Spark篇---Spark中资源调度源码分析与应用
Posted L先生AI课堂
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark篇---Spark中资源调度源码分析与应用相关的知识,希望对你有一定的参考价值。
一、前述
Spark中资源调度是一个非常核心的模块,尤其对于我们提交参数来说,需要具体到某些配置,所以提交配置的参数于源码一一对应,掌握此节对于Spark在任务执行过程中的资源分配会更上一层楼。由于源码部分太多本节只抽取关键部分和结论阐述,更多的偏于应用。
二、具体细节
1、Spark-Submit提交参数
Options:
- --master
MASTER_URL, 可以是spark://host:port, mesos://host:port, yarn, yarn-cluster,yarn-client, local
- --deploy-mode
DEPLOY_MODE, Driver程序运行的地方,client或者cluster,默认是client。
- --class
CLASS_NAME, 主类名称,含包名
- --jars
逗号分隔的本地JARS, Driver和executor依赖的第三方jar包(Driver是把算子中的逻辑发送到executor中去执行,所以如果逻辑需要依赖第三方jar包 比如oreacl的包时 这里用--jars添加)
- --files
用逗号隔开的文件列表,会放置在每个executor工作目录中
- --conf
spark的配置属性
- --driver-memory
Driver程序使用内存大小(例如:1000M,5G),默认1024M
- --executor-memory
每个executor内存大小(如:1000M,2G),默认1G
Spark standalone with cluster deploy mode only:
