Spark机器学习系列之13: 支持向量机SVM
Posted 大葱拌豆腐
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark机器学习系列之13: 支持向量机SVM相关的知识,希望对你有一定的参考价值。
Spark 优缺点分析
以下翻译自Scikit。
The advantages of support vector machines are:
(1)Effective in high dimensional spaces.在高维空间表现良好。
(2)Still effective in cases where number of dimensions is greater than the number of samples.在数据维度大于样本点数时候,依然可以起作用
(3)Uses a subset of training points in the decision function (called support vectors), so it is also memory efficient.仅仅使用训练数据的一个子集(支持向量),因此是内存友好型的算法。
(4)Versatile: different Kernel functions can be specified for the decision function. Common kernels are provided, but it is also possible to specify custom kernels.适应广,能解决多种情况下的分类问题,这是由于它支持不同类型的核函数,甚至支持自定义的核函数。
能灵活使用多种核函数的确使得SVM变得非常强大,而核函数相关的理论很深奥,初步的探讨可参考转载的一篇文章:http://blog.csdn.net/qq_34531825/article/details/52895621
The disadvantages of support vector machines include:
(1)If the number of features is much greater than the number of samples, the method is likely to give poor performances.在数据维度(特征个数)多于样本数很多的时候,通常只能训练出一个表现很差的模型。
(2)SVMs do not directly provide probability estimates, these are calculated using an expensive five-fold cross-validation (see Scores and probabilities, below).SVM不支持直接进行概率估计,Scikit中使用很耗费资源的5折交叉检验来估计概率。
Spark Mllib


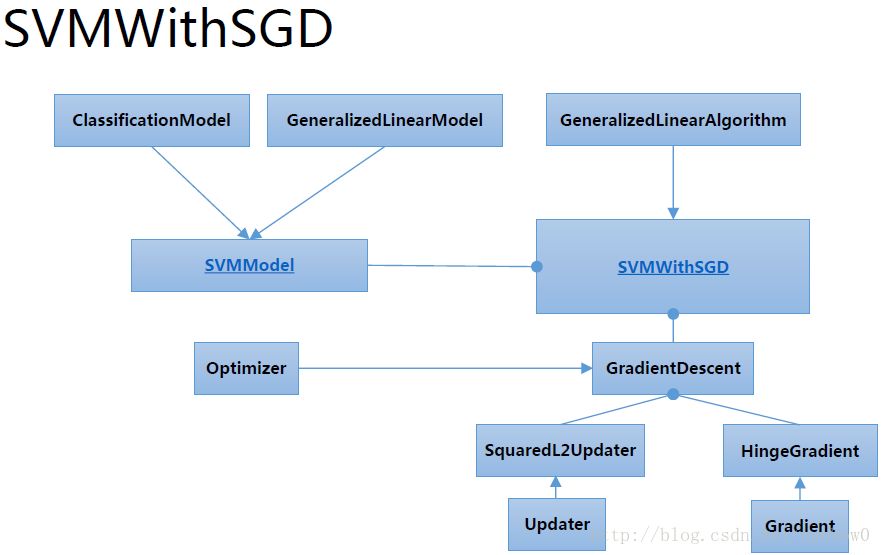
import org.apache.spark.{SparkConf,SparkContext} import org.apache.log4j.{Level, Logger} import org.apache.spark.mllib.classification.{SVMModel,SVMWithSGD} import org.apache.spark.mllib.evaluation.BinaryClassificationMetrics import org.apache.spark.mllib.util.MLUtils import org.apache.spark.SparkConf import org.apache.spark.SparkContext import org.apache.spark.mllib.optimization.L1Updater import org.apache.spark.mllib.optimization.SquaredL2Updater object mySVM { def main(args:Array[String]){ //屏蔽日志 Logger.getLogger("org.apache.spark").setLevel(Level.ERROR) Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF) val conf=new SparkConf().setMaster("local").setAppName("My App") val sc=new SparkContext(conf) // Load training data in LIBSVM format. val data = MLUtils.loadLibSVMFile(sc, "/data/mllib/sample_libsvm_data.txt") //println(data.collect()(0))//检查数据 // Split data into training (60%) and test (40%). val splits = data.randomSplit(Array(0.6, 0.4), seed = 11L) val training = splits(0).cache() val test = splits(1) // Run training algorithm to build the model /* * stepSize: 迭代步长,默认为1.0 * numIterations: 迭代次数,默认为100 * regParam: 正则化参数,默认值为0.0 * miniBatchFraction: 每次迭代参与计算的样本比例,默认为1.0 * gradient:HingeGradient (),梯度下降; * updater:SquaredL2Updater (),正则化,L2范数; * optimizer:GradientDescent (gradient, updater),梯度下降最优化计算。 */ val svmAlg=new SVMWithSGD() svmAlg.optimizer .setNumIterations(100) .setRegParam(0.1)//正则化参数 .setUpdater(new L1Updater) val modelL1=svmAlg.run(training) // Clear the default threshold. modelL1.clearThreshold() // Compute raw scores on the test set. val scoreAndLabels = test.map { point => val score = modelL1.predict(point.features) (score, point.label)//return score and label } // Get evaluation metrics. val metrics = new BinaryClassificationMetrics(scoreAndLabels) val auROC = metrics.areaUnderROC() println("Area under ROC = " + auROC) } }
参考文献
(1) 支持向量机通俗导论(理解SVM的三层境界) http://blog.csdn.net/v_july_v/article/details/7624837
(2)Spark MLlib SVM算法(源代码分析)http://www.itnose.net/detail/6267193.html
(3)Spark官网与Scikit官网
(4)LIBSVM: A Library是 for Support Vector Machines , Chih-Chung Chang and Chih-Jen Lin,Department of Computer Science National Taiwan University, Taipei, Taiwan http://www.csie.ntu.edu.tw/~cjlin/papers/libsvm.pdf
(5)A Tutorial on Support Vector Regression Alex J. Smola† and Bernhard Scholkopf
(6)如何解决机器学习中数据不平衡问题 http://www.zhaokv.com/2016/01/learning-from-imbalanced-data.html
(7)不平衡数据下的机器学习方法简介 http://www.jianshu.com/p/3e8b9f2764c8
(8)核函数 http://blog.csdn.net/xiaojiegege123456/article/details/7728198,xiaojiegege123456 CSDN 对核函数有一个比较容易的理解的介绍
(9)http://www.cnblogs.com/zxb1990/p/5098345.html SVM学习笔记(二)—-手写数字识别 贴近实际应用一些
(10)http://www.cnblogs.com/jerrylead/archive/2011/03/18/1988406.html
(11)RBF 参数 http://scikit-learn.org/stable/auto_examples/svm/plot_rbf_parameters.html
以上是关于Spark机器学习系列之13: 支持向量机SVM的主要内容,如果未能解决你的问题,请参考以下文章