数据结构
Posted 不会起名字
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据结构相关的知识,希望对你有一定的参考价值。
数据结构 定义:简单来说,数据结构就是设计数据以何种方式组织并存储在计算机中。比如:列表、集合与字典等都是一种数据结构。 PS:“程序=数据结构+算法” 列表:在其他编程语言中称为“数组”,是一种基本的数据结构类型。 关于:列表的存储问题!
数据结构的分类:
线性结构:数据结构中的元素存在一对一的相互关系
树结构:数据结构中的元素存在一对多的相互关系
图结构:数据结构中的元素存在多对多的相互关系
栈: 栈(Stack)是一个数据集合,可以理解为只能在一端进行插入或删除操作的列表。 栈的特点:后进先出(last-in, first-out) 栈的概念: 栈顶 栈底 栈的基本操作: 进栈(压栈):push 出栈:pop 取栈顶:gettop

#利用python简单的实现栈操作
class Stack(object): def __init__(self): self.stack=[] def isEmpty(self): return self.stack==[] def push(self,item): self.stack.append(item) def pop(self): if self.isEmpty(): raise IndexError,\'pop from empty stack\' return self.stack.pop() def peek(self): return self.stack[-1] def size(self): return len(self.stack)
栈的应用——括号匹配问题
括号匹配问题:给一个字符串,其中包含小括号、中括号、大括号,求该字符串中的括号是否匹配。
例如:
()()[]{} 匹配
([{()}]) 匹配
[]( 不匹配
[(]) 不匹配
def Matching(exp="{[()]}"): stack = [] for i in exp: if i in {\'(\',\'[\',\'{\'}: stack.append(i) if i == \')\': if len(stack)>0 and stack[-1] == \'(\': stack.pop() else: return False if i == \']\': if len(stack)>0 and stack[-1] == \'[\': stack.pop() else: return False if i == \'}\': if len(stack)>0 and stack[-1] == \'{\': stack.pop() else: return False if len(stack)==0: return True else: return False
队列 队列(Queue)是一个数据集合,仅允许在列表的一端进行插入,另一端进行删除。 进行插入的一端称为队尾(rear),插入动作称为进队或入队 进行删除的一端称为队头(front),删除动作称为出队 队列的性质:先进先出(First-in, First-out) 双向队列:队列的两端都允许进行进队和出队操作。

队列实现: 使用方法:from collections import deque 创建队列:queue = deque(li) 进队:append 出队:popleft 双向队列队首进队:appendleft 双向队列队尾进队:pop 队列的实现原理 普通队列: 初步设想:列表+两个下标指针 创建一个列表和两个变量,front变量指向队首,rear变量指向队尾。初始时,front和rear都为0。 进队操作:元素写到li[rear]的位置,rear自增1。 出队操作:返回li[front]的元素,front自减1。

环形队列: 改进方案:将列表首尾逻辑上连接起来。 环形队列:当队尾指针front == Maxsize + 1时,再前进一个位置就自动到0。 实现方式:求余数运算 队首指针前进1:front = (front + 1) % MaxSize 队尾指针前进1:rear = (rear + 1) % MaxSize 队空条件:rear == front 队满条件:(rear + 1) % MaxSize == front
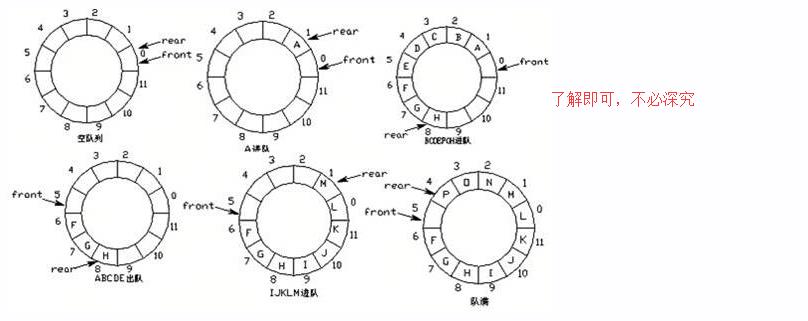
队列的内置模块:
使用方法:from collections import deque 创建队列:queue = deque(li) 进队:append 出队:popleft 双向队列队首进队:appendleft 双向队列对尾出队:pop
链表:
链表中的每一个元素都是一个对象,每个对象称之为一个节点,包含有数据域key和指向下一个节点的指针next。通过各个节点之间的相互连接,最终串联成一个链表。 节点定义: class Node(object): def __init__(self,item): self.item = item self.next = None

