G/5G/6G专题-50]: URLLC-16-《3GPP URLLC相关协议规范技术原理深度解读》-10-高可靠性技术-1-低编码率编码调制方案MCS与高可靠性DRB
技术解析系列 | PouchContainer 支持 LXCFS 实现高可靠容器隔离
技术解析系列 | PouchContainer 支持 LXCFS 实现高可靠容器隔离
深入解析DC/OS 1.8 – 高可靠的微服务及大数据管理平台