- --driver-cores
Driver程序的使用core个数(默认为1),仅限于Spark standalone模式
Spark standalone or Mesos with cluster deploy mode only:
- --supervise
失败后是否重启Driver,仅限于Spark alone或者Mesos模式
Spark standalone and Mesos only:
- --total-executor-cores
executor使用的总核数,仅限于SparkStandalone、Spark on Mesos模式
Spark standalone and YARN only:
- --executor-cores
每个executor使用的core数,Spark on Yarn默认为1,standalone默认为worker上所有可用的core。
YARN-only:
- --driver-cores
driver使用的core,仅在cluster模式下,默认为1。
- --queue
QUEUE_NAME 指定资源队列的名称,默认:default
- --num-executors
一共启动的executor数量,默认是2个。
2、资源调度源码分析
- 资源请求简单图
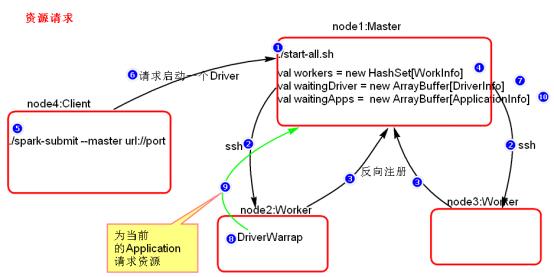
- 资源调度Master路径:

路径:spark-1.6.0/core/src/main/scala/org.apache.spark/deploy/Master/Master.scala
- 提交应用程序,submit的路径:

路径:spark-1.6.0/core/src/main/scala/org.apache.spark/ deploy/SparkSubmit.scala
- 总结:
- Executor在集群中分散启动,有利于task计算的数据本地化。
- 默认情况下(提交任务的时候没有设置--executor-cores选项),每一个Worker为当前的Application启动一个Executor,这个Executor会使用这个Worker的所有的cores和1G内存。
- 如果想在Worker上启动多个Executor,提交Application的时候要加--executor-cores这个选项。
- 默认情况下没有设置--total-executor-cores,一个Application会使用Spark集群中所有的cores。设置多少个用多少。
- 结论演示
集群中总资源如下:
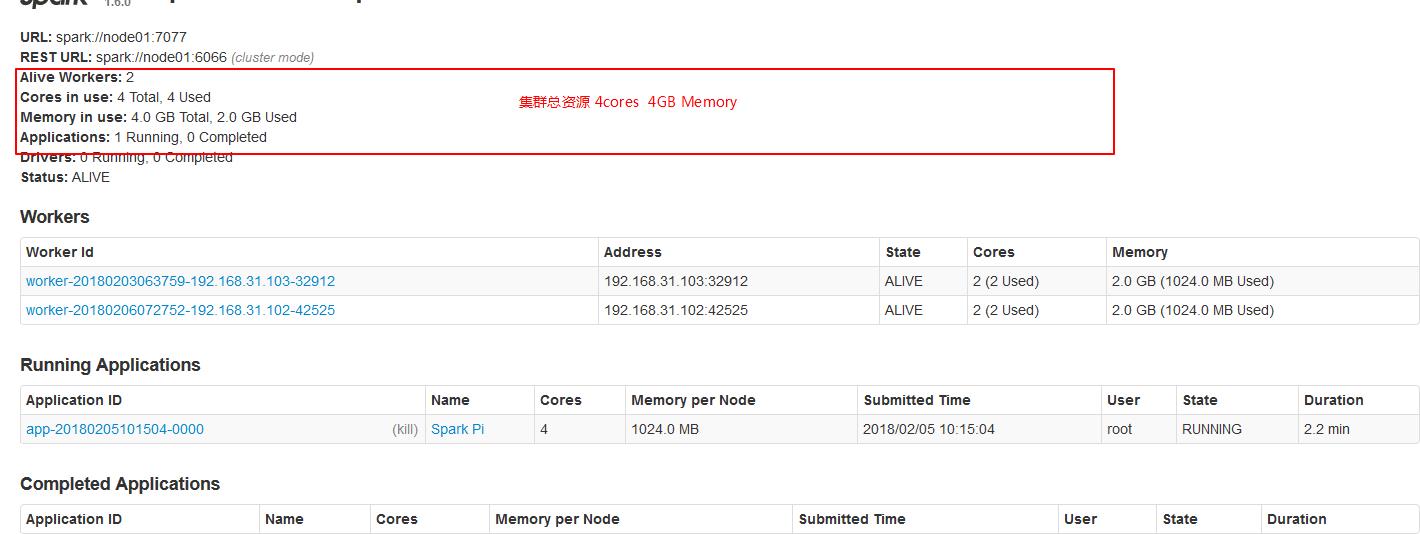
使用Spark-submit提交任务演示。也可以使用spark-shell
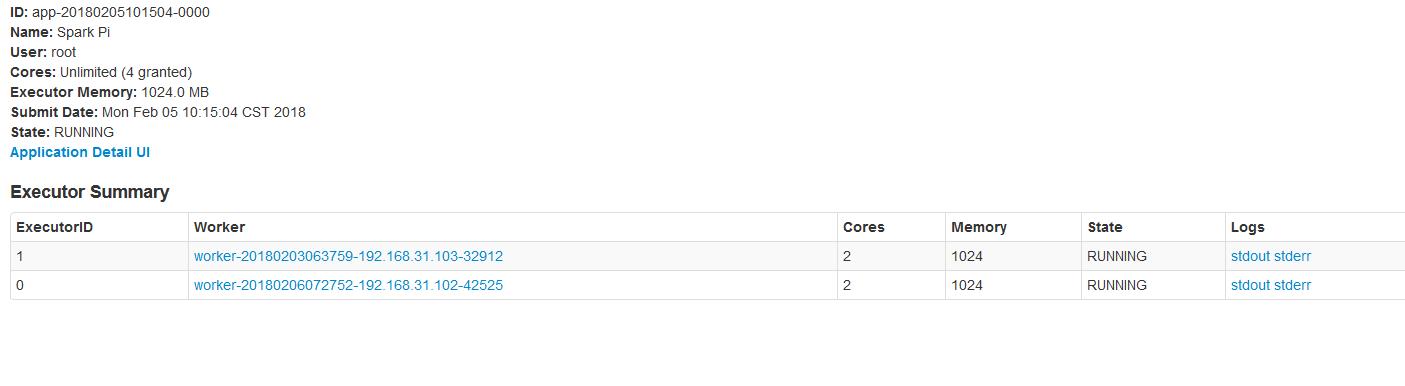
2.1、默认情况每个worker为当前的Application启动一个Executor,这个Executor使用集群中所有的cores和1G内存。
./spark-submit --master spark://node01:7077 --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.6.0.jar 10000

2.2、在workr上启动多个Executor,设置--executor-cores参数指定每个executor使用的core数量。
./spark-submit --master spark://node01:7077 --executor-cores 1 --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.6.0.jar 10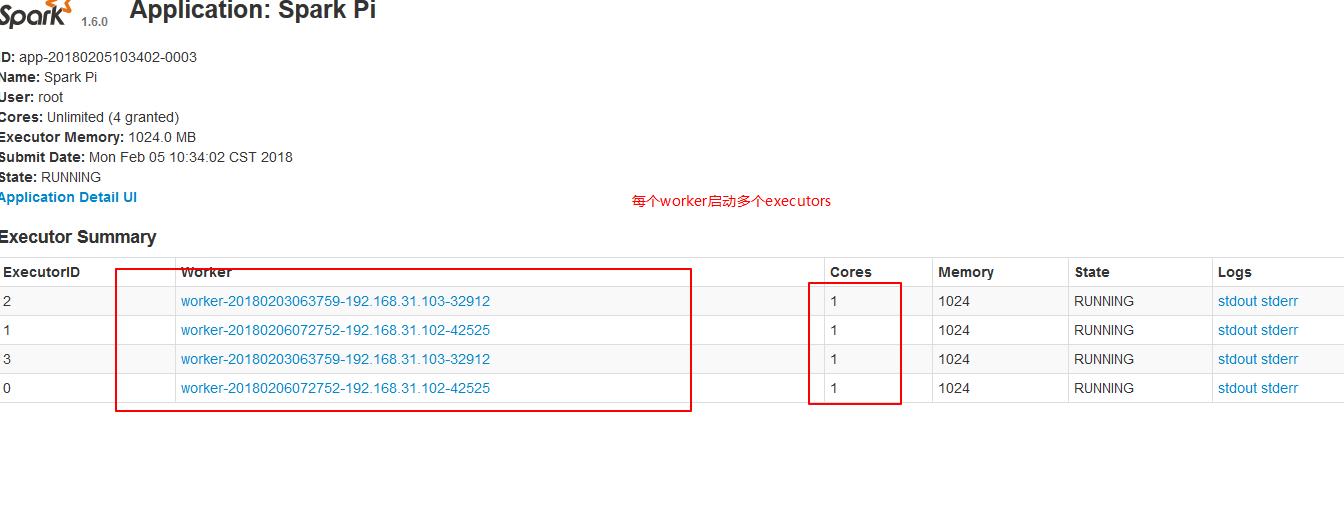