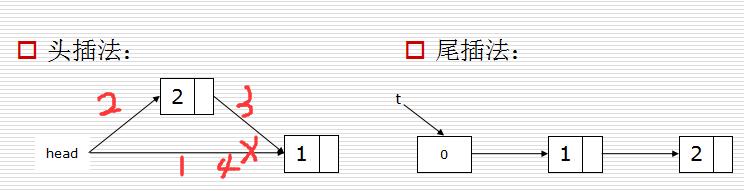
建立链表有两种方式(头插法和尾插法):
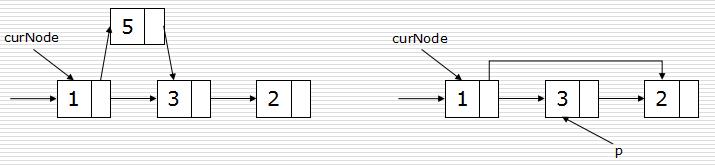
链表可以有遍历操作: 链表节点的插入和删除: 1、插入 p.next = curNode.next #要插入的下一个为curNode的下一个,也就是3 curNode.next = p #curNode的下一个为p,也就是刚刚插入的那个, 2、删除 p = curNode.next #p为curNode的下一个节点 curNode.next = curNode.next.next #curNode的下一个节点=curNode.next.next(变相的赋值) del p #最后删除中间那个碍眼的家伙
双向链表:
定义:双链表中的每个节点都有两个指针:一个指向后边的节点、一个指向前面的节点。 代码定义: class Node(object): def __init__(self,item=None): self.item = item #当前节点 self.next = None #下一个 self.prior = None #前一个

双链表节点的插入和删除(感觉很绕) 插入: p.next = curNode.next #p的下一个=curNode的下一个 curNode.next.prior = p #curNode的下一个的前一个=p p.prior = curNode #q的前一个就是curNode curNode.next = p #之后curNode的下一个就是p 删除: p = curNode.next #p是curNode的下一个 curNode.next = p.next #赋值 curNode的下一个就是p的下一个 p.next.prior = curNode #p的下一个的前一额就是curNode del p #删除p,赋值成功

链表-复杂度分析:
列表与链表:
暗元素值查找
按下表查找
在某元素后插入
删除某元素
哈希表:
哈希表(hash table,又称为散列表),是一种线性表的存储结构。哈希表有一个顺序表(也就是数组)和一个哈希函数组成(哈希函数就是加密算法,顺序表就是加密后的值)。
哈希函数h(k) 将元素k作为自变量,返回元素的存储下标。 简单的哈希函数: 除法哈希:h(k) = k mod m #对m取余 乘法哈希:h(k) = floor(m(kA mod 1)) 0<A<1
假设有一个长度为7的数组,河西函数h(k) = K%7.元素集合{14,22,3,5}的存储方式如下图(制作图片链接https://visualgo.net/en)。

