02_Python基础
Posted python.well
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了02_Python基础相关的知识,希望对你有一定的参考价值。
一、pyc.文件
1. 解释型语言和编译型语言
计算机是不能够识别高级语言的,所以当我们运行一个高级语言程序的时候,就需要一个“翻译机”来从事把高级语言转变成计算机能读懂的机器语言的过程。这个过程分成两类,第一种是编译,第二种是解释。
编译型语言在程序执行之前,先会通过编译器对程序执行一个编译的过程,把程序转变成机器语言。运行时就不需要翻译,而直接执行就可以了。最典型的例子就是C语言。
解释型语言就没有这个编译的过程,而是在程序运行的时候,通过解释器对程序逐行作出解释,然后直接运行,最典型的例子是Ruby。
通过以上的例子,我们可以来总结一下解释型语言和编译型语言的优缺点,因为编译型语言在程序运行之前就已经对程序做出了“翻译”,所以在运行时就少掉了“翻译”的过程,所以效率比较高。但是我们也不能一概而论,一些解释型语言也可以通过解释器的优化来在对程序做出翻译时对整个程序做出优化,从而在效率上超过编译型语言。
此外,随着Java等基于虚拟机的语言的兴起,我们又不能把语言纯粹地分成解释型和编译型这两种。
用Java来举例,Java首先是通过编译器编译成字节码文件,然后在运行时通过解释器给解释成机器文件。所以我们说Java是一种先编译后解释的语言。
2. Python到底是什么
其实Python和Java/C#一样,也是一门基于虚拟机的语言,我们先来从表面上简单地了解一下Python程序的运行过程吧。
当我们在命令行中输入python hello.py时,其实是激活了Python的“解释器”,告诉“解释器”:你要开始工作了。可是在“解释”之前,其实执行的第一项工作和Java一样,是编译。
熟悉Java的同学可以想一下我们在命令行中如何执行一个Java的程序:
javac hello.java
java hello
只是我们在用Eclipse之类的IDE时,将这两部给融合成了一部而已。其实Python也一样,当我们执行python hello.py时,他也一样执行了这么一个过程,所以我们应该这样来描述Python,Python是一门先编译后解释的语言。
3. 简述Python的运行过程
在说这个问题之前,我们先来说两个概念,PyCodeObject和pyc文件。
我们在硬盘上看到的pyc自然不必多说,而其实PyCodeObject则是Python编译器真正编译成的结果。我们先简单知道就可以了,继续向下看。
当python程序运行时,编译的结果则是保存在位于内存中的PyCodeObject中,
当Python程序运行结束时,Python解释器则将PyCodeObject写回到pyc文件中。
当python程序第二次运行时,首先程序会在硬盘中寻找pyc文件,如果找到,则直接载入,否则就重复上面的过程。
所以我们应该这样来定位PyCodeObject和pyc文件,我们说pyc文件其实是PyCodeObject的一种持久化保存方式。
小结:
1.执行Python代码时,如果导入了其他的.py文件,那么,执行过程中会自动生成一个与其同名的 .pyc 文件,该文件就是Python解释器编译之后产生的字节码。
2.当python程序第二次运行时,首先程序会在硬盘中寻找pyc文件,如果找到,则直接载入,否则就重复第1步的过程。
3.如果修改过导入的.py文件,程序运行时会对比py文件和.pyc文件的修改时间,如有变化,重新生成.pyc文件。
二、数据类型
1.数字
- nt(整型)
- long(长整型)
- float(浮点型)
- complex(复数)
PS:查看数据类型可用 type 命令
>>> Num = 2**32 >>> type(Num) <type \'long\'> >>> Num = 2**8 >>> type(Num) <type \'int\'> >>> Num = 3.1415 >>> type(Num) <type \'float\'>
2、布尔值
真或假 | 1 或 0
1 1 或 0
2
3 >>> 0 == True
4
5 False
6
7 >>> 0 == False
8
9 True
10
11 >>> 1 == True
12
13 True
14
15 >>> 1 == False
16
17 False
3、字符串
"hello world"
字符串格式化输
>>> name = "alex" >>> print "I am %s" % name I am alex
PS:字符串是%s、整数%d、浮点数%f
字符串常用功能
- 移除空白
- 分割
- 长度
- 索引
- 切片
万恶的字符串拼接:
python中的字符串在C语言中体现为是一个字符数组,每次创建字符串时候需要在内存中开辟一块连续的空,并且一旦需要修改字符串的话,就需要再次开辟空间,万恶的+号每出现一次就会在内从中重新开辟一块空间。
>>> name = \'alex\' >>> print ("my name is " + name + " and you ?") my name is alex and you ?
