链表
链表是一种根据元素节点逻辑关系排列起来的一种数据结构。利用链表可以保存多个数据,这一点类似于数组的概念,但是数组本身有一个缺点 —— 数组的长度固定,不可改变,在长度固定的情况下首选的肯定是数组,但是在现实的开发之中往往要保存的内容长度是不确定的,那么此时就可以利用链表这样的结构来代替数组的使用。
链表的基本形式
链表是一种最为简单的数据结构,它的主要目的是依靠引用关系来实现多个数据的保存,那么下面假设现在要保存的数据是字符串(引用类型),则可以按照图所示的关系进行保存。
Node类
所有要保存的数据都会被包装到一个节点对象之中,之所以会引用一个节类,是因为只依靠保存的数据无法区分出先后顺序,而引入了Node类可以包装数据以及指向下一个节点,所以在Node类的设计中主要保存两个属性:数据(data)与下一个节点引用(next)
范例:定义一个Node类
class Node { // 每一个链表实际上就是由多个节点所组成的
private String data; // 要保存的数据
private Node next; // 要保存的下一个节点
/**
* 每一个Node类对象都必须保存有相应的数据
* @param data 要通过节点包装的数据
*/
public Node(String data) { // 必须有数据才有Node
this.data = data;
}
//setter、getter略
}
链表数据取出
在进行链表操作的时候,首先需要的是一个根节点(第一个节点即为根节点),之后每一个节点的引用都保存在上一节点的next属性之中,而在进行输出的时候也应该按照节点的先后顺序,一个一个取得每一个节点所包装的数据
范例:手工配置节点关系,并使用while循环输出全部节点数据
public class LinkDemo {
public static void main(String args[]) {
// 第一步:定义要操作的节点以及设置好包装的字符串数据
Node root = new Node("火车头") ;// 定义节点,同时包装数据
Node n1 = new Node("车厢A") ; // 定义节点,同时包装数据
Node n2 = new Node("车厢B") ; // 定义节点,同时包装数据
root.setNext(n1) ; // 设置节点关系
n1.setNext(n2) ; // 设置节点关系
// 第二步:根据节点关系取出所有数据
Node currentNode = root ; // 当前从根节点开始读取
while (currentNode != null) { // 当前节点存在有数据
System.out.println(currentNode.getData()) ;
currentNode = currentNode.getNext() ;// 将下一个节点设置为当前节点
}
}
}
程序执行结果:
火车头
车厢A
车厢B
程序执行步骤
本程序一共分为了三个操作步骤进行:
- 第1步:定义各个独立的节点,同时封装要保存的字符串数据;
- 第2步:配置不同节点彼此之间的操作关系;
- 第3步:由于现在不清楚要输出的节点个数,只知道输出的结束条件(没有节点就不输出了,curentNode == null)所以使用while循环,依次取得每一个节点,并输出里面包装的数据。
范例:手工配置节点关系,通过递归输出全部节点数据
public class LinkDemo {
public static void main(String args[]) {
// 第一步:定义要操作的节点以及设置好包装的字符串数据
Node root = new Node("火车头") ; // 定义节点,同时包装数据
Node n1 = new Node("车厢A") ; // 定义节点,同时包装数据
Node n2 = new Node("车厢B") ; // 定义节点,同时包装数据
root.setNext(n1) ; // 设置节点关系
n1.setNext(n2) ; // 设置节点关系
print(root) ; // 由根节点开始输出
}
/**
* 利用递归方式输出所有的节点数据
* @param current
*/
public static void print(Node current) {// 第二步:根据节点关系取出所有数据
if (current == null) { // 递归结束条件
return; // 结束方法
}
System.out.println(current.getData());// 输出节点包含的数据
print(current.getNext()); // 递归操作
}
}
程序执行结果:
火车头 车厢A 车厢B
链表的基本雏形
通过之前的分析,可以发现链表实现之中最为重要的类就是Node,而以上程序都是由用户自己去使用Node类封装要操作的数据,同时由用户自己去匹配节点关系,很明显,这样会给用户操作带来更多的复杂性,而用户实际上只关心链表之中保存的数据有那些,至于说数据是如何保存的,节点间的关系是如何分配的,用户完全不需要知道,所以此时应该定义一个专门负责这个节点操作的类,而这个类可以称为链表操作类 —— Link,专门负责处理节点关系,用户不需要关心节点问题,只需要关心Link的处理操作即可。