2.3、内存不足的情况下启动core的情况。Spark启动是不仅看core配置参数,也要看配置的core的内存是否够用。
./spark-submit --master spark://node01:7077 --executor-cores 1 --executor-memory 3g --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.6.0.jar 10000
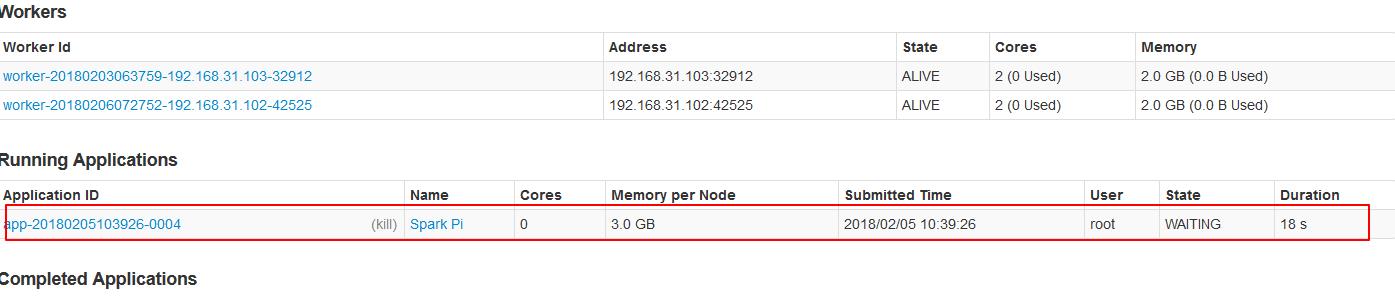

可见并没有启动起来,因为内存不够。。。
./spark-submit --master spark://node01:7077 --executor-cores 1 --executor-memory 2g --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.6.0.jar 10000
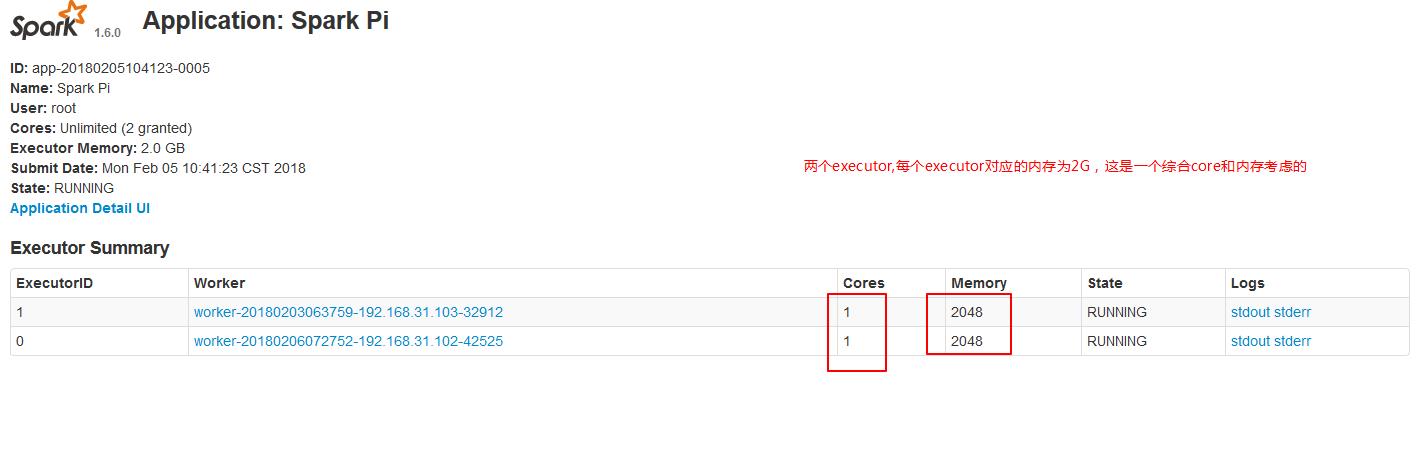
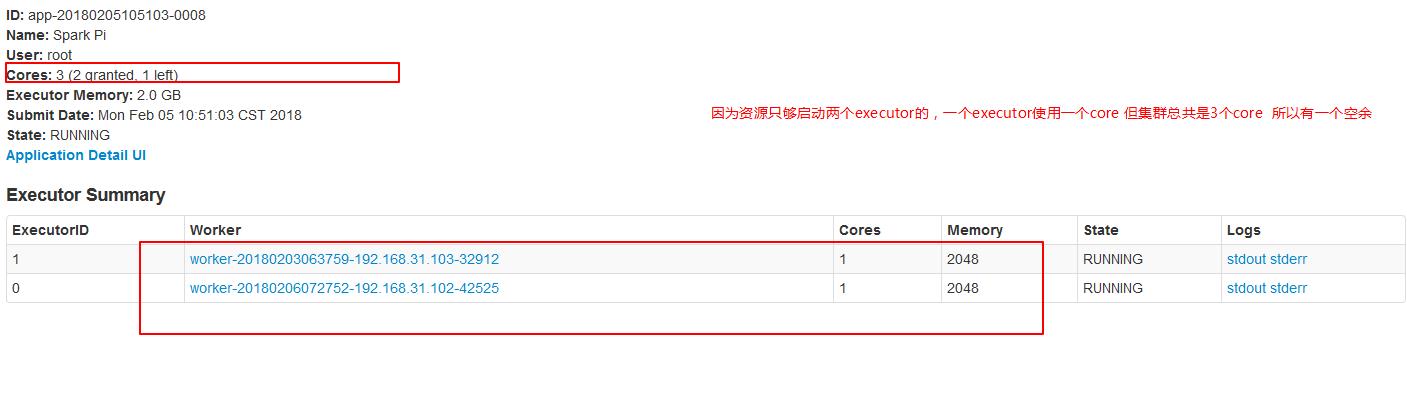
2.4、--total-executor-cores集群中共使用多少cores
注意:一个进程不能让集群多个节点共同启动。
./spark-submit --master spark://node01:7077 --executor-cores 1 --executor-memory 2g --total-executor-cores 3 --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.6.0.jar 10000
