基于HBase的MapReduce实现大量邮件信息统计分析
Posted 黎明踏浪
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于HBase的MapReduce实现大量邮件信息统计分析相关的知识,希望对你有一定的参考价值。
一:概述
在大多数情况下,如果使用MapReduce进行batch处理,文件一般是存储在HDFS上的,但这里有个很重要的场景不能忽视,那就是对于大量的小文件的处理(此处小文件没有确切的定义,一般指文件大小比较小,比如5M以内的文件),而HDFS的文件块一般是64M,这将会影响到HDFS的性能,因为小文件过多,那么NameNode需要保存的文件元信息将占用更多的空间,加大NameNode的负载进而影响性能,假如对于每个文件,在NameNode中保存的元数据大小是100字节,那么1千万这样的小文件,将占用10亿byte,约1G的内存空间,目前有以下几种对于众多小文件的处理方法:
HAR File方式,将小文件合并成大文件
SequenceFile方式,以文件名为key,文件内容为value,生成一个序列文件
以HBase作为小文件的存储,rowkey使用文件名,列族单元保存文件内容,文件后缀名等信息
在本文中的案例,就是采用第三种方法
二:实现
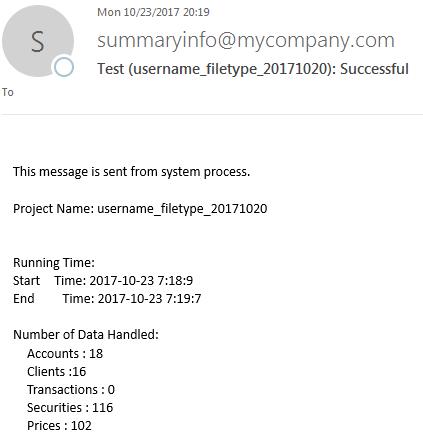
1:邮件格式如下,为了简单起见及安全性,这里作了简化,每一封这样的邮件,大小将近15k左右
2:HBase表
需要创建2张HBase表格,一张保存邮件文件,另外一张保存MapReduce的输出结果,在hbase shell中分别创建:
create \'email\', {NAME=>\'f1\', VERSIONS=>2}
create \'summary\', {NAME=>\'f1\', VERSIONS=>2}
3:邮件文件导入到HBase中
请参考上篇文章 将文件以API方式导入到HBase(小文件处理),此处,假设是把所有的每天已经生产的邮件文件,从本地导入到HBase中,另外一种方案是创建一个独立的RESTful API,供第三方程序调用,将邮件信息写入到HBase中
4:MapReduce
- 在IDEA中创建Maven工程
- 修改pom.xml文件,添加依赖hbase-client及hbase-server
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>mronhbase</groupId> <artifactId>mronhbase</artifactId> <version>1.0-SNAPSHOT</version> <repositories> <repository> <id>apache</id> <url>http://maven.apache.org</url> </repository> </repositories> <dependencies> <dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-client</artifactId> <version>1.2.6</version> </dependency> <dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-server</artifactId> <version>1.2.6</version> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <executions> <!-- Run shade goal on package phase --> <execution> <phase>package</phase> <goals> <goal>shade</goal> </goals> <configuration> <filters> <filter> <!-- Do not copy the signatures in the META-INF folder. Otherwise, this might cause SecurityExceptions when using the JAR. --> <artifact>*:*</artifact> <excludes> <exclude>META-INF/*.SF</exclude> <exclude>META-INF/*.DSA</exclude> <exclude>META-INF/*.RSA</exclude> </excludes> </filter> </filters> <createDependencyReducedPom>false</createDependencyReducedPom> </configuration> </execution> </executions> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <configuration> <source>1.8</source> <target>1.8</target> </configuration> </plugin> </plugins> </build> </project>
- 创建java类,先引入必要的包:
package examples; import java.io.IOException; import java.util.Iterator; import java.util.regex.Matcher; import java.util.regex.Pattern; import org.apache.hadoop.hbase.io.ImmutableBytesWritable; import org.apache.hadoop.hbase.util.Bytes; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil; import org.apache.hadoop.hbase.client.*; import org.apache.hadoop.hbase.mapreduce.TableMapper; import org.apache.hadoop.hbase.mapreduce.TableReducer; import org.apache.hadoop.mapreduce.Job;
- 类文件hbasemr,其中包含主程序入口
public class hbasemr { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { String hbaseTableName1 = "email"; String hbaseTableName2 = "summary"; Configuration conf = new Configuration(); Job job = Job.getInstance(conf); job.setJarByClass(hbasemr.class); job.setJobName("mronhbase"); Scan scan = new Scan(); scan.setCaching(500); scan.setCacheBlocks(false); TableMapReduceUtil.initTableMapperJob(hbaseTableName1, scan, MyMapper.class, Text.class, IntWritable.class, job); TableMapReduceUtil.initTableReducerJob(hbaseTableName2, MyReducer.class, job); System.exit(job.waitForCompletion(true) ? 1 : 0); } public static String getSubString(String value,String rgex){ Pattern pattern = Pattern.compile(rgex); Matcher m = pattern.matcher(value); while(m.find()){ return m.group(1); } return ""; } }
- 添加Mapper类及Reducer类:
Hbases实现了TableMapper类及TableReducer类,
创建MyMapper
public static class MyMapper extends TableMapper<Text, IntWritable>{ private final static IntWritable one = new IntWritable(1); public void map(ImmutableBytesWritable key, Result value, Context context) throws IOException,InterruptedException { String rowValue = Bytes.toString(value.getValue("f1".getBytes(),"message".getBytes())); if(rowValue !=null) { String rgex = "Project Name:(.*?)\\\\r\\\\n"; String temp = hbasemr.getSubString(rowValue,rgex); String username = temp.substring(0, temp.indexOf(\'_\')); rgex = "Accounts:(.*?)\\\\r\\\\n"; String count = hbasemr.getSubString(rowValue,rgex).trim(); IntWritable intCount = new IntWritable(Integer.parseInt(count)); context.write(new Text(username), intCount); } } }
创建MyReducer:
public static class MyReducer extends TableReducer<Text,IntWritable, NullWritable> { private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; Iterator<IntWritable> item = values.iterator(); while (item.hasNext()) { sum += item.next().get(); } this.result.set(sum); Put put = new Put(key.toString().getBytes()); put.addColumn("f1".getBytes(), "count".getBytes(), String.valueOf(sum).getBytes()); context.write(NullWritable.get(), put); } }
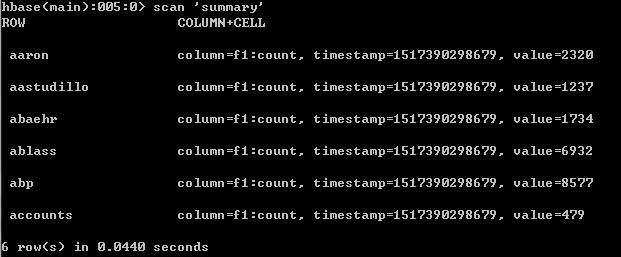
5:运行与调试
启动Hadoop及HBase,在IDEA 中对MyMapper类及MyReducer类设置好断点,以调试方式运行程序,运行完后,进入到hbase shell查看运行结果
以上是关于基于HBase的MapReduce实现大量邮件信息统计分析的主要内容,如果未能解决你的问题,请参考以下文章