链表操作步骤

链表的基础功能
范例:链表的基本开发结构
class Link { // 链表类,外部能够看见的只有这一个类
private class Node { // 定义的内部节点类
private String data; // 要保存的数据
private Node next; // 下一个节点引用
public Node(String data) { // 每一个Node类对象都必须保存有相应的数据
this.data = data;
}
}
// ===================== 以上为内部类 ===================
private Node root; // 根节点定义
}
在本结构中将Node定义为了Link的私有内部类,这样做有两个好处:
- Node类只会为Link类服务,并且可以利用Node类匹配节点关系;
- 外部类与内部类之间方便进行私有属性的直接访问,所以不需要在Node类中定义setter、getter方法。
数据增加:public void add(数据类型 变量)
class Link { // 链表类,外部能够看见的只有这一个类
private class Node { // 定义的内部节点类
private String data; // 要保存的数据
private Node next; // 下一个节点引用
public Node(String data) { // 每一个Node类对象都必须保存有相应的数据
this.data = data;
}
/**
* 设置新节点的保存,所有的新节点保存在最后一个节点之后
* @param newNode 新节点对象
*/
public void addNode(Node newNode) {
if (this.next == null) { // 当前的下一个节点为null
this.next = newNode ; // 保存节点
} else { // 向后继续保存
this.next.addNode(newNode) ;
}
}
}
数据增加:public void add(数据类型 变量)
// ===================== 以上为内部类 ===================
private Node root; // 根节点定义
/**
* 用户向链表增加新的数据,在增加时要将数据封装为Node类,这样才可以匹配节点顺序
* @param data 要保存的数据
*/
public void add(String data) { // 假设不允许有null
if (data == null) { // 判断数据是否为空
return; // 结束方法调用
}
Node newNode = new Node(data); // 要保存的数据
if (this.root == null) { // 当前没有根节点
this.root = newNode; // 保存根节点
} else { // 根节点存在
this.root.addNode(newNode); // 交给Node类处理节点的保存
}
}
}
取得保存元素个数:public int size()
private int count = 0 ; // 保存元素的个数
/**
* 用户向链表增加新的数据,在增加时要将数据封装为Node类,这样才可以匹配节点顺序
* @param data 要保存的数据
*/
public void add(String data) { // 假设不允许有null
if (data == null) { // 判断数据是否为空
return; // 结束方法调用
}
Node newNode = new Node(data); // 要保存的数据
if (this.root == null) { // 当前没有根节点
this.root = newNode; // 保存根节点
} else { // 根节点存在
this.root.addNode(newNode); // 交给Node类处理节点的保存
}
this.count ++ ; // 数据保存成功后保存个数加一
}
public int size() { // 取得保存的数据量
return this.count;
}
判断是否是空链表:public boolean isEmpty()
所谓的空链表(不是null)指的是链表之中不保存任何的数据,空链表判断实际上可以通过两种方式完成:
第一种:判断root有对象(是否为null);
第二种:判断保存的数据量(count)。
/**
* 判断是否是空链表,表示长度为0,不是null
* @return 如果链表中没有保存任何的数据则返回true,否则返回false
*/
public boolean isEmpty() {
return this.count == 0;
}
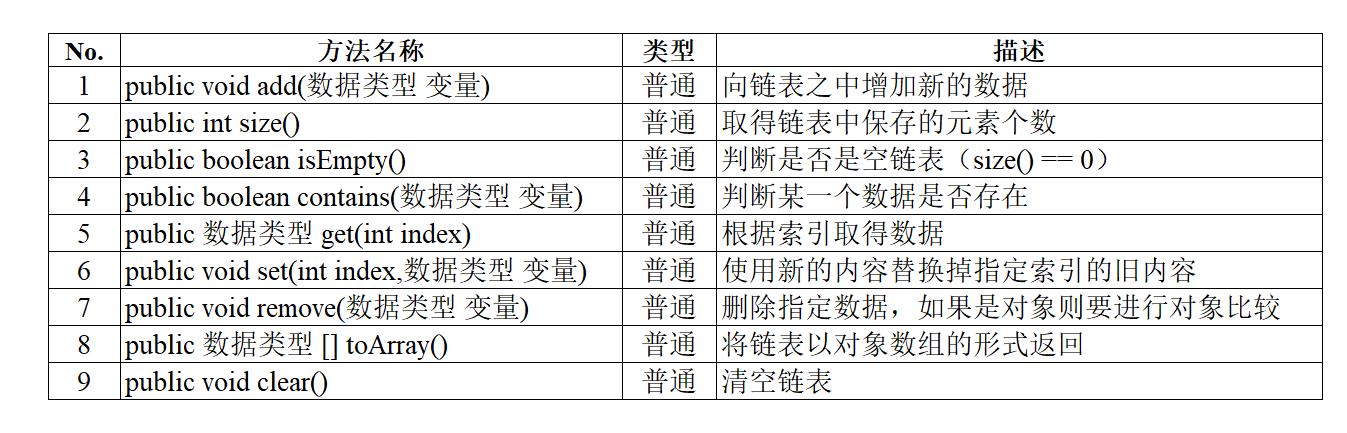
数据查询:public boolean contains(数据类型 变量)
在链表之中一定会保存有多个数据,那么基本的判断数据是否存在的方式。以:String为例(equals()方法判断),在判断一个字符串是否存在时需要循环链表中的全部内容,并且与要查询的数据进行匹配,如果查找到了则返回true,否则返回false