./spark-submit --master spark://node01:7077 --executor-cores 1 --executor-memory 1g --total-executor-cores 3 --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.6.0.jar 200
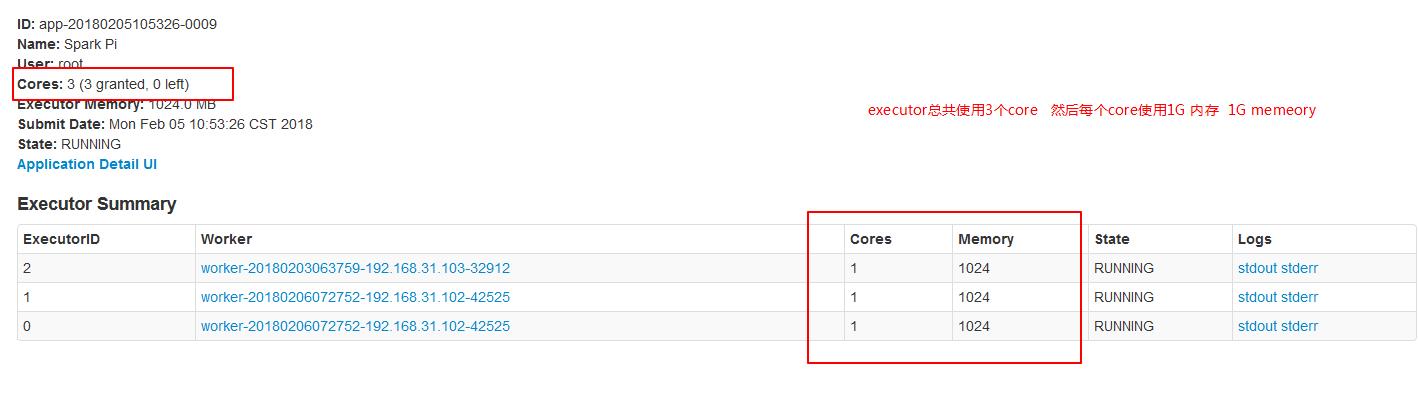
./spark-submit --master spark://node01:7077 --executor-cores 1 --executor-memory 2g --total-executor-cores 3 --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.6.0.jar 200
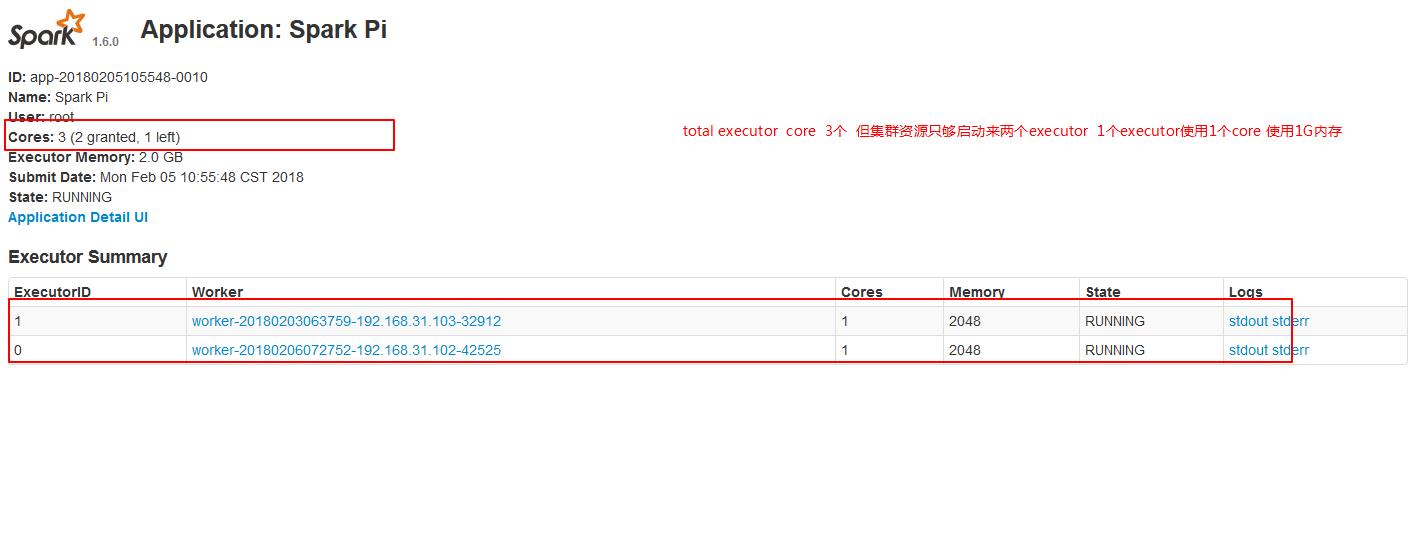
注意:生产环境中一定要加上资源的配置 因为Spark是粗粒度调度资源框架,不指定的话,默认会消耗所有的cores!!!!
3 、任务调度源码分析
- Action算子开始分析
任务调度可以从一个Action类算子开始。因为Action类算子会触发一个job的执行。
- 划分stage,以taskSet形式提交任务
DAGScheduler 类中getMessingParentStages()方法是切割job划分stage。可以结合以下这张图来分析:
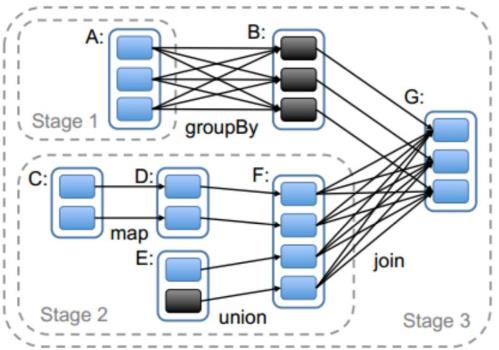
以上是关于Spark篇---Spark中资源调度源码分析与应用的主要内容,如果未能解决你的问题,请参考以下文章
Spark资源调度机制源码分析--基于spreadOutApps及非spreadOutApps两种资源调度算法
小记--------spark资源调度机制源码分析-----Schedule
Spark调研笔记第3篇 - Spark集群相应用的调度策略简单介绍