PS:此法会在内存中重新开辟一块空间,建议少用
字符串操作
name = "alex li 123 !.@#" print(name[2:4]) #打印字符 print("name",len(name)) #打印字符串长度 print(name.center(40,\'-\')) #分割符 print(name.find(\'li\')) #查找字符/字符串的位置 print(\'\' in name) #判断是否有空格 print(name.capitalize()) #首字母大写 print(name.isalnum()) #判断是否有特殊符号 print(name.endswith(\'#\')) #判断是否以xxx结尾 print(name.startswith(\'al\')) #判断是否以xxx开头 print(name.upper().lower()) #字母大小写转换 name.extend(name2) #扩展进来一个新的列表 name.reverse(name) #反转列表 name.sort(name) #排序 #name.format()#字符串格式化 msg2 = "haha{0},ddd{1}" print(msg2.format(\'Alex\',33)) msg = "hello ,{name},it\'s been a long {age}...." msg3 = msg.format(name=\'MingHu\',age=333) print(msg3) #字符串拆分为列表 names = "alex,jack,rain" name2 = names.split(",") print(name2) #列表合并字符串 print("|".join(name2)) #去掉字符串前后的空格 username = input("user:") if username.strip() == \'alex\': print("welcome")
执行结果:
>>> name = "alex li 123 !.@#" >>> print(name[2:4]) #打印字符 ex >>> print("name",len(name)) #打印字符串长度 name 16 >>> print(name.center(40,\'-\')) #分割符 ------------alex li 123 !.@#------------ >>> print(name.find(\'li\')) #查找字符/字符串的位置 5 >>> print(\'\' in name) #判断是否有空格 True >>> print(name.capitalize()) #首字母大写 Alex li 123 !.@# >>> print(name.isalnum()) #判断是否有特殊符号 False >>> print(name.endswith(\'#\')) #判断是否以xxx结尾 True >>> print(name.startswith(\'al\')) #判断是否以xxx开头 True >>> print(name.upper().lower()) #字母大小写转换 alex li 123 !.@# >>> #name.format()#字符串格式化 ... msg2 = "haha{0},ddd{1}" >>> print(msg2.format(\'Alex\',33)) hahaAlex,ddd33 >>> msg = "hello ,{name},it\'s been a long {age}...." >>> msg3 = msg.format(name=\'MingHu\',age=333) >>> print(msg3) hello ,MingHu,it\'s been a long 333.... >>> >>> >>> #字符串拆分为列表 ... names = "alex,jack,rain" >>> name2 = names.split(",") >>> print(name2) [\'alex\', \'jack\', \'rain\'] >>> #列表合并字符串 ... print("|".join(name2)) alex|jack|rain >>> #去掉字符串前后的空格 >>> username = input("user:") user:alex >>> if username.strip() == \'alex\':print("welcome") ... welcome >>> username = input("user:") user:long >>> if username.strip() == \'alex\':print("welcome") ...