范例:在Node类增加方法
/**
* 数据检索操作,判断指定数据是否存在
* 第一次调用(Link):this = Link.root
* 第二次调用(Node):this = Link.root.next
* @param data 要查询的数据
* @return 如果数据存在返回true,否则返回false
*/
public boolean containsNode(String data) {
if (data.equals(this.data)) { // 当前节点数据为要查询的数据
return true; // 后面不再查询了
} else { // 当前节点数据不满足查询要求
if (this.next != null) { // 有后续节点
return this.next.containsNode(data);// 递归调用继续查询
} else { // 没有后续节点
return false; // 没有查询到返回false
}
}
}
范例:修改Link
/**
* 数据查询操作,判断指定数据是否存在,如果链表没有数据直接返回false
* @param data 要判断的数据
* @return 数据存在返回true,否则返回false
*/
public boolean contains(String data) {
if (data == null || this.root == null) { // 现在没有要查询的数据,根节点也不保存数据
return false ; // 没有查询结果
}
return this.root.containsNode(data) ; // 交由Node类查询
}
根据索引取得数据:public 数据类型 get(int index)
链表本身就属于一种动态的对象数组,与普通的对象数组相比最大的优势就在于没有长度限制。那么既然链表属于动态对象数组,也就应该具备像数组那样可以根据索引取得元素的功能,自然也就能根据指定索引取得指定节点数据的操作

范例:在Link类添加处理程序
范例:在Link类里面增加一个foot的属性,表示每一个Node元素的编号
private int foot = 0 ; // 节点索引
范例:在每一次查询的时候(一个链表可能查询多次),那么foot应该在每一次查询时都从头开始计算(foot设为0);
/**
* 根据索引取得保存的节点数据
* @param index 索引数据
* @return 如果要取得的索引内容不存在或者大于保存个数返回null,反之返回数据
*/
public String get(int index) {
if (index > this.count) { // 超过了查询范围
return null ; // 没有数据
}
this.foot = 0 ; // 表示从前向后查询
return this.root.getNode(index) ; // 查询过程交给Node类
}
范例:在Node类里面实现getNode()方法
/**
* 根据索引取出数据,此时该索引一定是存在的
* @param index 要取得数据的索引编号
* @return 返回指定索引节点包含的数据
*/
public String getNode(int index) {
// 使用当前的foot内容与要查询的索引进行比较,随后将foot的内容自增,目的是为了下次查询方便
if (Link.this.foot++ == index) { // 当前为要查询的索引
return this.data; // 返回当前节点数据
} else { // 继续向后查询
return this.next.getNode(index); // 进行下一个节点的判断
}
}
修改指定索引内容:public void set(int index,数据类型 变量)
/**
* 修改指定索引节点包含的数据
* @param index 要修改的索引编号
* @param data 新数据
*/
public void setNode(int index, String data) {
// 使用当前的foot内容与要查询的索引进行比较,随后将foot的内容自增,目的是为了下次查询方便
if (Link.this.foot++ == index) { // 当前为要修改的索引
this.data = data; // 进行内容的修改
} else {
this.next.setNode(index, data);// 继续下一个节点的索引判断
}
}
范例:在Link类里面增加set()方法
/**
* 根据索引修改数据
* @param index 要修改数据的索引编号
* @param data 新的数据内容
*/
public void set(int index, String data) {
if (index > this.count) { // 判断是否超过了保存范围
return; // 结束方法调用
}
this.foot = 0; // 重新设置foot属性的内容,作为索引出现
this.root.setNode(index, data); // 交给Node类设置数据内容
}
数据删除:public void remove(数据类型 变量)
