一个cpu在运作的时候采用切片法,因此一个cpu在微观角度只能处理一个进程,现在的处理器大多是4核,可以同时处理4个任务,
在开启进程的时候操作系统需要给这个进程分配空间,地址等配指,这是很耗费时间的,所以在操作系统中,有数据池得概念,数据池中有几个进程由cpu决定
比如如果有4核那就有4个进程,当这4个进程有一个结束时就由外面等候的新进程替换,新进程不会重新开通空间而是沿用数据池已有的进程配置来达到节省时间提高效率的目的
import time from multiprocessing import Pool def func(i): i += 1 if __name__ == ‘__main__‘: p = Pool(5) # 创建了5个进程 start = time.time() p.map(func,range(1000)) # target = func args=next(iterable) # [(1,2,3),1,2,3,4] p.close() # 是不允许再向进程池中添加任务 p.join() print(time.time() - start) start = time.time()
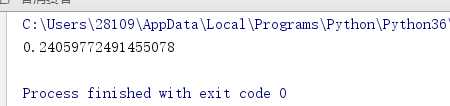
使用数据池后他生成执行100个线程只用了0.2s
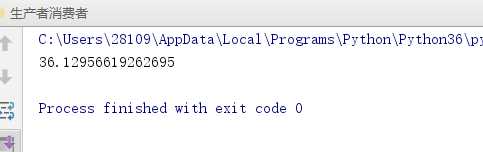
如果不使用数据池的话
import time from multiprocessing import Pool from multiprocessing import Process def func(i): i += 1 if __name__ == ‘__main__‘: # p = Pool(5) # 创建了5个进程 start = time.time() # p.map(func,range(1000)) # target = func args=next(iterable) # [(1,2,3),1,2,3,4] # p.close() # 是不允许再向进程池中添加任务 # p.join() # print(time.time() - start) # start = time.time() l = [] for i in range(1000): p = Process(target=func,args=(i,)) # 创建了一百个进程 p.start() l.append(p) [i.join() for i in l] print(time.time() - start)