4、列表
创建列表
#法1:
>>> name_list = [\'alex\', \'seven\', \'eric\'] >>> print(name_list) [\'alex\', \'seven\', \'eric\']
#法2: >>> name_list = list([\'alex\', \'seven\', \'eric\']) >>> print(name_list) [\'alex\', \'seven\', \'eric\']
基本操作:
- 索引
- 切片
- 追加
- 删除
- 长度
- 切片
- 循环
- 包含
>>> name = ["MingLong","MingHu","Jack",22,9] >>> name[2] \'Jack\' >>> name[1] \'MingHu\' >>> name[-1] 9 >>> name[0:2] #下标,取多值时顾首不顾尾 [\'MingLong\', \'MingHu\'] >>> name[0:-1] [\'MingLong\', \'MingHu\', \'Jack\', 22] >>> name[-3:] [\'Jack\', 22, 9] >>> name[:3] [\'MingLong\', \'MingHu\', \'Jack\']
#多次取值 >>> name[:3][1:2] [\'MingHu\'] >>> name[:3][1:2][0][1] \'i\' #修改数据 >>> name[1] = "WangMinghu" >>> name [\'MingLong\', \'WangMinghu\', \'Jack\', 22, 9] #插入数据,一次只能插入一个数据 >>> name.insert(2,\'MingGou\') >>> name [\'MingLong\', \'WangMinghu\', \'MingGou\', \'Jack\', 22, 9] #追加数据 >>> name.append("alex") >>> name [\'MingLong\', \'WangMinghu\', \'MingGou\', \'Jack\', 22, 9, \'alex\'] #删除数据 >>> name.remove("MingGou") >>> name [\'MingLong\', \'WangMinghu\', \'Jack\', 22, 9, \'alex\']
#只读列表 元组
r = (1,2,3,4,5)
r[1] = 3
练习题:
- 写一个列表,列表里包含本组所有成员
- 往中间插入两个临组成员的名字
- 取出第3-8的人的列表
- 删除第7个人
- 把刚才加入的那2个其它组的人一次性删除
- 把组长的名字加上备注
- 隔一个人打印一个人


1 #1.创建列表 2 name = ["Longlong","Chengcheng","Zhengzheng","Yanyan","Xixi","Xiongxiong","Xuxu","Junjun"] 3 print(name) 4 5 #2.往中间插入两个临组成员的名字 6 name.insert(4,"Kaikai") 7 name.insert(4,"Nannan") 8 print(name) 9 10 #3.取出第3-8的人的列表 11 print(name[2:8]) 12 13 #4. 删除第7个人 14 name3 = name[7] 15 print(name3) 16 name.remove("Xuxu") 17 print(name) 18 19 #5. 把刚才加入的那2个其它组的人一次性删除 20 for deletename in ("Kaikai","Nannan"):name.remove(deletename) 21 #del name[4:6] #按顺序删除,可能误删 #del全局命令,可以删除任意内容 22 print(name) 23 24 #6.把组长的名字加上备注 25 print(name[2],\'组长\') 26 name[2] = "Zhengzheng_ZuZhang" 27 print(name[2]) 28 print(name) 29 30 #7.隔一个人打印一个人 31 print(name[0:-1:2]) #打印步长 32 print(name[0::2]) 33 print(name[::2])