对于链表之中的内容,之前完成的是增加操作和查询操作,但是从链表之中也会存在删除数据的操作,可是删除数据的操作需要分两种情况讨论。
情况一:
要删除的数据是根节点,则root应该变为“根节点.next”(根节点的下一个节点为新的根节点),并且由于根节点需要被Link类所,所以此种情况要在Link类中进行处理
情况二:
要删除的不是根节点,而是其它的普通节点,这个时候删除节点的操作应该放在Node类里处理,并且由于Link类已经判断过根节点,所以此处应该从第二个节点开始判断的

范例:在Node类里面增加一个removeNode()方法
/**
* 节点的删除操作,匹配每一个节点的数据,如果当前节点数据符合删除数据,
* 则使用“当前节点上一节点.next = 当前节点.next”方式空出当前节点
* 第一次调用(Link),previous = Link.root、this = Link.root.next
* 第二次调用(Node),previous = Link.root.next、this = Link.root.next.next
* @param previous 当前节点的上一个节点
* @param data 要删除的数据
*/
public void removeNode(Node previous, String data) {
if (data.equals(this.data)) { // 当前节点为要删除节点
previous.next = this.next; // 空出当前节点
} else { // 应该向后继续查询
this.next.removeNode(this, data); // 继续下一个判断
}
}
范例:在Link类里面增加根节点的判断
/**
* 链表数据的删除操作,在删除前要先使用contains()判断链表中是否存在有指定数据
* 如果要删除的数据存在则首先判断根节点的数据是否为要删除数据
* 如果是则将根节点的下一个节点作为新的根节点
* 如果要删除的数据不是根节点数据,则将删除操作交由Node类的removeNode()方法完成
* @param data 要删除的数据
*/
public void remove(String data) {
if (this.contains(data)) { // 主要功能是判断数据是否存在
// 要删除数据是否是根节点数据,root是Node类的对象,此处直接访问了内部类的私有操作
if (data.equals(this.root.data)) { // 根节点数据为要删除数据
this.root = this.root.next; // 空出当前根节点
} else { // 根节点数据不是要删除数据
// 此时根元素已经判断过了,从第二个元素开始判断,即第二个元素的上一个元素为根节点
this.root.next.removeNode(this.root, data);
}
this.count--; // 删除成功后个数要减少
}
}
将链表变为对象数组:public 数据类型 [] toArray()
对于链表的这种数据结构,在实际的开发之中,最为关键的是两个操作:增加数据、取得全部数据,而链表本身属于一种动态的对象数组,所以在链表输出时,最好的做法是将链表中所保存的数据以对象数组的方式返回,而这个返回的对象数组长度也应该是根据保存数据的个数来决定的
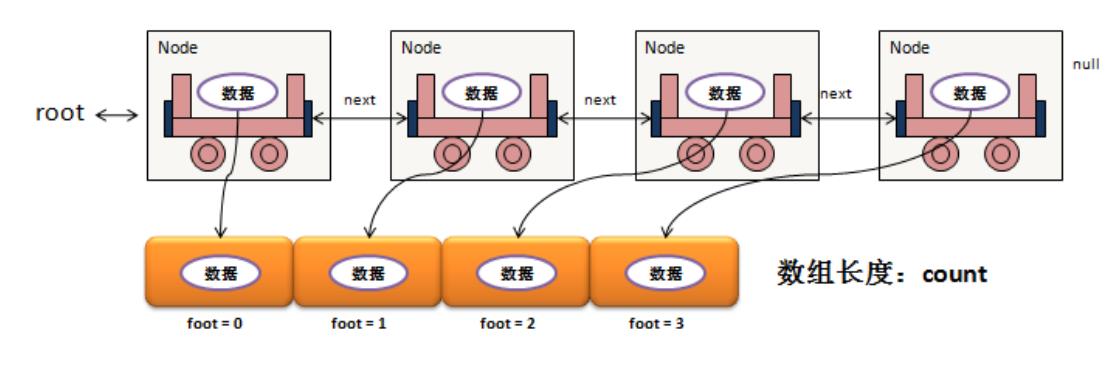
范例:修改Link类的定义
增加一个返回的数组属性内容,之所以将其定义为属性,是因为内部类和外部类都可以访问;
private String [] retArray ; // 返回的数组
增加toArray()方法。
/**
* 将链表中的数据转换为对象数组输出
* @return 如果链表没有数据返回null,如果有数据则将数据变为对象数组后返回
*/
public String[] toArray() {
if (this.root == null) { // 判断链表是否有数据
return null; // 没有数据返回null
}
this.foot = 0; // 脚标清零操作
this.retArray = new String[this.count]; // 根据保存内容开辟数组
this.root.toArrayNode(); // 交给Node类处理
return this.retArray; // 返回数组对象
}
范例:在Node类里面处理数组数据的保存
/**
* 将节点中保存的内容转化为对象数组
* 第一次调用(Link):this = Link.root;
* 第二次调用(Node):this = Link.root.next;
*/
public void toArrayNode() {
Link.this.retArray[Link.this.foot++] = this.data; // 取出数据并保存在数组之中
if (this.next != null) { // 有后续元素
this.next.toArrayNode(); // 继续下一个数据的取得
}
}
清空链表:public void clear()
public void clear() {
this.root = null; // 清空链表
this.count = 0; // 元素个数为0
}