ng机器学习视频笔记(十六) ——从图像处理谈机器学习项目流程
Posted lin_h
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ng机器学习视频笔记(十六) ——从图像处理谈机器学习项目流程相关的知识,希望对你有一定的参考价值。
ng机器学习视频笔记(十六)
——从图像处理谈机器学习项目流程
(转载请附上本文链接——linhxx)
一、概述
这里简单讨论图像处理的机器学习过程,主要讨论的是机器学习的项目流程。采用的业务示例是OCR(photo optical character recognition,照片光学字符识别),通过一张照片,识别出上面所有带字符的内容。
二、机器学习流水线
对于一个业务项目,通常机器学习是其中一部分的内容,对于整个项目而言,相当于一个流水线(pipeline)。
对于OCR,主要流水线为:1-获取照片->2-字符串区域识别->3-字符串分割->4字符辨认->5-输出结果。其中2~4步都是对结果非常重要的步骤。如下图所示:

三、滑动窗口
滑动窗口(sliding windows),通过指定大小的方框,从图片左上角开始,扫描全图,旨在最终识别出需要的内容,如字符串,并用明显的颜色标出。
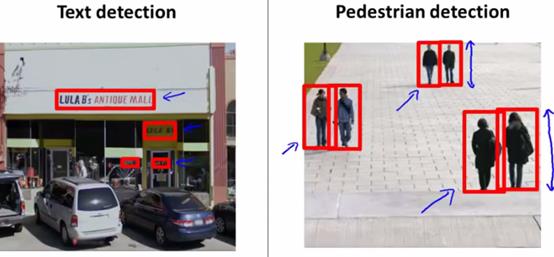
1、行人识别
下面先讨论行人识别。
1)监督学习
下面进行监督学习,指定图像的像素是82*36,给出一些这样大小的图片且里面有行人的,标记为分类结果是1;再给一些这样大小的图片,里面没有行人,分类结果标记为0。将这些数据进行监督学习,让机器懂得判断82*36像素的图片,是否有行人。

2)滑动窗口
首先,用82*36像素,从图像左上角开始,扫描全图,每次右移的位置是一个参数,这个参数设置太小虽然很精确,但是会很慢,通常设置为2~5像素。到达最右边后,会回到最左边,并稍稍往下,再进行第二行的扫描,同样,往下的像素也是一个参数。
接着,用比82*36大一些的像素,进行扫描全图(大多少同样是参数设定)。但是这里要注意的是,每次取到一块图,要压缩到82*36像素,给前面步骤训练好的分类器进行判别。

2、字符识别
1)监督学习
同样,选一些有字符的标记为1,没字符的标记为0,进行监督学习。

2)滑动窗口
同样使用滑动窗口进行检测,区别之处在于,把识别的结果重新生成一幅灰白黑图,颜色越白表示该区域是字符的概率越大,白色表示肯定是字符,黑色表示肯定不是,灰色的深浅表示可能性(如果旁边还有白色,则可能判定为也是字符)。
接着,输出结果乘以一个膨胀算子(expand operator),这样可以放大结果,让白色更白,黑色更黑,以便于识别结果。
最后再抛弃一些不规则的矩形,剩下的就认为是识别到的字符。

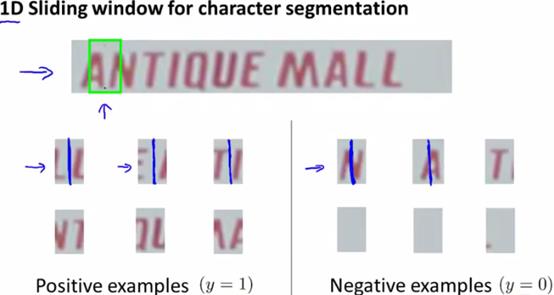
3、字符分割
字符分割,也用到滑动窗口技术,但是这里称为一维滑动窗口,因为固定了长宽,就一次性扫描一行内容(每次移动的边界还是需要设定的参数)。
这里的监督学习,用到的是学习判断图的正中间是否是字符的边界,对于是边界的则画上一条竖线,标记分割完成。如下图所示:
四、人工数据合成
对于机器学习,如果数据不够多,可以考虑使用人工数据合成(artificial data synthesis),即可以理解为“造数据”。但是,造数据也不是随意造的,主要做的工作有以下几点。
1、取各种字体
字体多种多样,在一些网站有开源的字体,里面每个字符都有大量的样式,这就需要对机器进行训练,以便其识别到各种样式的字体,如下图所示:

2、字符扭曲
由于照片上的字未必是方方正正的,因此字符扭曲很重要,让机器识别出各种扭曲的字符,其也是正确的字符,这样有助于提高识别率,如下图所示:

3、注意事项
这里的造数据,要考虑到造数据的有效性,即需要的是模拟出各种有可能的情况,而不是仅仅加入一些无意义的噪声。例如下图的第一个内容,字符扭曲,对于识别就有好处;而第二个内容,只是对字符加入一些随机的小噪声,这样对于识别就没有太大用处。

五、上限分析
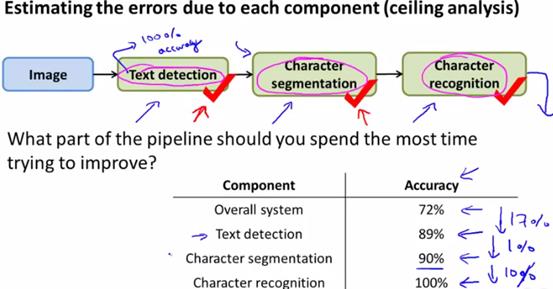
当一个机器学习流水线项目完成,评估后发现正确率不符合预期要求,此时需要考虑对流水线的内容进行优化。但是,流水线的步骤繁多,不可能全盘优化,因此,就需要用到上限分析(ceiling analysis)的分析方案。
上限分析类似生物学到的控制变量法,通过逐个控制流水线的不确定因素,来衡量如果将某个步骤优化到100%精确度,对于整个系统精确度的提升会有多少。
1、串行流水线
考虑到串行流水线,假设最终的算法结果的精确度是72%。
做法:
1)对于流水线的每个步骤,从第一个步骤开始,不使用算法,而是直接人工给出第一步应该有的、100%正确的结果,此时再看整个系统的精确度。通过计算此时系统精确度与原始系统精确度的差,可以判断出如果将第一步优化到完美,对整个系统精确度的提升能有多少。
注意:衡量精确度要用同样的计算方式。
2)接着,在第一步的基础上,将第二个步骤也直接给出应有的结果,查看此时的精确度,减去第一步的系统精确度,得出将第二步优化到最佳,对系统精确度的提升的贡献度。
3)以此类推,直到计算出每一步的精确度的改进范围,将最需要改进的步骤着重进行优化改进。
如下图所示:
2、并行流水线
对于机器学习,某些步骤需要并行完成,此时同样可以计算精确度,而且用的方式和串行完全一样,不赘述,如下图所示:

六、总结

这里是对整个视频课程的总结,在视频课程中,主要分为监督学习、无监督学习、机器学习应用、机器学习技巧四个部分内容,在学习过程中,我认为最有难度的部分,在于BP算法、SVM算法这两个算法的数学推导论证过程,目前我觉得我只达到基本明白的程度,后续还要加强学习。
机器学习的算法很巧妙,而且非常有趣,拓宽了我的思维,另外也让我更有信心继续后面的学习。
七、感悟
到此为止,学完吴恩达的coursera的机器学习课程,113集,大致20个小时的课程,历时32天(其间我同时完成《机器学习实战》前六章的课程编程与学习),有种终于要正式开始了的感觉。
这里仅仅是入门,可能甚至只是还在门边初探机器学习的内容。
接下来,视频课程部分,我计划学习吴恩达的深度学习微专业;书籍部分,我会先学完《机器学习实战》,接着开始周志华的《机器学习》(俗称西瓜书),巩固机器学习的内容。至于TF框架、机器学习的具体方向、深度学习花书以及其他各种视频、书籍等内容,后续会持续进行。
2018,加油~
——written by linhxx
更多最新文章,欢迎关注微信公众号“决胜机器学习”,或扫描右边二维码。
以上是关于ng机器学习视频笔记(十六) ——从图像处理谈机器学习项目流程的主要内容,如果未能解决你的问题,请参考以下文章