R-创建数据集-ch2
Posted evayao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R-创建数据集-ch2相关的知识,希望对你有一定的参考价值。
1、数据集的概念
R的数据结构:包括标量、向量、矩阵、数组、数据框和列表;
R的数据类型:包括数值型、字符型、逻辑型(TRUE/FALSE)、复数型(虚数)和原生型(字节);
不同的行业对于数据集的行和列叫法不同。统计学家称它们为观测(observation)和变量(variable),数据库分析师称记录和字段,数据挖掘和机器学习叫示例和属性。
2、数据的结构
对象(object)是指可以赋值给变量的任何事物,包括常量、数据结构、函数,甚至图形。
名义型变量或有序型变量称为因子(factor),它们在R中被特殊地存储和处理。
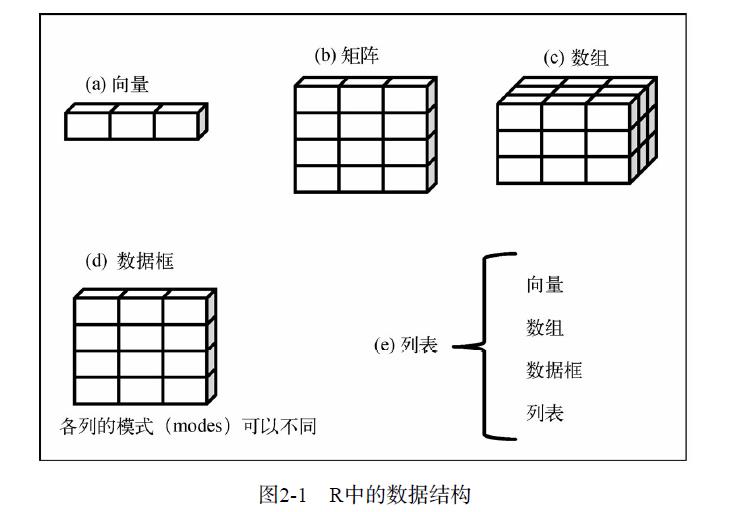
2.1 标量
标量是只含一个元素的向量,例如f <- 3,用于保存常量。
2.2 向量
向量是用于存储数值型、字符型或逻辑型数据的一维数组。执行组合功能的函数c()可用来创建向量。单个向量中的数据必须拥有相同的类型。
注:访问向量中的元素,访问一个直接写元素所在序号,访问多个需要带着函数c()。

2.3 矩阵
矩阵是一个二维数组,只是每个元素都拥有相同的模式(数值型、字符型或逻辑型)。可通过函数matrix创建矩阵。一般使用格式为:
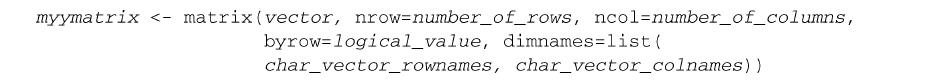
其中vector包含了矩阵的元素,nrow和ncol用以指定行和列的维数,dimnames包含了可选的、以字符型向量表示的行名和列名。选项byrow则表明矩阵应当按行填充(byrow=TRUE)还是按列填充(byrow=FALSE),默认情况下按列填充。
使用下标和方括号来选择矩阵中的行、列或元素。
X[i,]指矩阵X中的第i 行,
X[,j]指第j 列,X[i, j]指第i 行第j 个元素,
选择多行或多列时,下标i 和j 可为数值型向量。例:y<-matrix y[c(1,3),c(1,3)]
2.4 数组
数组(array)与矩阵类似,数组中的数据也只能拥有一种模式,但是维度可以大于2。数组可通过array函数创建,形式如下:
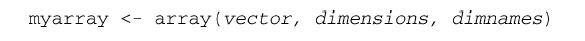
其中vector包含了数组中的数据,dimensions是一个数值型向量,给出了各个维度下标的最大值,而dimnames是可选的、各维度名称标签的列表。
2.5 数据框
数据框是R中最常处理的数据结构,不同的列可以包含不同模式(数值型、字符型等)的数据。
数据框可通过函数data.frame()创建:
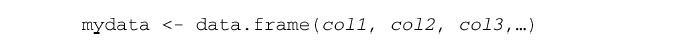
其中的列向量col1, col2, col3,… 可为任何类型(如字符型、数值型或逻辑型)
选取数据框中元素的方法:
(1)利用下标、列名查询

为了避免每次都写 数据框$列名 这样的格式冗杂,采取下面的方法:
(2)attach()、detach()
函数attach()可将数据框添加到R的搜索路径中,函数detach()将数据框从搜索路径中移除
局限性:函数attach()和detach()最好在你分析一个单独的数据框,并且不太可能有多个同名对象时使用。
(3)with()
函数with()的局限性在于,赋值仅在此函数的括号内生效。