哈希冲突: 由于哈希表的大小是有限的,而要存储的值得总数量是无线的,因此对于任何哈希函数,都会出现两个不同的元素映射到同一个位置上的情况,这种情况就叫做哈希冲突。 解决哈希冲突--开放寻址法: 开放寻址法:如果哈希函数返回的位置已经有值,则可以向后探查新的位置来存储这个值。 线性探查:如果位置i被占用,则探查i+1,i+2····· 二次探查:如果位置i被占用,则探查i+1²,i-1²,i+2²··· 二度哈希:有n个哈希函数,当使用第一个哈希函数h1发生冲突时,则尝试使用h3,h3等
拉链法:哈希表每个位置都链接一个链表,当冲突发生时,冲突的元素讲被加到该位置链表的最后(图示略)
哈希表在python中的应用
字典与集合都是通过哈希表来实现的 在python中的字典; ls = {"name":"username","password":"password"} 使用哈希表存储字典,通过哈希函数将字典的键映射为下标 在字典键值对数量不多的情况下,几乎不会发生类似于哈希冲突,此时查找一个元素的时间复杂度为O(1)
二叉树:
二叉树的链式存储:将二叉树的节点定义为一个对象,节点之间通过类似链表的链接方式来链接。 节点定义: class BiTreeNode(object): def __init__(self,data): self.data = data self.lchild = None #左边的孩纸 self.rchild = None #右边的孩纸 二叉树的遍历方式: 前序遍历: 中序遍历: 后序遍历: 层次遍历:
from collections import deque
class BiTreeNode:
def __init__(self, data):
self.data = data
self.lchild = None
self.rchild = None
a = BiTreeNode(\'A\')
b = BiTreeNode(\'B\')
c = BiTreeNode(\'C\')
d = BiTreeNode(\'D\')
e = BiTreeNode(\'E\')
f = BiTreeNode(\'F\')
g = BiTreeNode(\'G\')
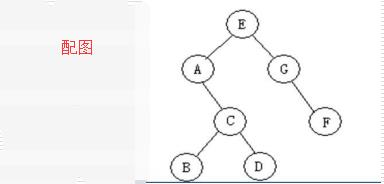
e.lchild = a
e.rchild = g
a.rchild = c
c.lchild = b
c.rchild = d
g.rchild = f
root = e
#前序遍历
def pre_order(root):
if root:
print(root.data, end=\'\')
pre_order(root.lchild)
pre_order(root.rchild)
#中序遍历
def in_order(root):
if root:
in_order(root.lchild)
print(root.data, end=\'\')
in_order(root.rchild)
#后续遍历
def post_order(root):
if root:
post_order(root.lchild)
post_order(root.rchild)
print(root.data, end=\'\')
#层次遍历
def level_order(root):
queue = deque()
queue.append(root)
while len(queue) > 0:
node = queue.popleft()
print(node.data,end=\'\')
if node.lchild:
queue.append(node.lchild)
if node.rchild:
queue.append(node.rchild)
pre_order(root)
print("")
in_order(root)
print("")
post_order(root)
print("")
level_order(root)
遍历完之后比对他们的打印结果你会发现都是不同的
二叉搜索树:
二叉搜索树是一颗二叉树且满足性质: 设x是二叉树的一个节点。如果y是x左子树的一个节点,那么y.key<= x.key; 如果y是x右子树的一个节点,那么y.key>=x.key. 二叉搜索树的创建 二叉搜索树的遍历(采用中序序列遍历) 二叉搜索树的查询、插入、删除操作 ps:随机化的二叉搜索树,AVL树
AVL树:avl树是一个自平衡的二叉搜索树。
具有的性质:
根的左右子树的高度之差的绝对值不能超过1
根的左右子树都是平衡二叉树
AV领的实现方式:旋转(在我上边留的网站自己测试,很诡异,了解即可):

B树(B-Tree):B树是一颗自平衡的多路搜索树。常用于数据库的索引。
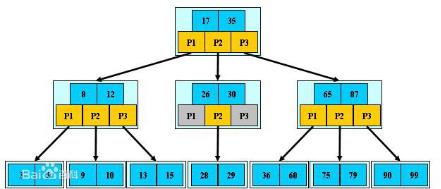
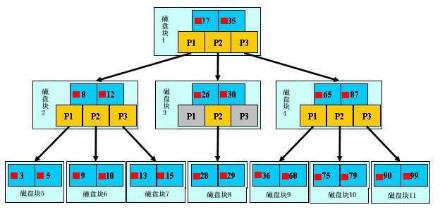
python中的位运算符:

位运算符要比乘除法更快,深得广大程序员的喜爱
以上是关于数据结构的主要内容,如果未能解决你的问题,请参考以下文章
python 用于数据探索的Python代码片段(例如,在数据科学项目中)