POJ #1458 Common Subsequence
Posted 大峰子的博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了POJ #1458 Common Subsequence相关的知识,希望对你有一定的参考价值。
Description
A subsequence of a given sequence is the given sequence with some elements (possible none) left out. Given a sequence X = < x1, x2, ..., xm > another sequence Z = < z1, z2, ..., zk > is a subsequence of X if there exists a strictly increasing sequence < i1, i2, ..., ik > of indices of X such that for all j = 1,2,...,k, x ij= zj. For example, Z = < a, b, f, c > is a subsequence of X = < a, b, c, f, b, c > with index sequence < 1, 2, 4, 6 >. Given two sequences X and Y the problem is to find the length of the maximum-length common subsequence of X and Y.Input
The program input is from the std input. Each data set in the input contains two strings representing the given sequences. The sequences are separated by any number of white spaces. The input data are correct.Output
For each set of data the program prints on the standard output the length of the maximum-length common subsequence from the beginning of a separate line.Sample Input
abcfbc abfcab programming contest abcd mnpSample Output
4 2 0
Sample
INPUT:
abcfbc abfcab
programming contest
abcd mnp
OUTPUT: 4 2 0
思路
首先,我们可以想到用暴力法解决,一个序列的子集有 2n 个,两个子集相互比较找出相同且元素最多的子集即可。但是算法的运行时间是指数阶,肯定会TLE 的。
可以换个角度思考,从两个序列的末尾开始比较,总结出求LCS的递推式。
设序列 X、Y 分别有它们的前缀串,Xm = <x1, x2, .., xm> 、Yn = <y1, y2, .., yn> ,而序列 Z = <z1, z2, .., zk> 是 X、Y 的任意 LCS。有:
1.如果 xm = yn ,则 zk = xm = yn ,且 zk-1 是xm-1、yn-1 的一个 LCS
2.如果 xm != yn,那么 zk != xm 意味着 zk 是 xm-1 、yn 的一个CLS
3.如果 xm != yn,那么 zk != yn 意味着 zk 是 xm 、yn-1 的一个CLS
举个例子, <a, b, c> 与 <a, b>,比较两序列末尾元素 c、b,发现不匹配,那么就认为它们的 LCS是 <a, b> 与 <a, b> 的LCS,或者是 <a, b, c> 与 <a> 的 LCS,至于是哪个取决于后两者 LCS 哪个大。如果末尾元素匹配了,说明找到了 LCS中的一个元素,则让LCS+1 ,继续寻找 <a, b> 、<a> 的LCS...
如果我们用 c[i][j] 代替zk 表示LCS的长度,i 表示序列X的长度,j 表示序列Y的长度,有如下递推式:
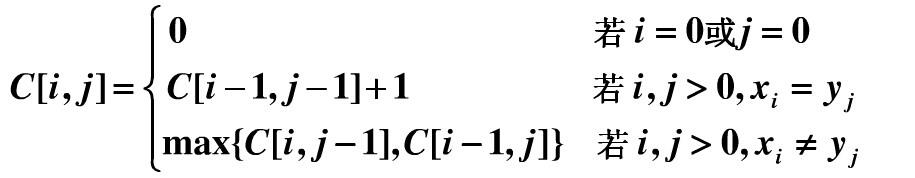
递归的方法求解递推式,但是发现会 TLE,程序太慢了。
我们可以利用记忆化搜索的技巧去优化递归执行效率,因为这道题的很多子问题是重复被求解的,比如 i = 6, j = 5,C[5, 5] 就被重复求解了。像这种的树型递归,我们可以采用记忆化搜索的策略解决,通俗的将就是再写一个备忘录,把求过的解都记录在里面,下一次问题重复时直接取出其中的解即可。
这种算法的时间复杂度和互相独立的子问题个数有关,假设输入的规模是 m、n,那么相互独立的子问题有多少个呢?
m·n 个,可以这么想: c[m][n] 是一个,c[m-1][n] 又是一个,c[m][n-1] 又是一个...
所以,记忆化搜索算法的时间复杂度是O(mn)


#include<iostream> #include<string> #include<algorithm> #include<cstring> using namespace std; const int MAXSIZE = 1000; int c[MAXSIZE][MAXSIZE]; int getLCS (const string& x, const string& y,int i, int j) { //传入的是长度 if (i == 0 || j == 0) { //长度为 0 时,表示序列为空,此时LCS = 0 return 0; } if (c[i][j] >= 0) { return c[i][j]; } if (x[i-1] == y[j-1]) { //用于比较的是下标,下标= 长度 - 1 return c[i][j] = getLCS(x, y, i-1, j-1) + 1; } else { return c[i][j] = std::max(getLCS(x, y, i-1, j), getLCS(x, y, i, j-1)); } } int main(void) { string x,y; while (cin >> x >> y ) { memset (c, -1, sizeof(c)); //LCS可能是0,所以应初始化为-1 int ans = getLCS(x, y, x.size(), y.size()); cout << ans << endl; } return 0; }
但是这种自顶向下的递归策略,存储的空间不密集,会浪费很多空间。
现在换个策略优化算法,采用DP常用的自底向上的迭代策略,选用行为主序,从左往右打表,打表时利用的规则就是上面提到的递推式。
拿 <a, b> 、<a, b, c> 举个例子,先令表中行序、列序为 0 的元素的值为 0 ,这是为了解决边界情况。
然后,让 a 与 a 比较, 发现两元素相同,那么该位置的值 = “相对于该位置左上方的元素值 + 1“ ,即 table[i][j] = table[i-1][j-1] + 1。
然后,让 a 与 b 比较,发现两元素不相同,那么该位置的值 = “比较相对于该位置左边第一个的元素值、上边第一个的元素值,取两者的最大值” ,即 table[i][j] = max ( table[i][j-1], table[i-1][j] ) ...
遍历结束后,table[2][3] 就是两个序列的LCS。

可以发现,这种需要打表DP的算法并没有降低算法的时间复杂度。只是节约了空间,所以算法时间 = O(m·n)
#include<iostream> #include<algorithm> #include<cstring> using namespace std; int get_LCS_Length (const string& x, const string& y) { const int m = x.size(); const int n = y.size(); int dp[m+1][n+1]; memset(dp, 0, sizeof(dp)); for (int i = 1; i <= m; ++i) { for (int j = 1; j <= n; ++j) { if (x[i-1] == y[j-1]) { dp[i][j] = dp[i-1][j-1] + 1; } else { dp[i][j] = std::max(dp[i-1][j], dp[i][j-1]); } } } int res = dp[m][n]; return res; } int main(void) { string x,y; while (cin >> x >> y ) { int ans = get_LCS_Length(x, y); cout << ans << endl; } return 0; }
其实还有一种优化空间版的 DP,就是在上面第二种 DP 的基础上,只需要 (一行 + Θ(1)) 大小的存储空间。因为通过上面打表的办法,发现其实表中当前位置元素的值只与同一行的一个元素和上一行的两个元素有关,不需要存储完整的表。
采用滚动数组存储应该可以,目前暂时没有码出来,以后码完贴上。
以上是关于POJ #1458 Common Subsequence的主要内容,如果未能解决你的问题,请参考以下文章