2.6因子
名义型变量是没有顺序之分的类别变量,有序型变量表示一种顺序关系,而非数量关系。
类别(名义型)变量和有序类别(有序型)变量在R中称为因子(factor)。因子在R中非常重要,因为它决定了数据的分析方式以及如何进行视觉呈现。
函数factor()以一个整数向量的形式存储类别值,整数的取值范围是[1... k ](其中k 是名义型变量中唯一值的个数),同时一个由字符串(原始值)组成的内部向量将映射到这些整数上。(不太懂?)
例:status<-c("poor","improved","excellent","poor")
把status指定为一个普通因子: status<-factor(status)
把status指定为一个有序因子:在函数factor()中加入order参数,order=TRUE表示默认按字母顺序排序。
想指定水平排序顺序,则为:

函数str(object)可以提供某个对象object的信息,此处提供因子status各水平的赋值。excellent=1,improved=2,poor=3
2.7列表
列表(list)是R的数据类型中最为复杂的一种,可以使用函数list()创建列表:

可以通过在双重方括号中指明代表某个成分的数字或名称来访问列表中的元素。
由于两个原因,列表成为了R中的重要数据结构。首先,列表允许以一种简单的方式组织和重新调用不相干的信息。其次,许多R函数的运行结果都是以列表的形式返回的。
注:R中的下标不是从0开始,而是从1开始;变量无法被声明,它们在首次被赋值时生成。
3、数据的输入
向R中导入数据的权威指南参见可在http://cran.r-project.org/doc/manuals/R-data.pdf下载的R Data Import/Export手册,中文名《R数据的导入和导出》。
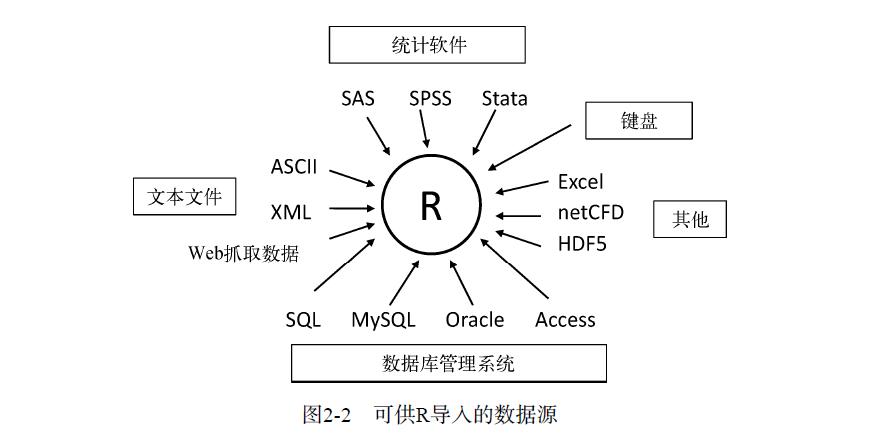
3.1 使用键盘输入数据
R中的函数edit()会自动调用一个允许手动输入数据的文本编辑器。具体步骤如下:
(1) 创建一个空数据框(或矩阵),其中变量名和变量的模式需与理想中的最终数据集一致;
(2) 针对这个数据对象调用文本编辑器,输入你的数据,并将结果保存回此数据对象中。

注:newobject <- edit(object) 编辑对象并另存为newobject
fix(object) 直接编辑对象
*以
3.2 从带分隔符的文本文件导入数据
使用read.table()从带分隔符的文本文件中导入数据。此函数可读入一个表格格式的文件并将其保存为一个数据框。其语法如下:

例子中,file为"studentgrade.csv"。在导入文本文件前,先切换到文本文件所在的工作目录,使用setwd("工作目录")函数
请注意,参数sep允许你导入那些使用逗号以外的符号来分隔行内数据的文件。你可以使用sep="\\t"读取以制表符分隔的文件。此参数的默认值为sep="",即表示分隔符可为一个或多个空格、制表符、换行符或回车符。
3.3 导入excel数据
方法一:将excel文件导出为一个逗号分隔文件(csv),利用3.2的方法。
导出的方法是在另存为中操作。

方法二:安装xlsx包出现错误? 如果能安装载入成功,用函数read.xlsx(file, n)即可,其中file是Excel 2007工作簿的所在路径,n则为要导入的工作表序号。
3.4 导入XML数据
3.5 从网页抓取数据
3.6 导入SPSS数据
3.7 导入SAS数据
3.8 导入Stata数据
3.11 访问数据库管理系统
等等
4、 数据集的标注
5、 处理数据对象的实用函数
以上是关于R-创建数据集-ch2的主要内容,如果未能解决你的问题,请参考以下文章