列表的常用操作
- copy
- reverse
- sort
- pop
- extend
- index
- list[::2]
- del
5、字典
字典书写格式
id_db = { 371471199306143632:{ \'name\':"Alex Li", \'age\': 22, \'addr\':"ShanDong" }, 220471199306143632:{ \'name\':"ShanPao", \'age\':22, \'addr\':"DongBei" }, 221471199306143632:{\'name\':"ShanPao",\'age\':22,\'addr\':"DongBei"}, }
字典常用操作
print(id_db) print(id_db)#打印字典 print(id_db[220471199306143632]) #取值 id_db[220471199306143632][\'name\'] = "WanMinghu" #修改 id_db[220471199306143632][\'qq_of_wife\'] = 234235435 #增加 id_db[220471199306143632].pop("addr") #删除pop del id_db[220471199306143632][\'addr\'] #删除del v = id_db.get(2204711993061436323) #获取key值时,如没有,不报错,返回none print(v) v1 = id_db[220471199306143633] #取值key值时,如没有,报错 print(v1) print(id_db.items()) #把字典转换成列表 #数据量大时,不要把字典的内容转成列表形式,生成时间会非常非常长 print(id_db.values()) #列出字典里的所有值 print(id_db.keys()) #打印字典keys id_db.has_key(220471199306143632) #only 2.x print(id_db.setdefault(220471199306143632,"hahah")) #取一个key,如果不存在,就设置添加一个 print(id_db.fromkeys([1,2,34,4,5,6],\'ddd\')) #不要用 print(id_db.popitem()) #随机删除,不要用 print(id_db)
三、数据运算
算数运算:
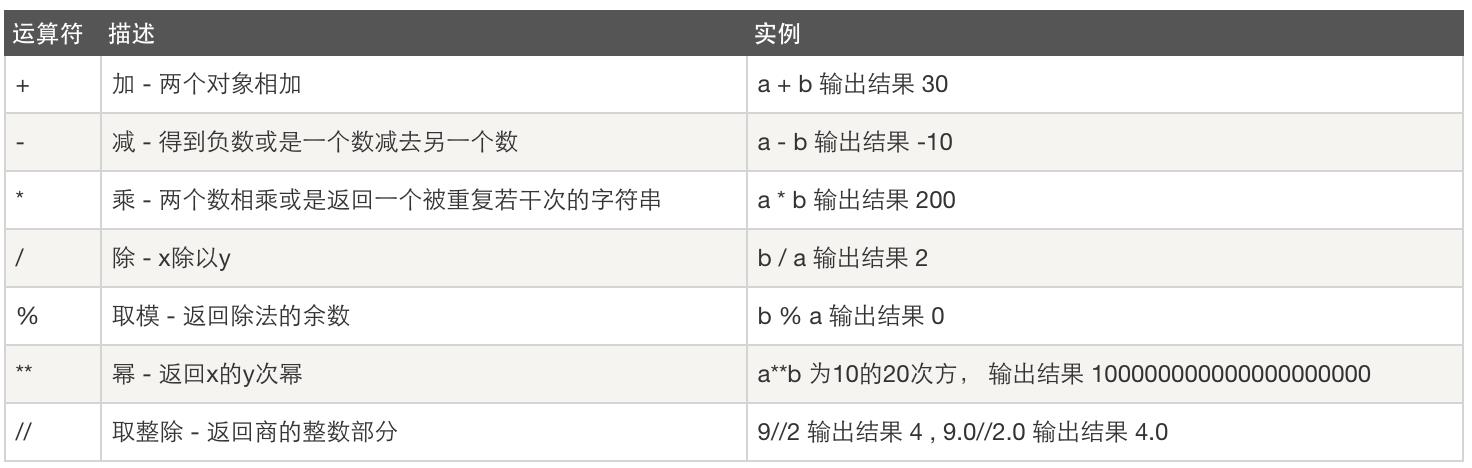
比较运算:

赋值运算:

逻辑运算:

成员运算:

身份运算:

位运算:

运算符优先级:
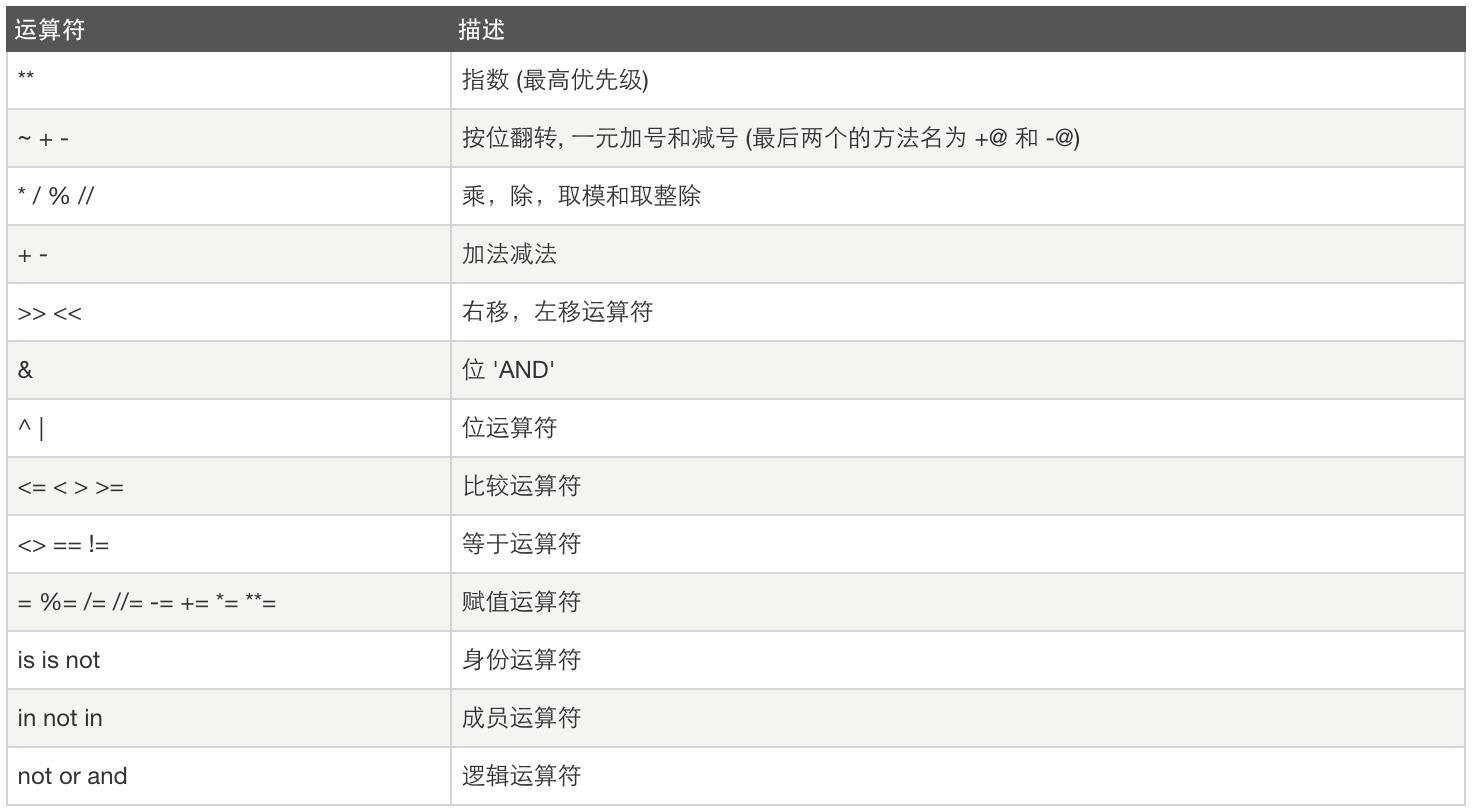
四、表达式
1. for 循环
最简单的循环10次
for i in range(10): print("loop:", i )
输出:
loop: 0 loop: 1 loop: 2 loop: 3 loop: 4 loop: 5 loop: 6 loop: 7 loop: 8 loop: 9
练习:
name = ["long","cheng","zheng",[4,6,8,978,"wfasdf","asdfasdf"],9,345,12,"yan","xi","xiong","Xu",3,4,21,234,345,456,9,"jun"]
1.找出有多少个9,把它改成9999
2.同时找出所有34,把它删除
法1:
if 9 in name: num_of_ele = name.count(9) print("%s 个9" % num_of_ele) posistion_of_ele = name.index(9) print(posistion_of_ele)
1答:
for i in range(name.count(9)): ele_index = name.index(9) name[ele_index] = 9999 print(name)
输出结果:
[\'long\', \'cheng\', \'zheng\', [4, 6, 8, 978, 9, \'wfasdf\', \'asdfasdf\'], 9999, 345, 12, \'yan\', \'xi\', \'xiong\', \'Xu\', 3, 4, 21, 234, 345, 456, 9999, \'jun\']
2答:
for i in range(name.count(9)): ele_index = name.index(9) name[ele_index] = 9999 print(name)
输出结果:
[\'long\', \'cheng\', \'zheng\', [4, 6, 8, 978, 9, \'wfasdf\', \'asdfasdf\'], 9, 12, \'yan\', \'xi\', \'xiong\', \'Xu\', 3, 4, 21, 234, 456, 9, \'jun\']
错误使用案例
#for k,v in id_db.items(): #效率低,因为要有一个dict to list的转换过程
# print(k,v)
for key in id_db:
print(key,id_db[key ])
2.while循环
海枯石烂代码,死循环
count = 0 while True: print("你是风儿我是沙,缠缠绵绵到天涯...",count) count += 1
死循环代码尽量少写,上面代码增加退出条件,运行100次退出
count = 0 while True: count +=1 if count > 50 and count <60: continue print("你是风儿我是沙,缠缠绵绵到天涯...",count) if count == 100: print("不玩了",count) break
练习:购物小程序
#0.用户启动时先输入工资。
#1.用户启动程序后,打印商品列表。
#2.允许用户选择购买商品。
#3.允许用户不断的购买各种商品。
#4.购买时检测余额是否足够,如果足够直接付款,否则打印余额不足
#5.允许用户主动退出程序,退出时打印已购列表。
salary = input("Input your salary:") if salary.isdigit(): salary = int(salary) else: exit("Invaild data type.") welcome_msg = \'Welcome to Ales Shopping mall\'.center(50,\'-\') print(welcome_msg) product_list = [ (\'Iphone\',5888), (\'Mac Air\',8000), (\'Mac Pro\',9000), (\'XiaoMi 2\',19.9), (\'Coffee\',30), (\'Tesla\',820000), (\'Bike\',700), (\'Cloth\',200),] shop_car = [] exit_flag = False while exit_flag is not True: #for product_item in product_list: # p_name,p_price = product_item print("product list".center(50,<以上是关于02_Python基础的主要内容,如果未能解决你的问题,请参考以下文章