ng机器学习视频笔记 ——过拟合与正则化
Posted lin_h
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ng机器学习视频笔记 ——过拟合与正则化相关的知识,希望对你有一定的参考价值。
ng机器学习视频笔记(五)
——过拟合与正则化
(转载请附上本文链接——linhxx)
一、过拟合和欠拟合
1、概念
当针对样本集和特征值,进行预测的时候,推导θ、梯度下降等,都在一个前提,原值假设函数(hypnosis function)h(x)的表达式,例如是一阶、二阶还是更高阶等。
当阶数不足导致无法正确预测时,称为欠拟合(underfit)或高偏差(high bias);当阶数太高,虽然能满足样本集,代价函数也接近0,但是仍不是一个好的预测函数,称为过拟合(overfitting)或高方差(high variance)。
例如根据房子的面积预测房价,欠拟合、正常情况、过拟合分别如下面三个图所示:
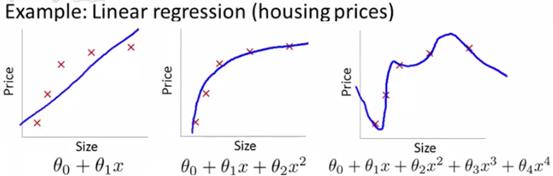
过拟合的情况比较明显,在只有一个影响因素的情况下,因为面积增到导致价格减少是不现实的,虽然满足了所有的样本集,但是这个模型是不正确的。
logistic回归同样有类似问题:
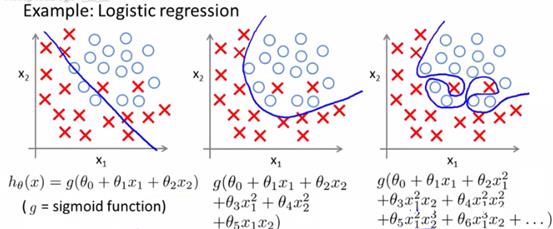
2、过拟合存在问题
过拟合主要是因为特征值太多、阶数太高引起,如果样本集数量不够,没法有效的进行训练,会导致预测的结果存在较大偏差,模型无法使用。
二、解决过拟合方案
1、画图,并根据图像判断是否正确,如上面的例子。这个只有在影响因素很少的情况下可行,因素多时,维度高,不容易图形表示,也不容易通过图形判断是否正确。
2、减少不必要的特征值,特别是重复的特征(如用平方米和平方尺两个特征计算面积)。可以通过人工选择或模型选择算法(model selection algorithm,后面会学到)来实现。但是,这样可能会导致损失一些特征信息。
3、通过正则化(regularization)的方式实现。这种方式,不需要损失任何特征值。
三、正则化
1、基本思路
当一个式子有四个特征值,且明显后两个特征值并不重要,则可以如下设代价函数:
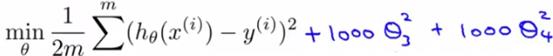
这样,后面两个特征值由于被加了平方项,导致值需要非常小,才可以让整个代价函数很小。
2、正则化思路
当无法确认哪些特征值是不重要的时候,则应该使用正则化,其主要思想是通过减小所有的θ,这样可以获得更简单的h(x),阶数更低;另外,也更不容易出现过度拟合的现象。
3、步骤
1)列出原先线性回归情况下的代价函数
2)改成以下公式
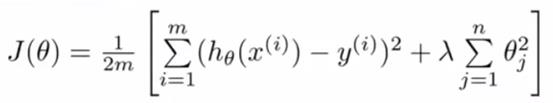
分析上面的公式,可以看出,代价函数加入了θ的平方项,这样使得要让代价函数值尽量小,就应该要每个θ都尽量小。
另外,上面的式子中,对θ的处理从1~n,而θ0并没有参与正则化处理。
其中,带λ的项,称为正则化项;λ称为正则化参数。该参数目的在于平衡训练集更好参与训练同时让θ都尽量小,最终达到获得更简单的h(x),阶数更低。
需要注意的是,如果λ太大,例如10的10次方,则由于每个θ都太小,接近于0,导致h(x)约等于θ0,会出现欠拟合。
四、线性回归正则化
线性回归可以使用梯度下降和标准方程法,分别讨论如下:
1、梯度下降算法
根据上面的代价函数的公式,易得梯度下降算法需要迭代的方程如下:
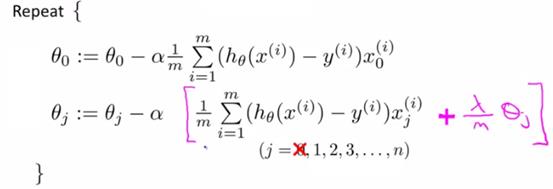
其中,θ0由于不参与正则化,单独列出来。
化简上面的θj的式子,把θj提取出来,公式变换如下:
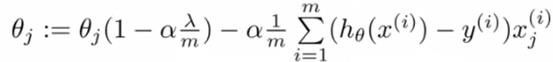
从上式与正则化之前的梯度下降算法对比,实际上就是θj多乘了一个(1-α*λ/m),这个值略小于1,因此达到减小θj的目的。
2、标准方程法
对于标准方程法,正则化则需要加入下面括号带λ的这一项,这样从θ1~θm都被λ进行调整了。
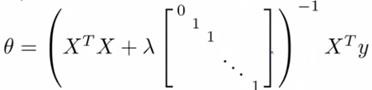
之前讨论过XTX有可能不可逆的情况,但是已经经过数学论证,正则化后,只要λ>0,整个括号内的项必然可逆。
因此,正则化是解决标准方程法XTX有可能存在不可逆的方法之一。
五、logistic回归正则化
logistic回归的算法,实际上基本公式和线性回归的梯度下降法是一样的,只不过其h(x)不同,带入对应的h(x),得到logistic回归的代价函数如下公式:
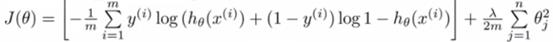
——written by linhxx
更多最新文章,欢迎关注微信公众号“决胜机器学习”,或扫描右边二维码。
以上是关于ng机器学习视频笔记 ——过拟合与正则化的主要内容,如果未能解决你的问题,请参考以下文章