python之Day2
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python之Day2相关的知识,希望对你有一定的参考价值。
春风和煦,略有小恙。心若平安,万事大吉。能和爱的人一起并肩战斗是一种很美的事情。
---Aaron.shen
5月15日晴
今天上课的的主要内容如下:
1,字符编码:
python3 默认是utf8
摘抄:
字符编码
python解释器在加载.py文件时,会对内容进行编码(默认ascill)
ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,其最多只能用8位来表示(一个字节),即:2**8=256-1,所以,ASCII码最多只能表示255个符号。
所以推出一种新的可以代表所有字符和符号的编码,即: Unicode 规定所有的字符和符号最少由16位来表示(2个字节),即:2**8=65536
UTF-8,是对Unicode编码的压缩和优化,他不再最少使用2个字节,而是将所有的字符和符号进行分类:ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存、东亚的字符用3个字节保存...
所以python解释器在加载.py文件中的代码时,会对内容进行编码(默认ascii)。
2,关于注释:
主要分为#和‘‘‘或者"""
单句的用#号,多行的用‘‘‘或者"""
3,模块:
引用方法import os,sys
import os
os.system("df -Th") #调用系统命令
4,摘要pyc详解:
.pyc是个什么鬼?
1、解释型语言和编译型语言
计算机是不能够识别高级语言的,所以当我们运行一个高级语言程序的时候,就需要一个“翻译机”来从事把高级语言转变成计算机能读懂的机器语言的过程。这个过程分成两类,第一种是编译,第二种是解释。
编译型语言在程序执行之前,先会通过编译器对程序执行一个编译的过程,把程序转变成机器语言。运行时就不需要翻译,而直接执行就可以了。最典型的例子就是C语言。
解释型语言就没有这个编译的过程,而是在程序运行的时候,通过解释器对程序逐行作出解释,然后直接运行,最典型的例子是Ruby。
通过以上的例子,我们可以来总结一下解释型语言和编译型语言的优缺点,因为编译型语言在程序运行之前就已经对程序做出了“翻译”,所以在运行时就少掉了“翻译”的过程,所以效率比较高。但是我们也不能一概而论,一些解释型语言也可以通过解释器的优化来在对程序做出翻译时对整个程序做出优化,从而在效率上超过编译型语言。
此外,随着Java等基于虚拟机的语言的兴起,我们又不能把语言纯粹地分成解释型和编译型这两种。
用Java来举例,Java首先是通过编译器编译成字节码文件,然后在运行时通过解释器给解释成机器文件。所以我们说Java是一种先编译后解释的语言。
2、简述Python的运行过程
在说这个问题之前,我们先来说两个概念,PyCodeObject和pyc文件。
我们在硬盘上看到的pyc自然不必多说,而其实PyCodeObject则是Python编译器真正编译成的结果。我们先简单知道就可以了,继续向下看。
当python程序运行时,编译的结果则是保存在位于内存中的PyCodeObject中,当Python程序运行结束时,Python解释器则将PyCodeObject写回到pyc文件中。
当python程序第二次运行时,首先程序会在硬盘中寻找pyc文件,如果找到,则直接载入,否则就重复上面的过程。(如果.py被改变,先会比较 .py 和.pyc 最新修改时间。)。我们应该这样来定位PyCodeObject和pyc文件,我们说pyc文件其实是PyCodeObject的一种持久化保存方式
5,数据类型:
摘要分类:
1、数字
2 是一个整数的例子。
长整数 不过是大一些的整数。
3.23和52.3E-4是浮点数的例子。E标记表示10的幂。在这里,52.3E-4表示52.3 * 10-4。
(-5+4j)和(2.3-4.6j)是复数的例子。
int(整型)
在64位系统上,整数的位数为64位,取值范围为-2**63~2**63-1,即-9223372036854775808~9223372036854775807
跟C语言不同,Python的长整数没有指定位宽,即:Python没有限制长整数数值的大小,但实际上由于机器内存有限,我们使用的长整数数值不可能无限大。
注意,自从Python2.2起,如果整数发生溢出,Python会自动将整数数据转换为长整数,所以如今在长整数数据后面不加字母L也不会导致严重后果了。
float(浮点型)
浮点数用来处理实数,即带有小数的数字。类似于C语言中的double类型,占8个字节(64位),其中52位表示底,11位表示指数,剩下的一位表示符号。
complex(复数)
复数由实数部分和虚数部分组成,一般形式为x+yj,其中的x是复数的实数部分,y是复数的虚数部分,这里的x和y都是实数。
- 移除空白 -----strip
- 分割 ------split
- 长度 --------len
- 索引 -------[]
- 切片 ------- [:]
7,列表:
[]表示列表
摘要:
创建列表
列表对应数字是下标,list.sort 3.0 里数字和字符不能一起排序,del 删除内存中的数据,全局使用
name_list = [‘alex‘, ‘seven‘, ‘eric‘] 或 name_list = list([‘alex‘, ‘seven‘, ‘eric‘])
切片
#切片可以之后再切片 >>> name=[11,22,33,44,55,66] >>> name[:5][2:4][0] 33
关于增删改查:


1 group = [‘沈学仑‘,‘马大强‘,‘刘立冬‘,‘刘美德‘,‘王智超‘,‘于晓艳‘,‘罗承甲‘] 2 print(group) 3 group.insert(5,‘秦岭‘) 4 group.insert(6,‘秦二‘) 5 print(group) 6 #print(group[2:8]) 7 group.remove(group[7]) 8 print(group) 9 10 del group[5:7] 11 print(group) 12 group[0] = ‘沈学仑-组长‘ 13 print(group) 14 group = group[::2] 15 print(group)
8,元祖(不可修改)
()
其他和列表基本一致。
9,字典(无序的)
{}
创建字典
person = {"name": "mr.wu", ‘age‘: 18}
或
person = dict({"name": "mr.wu", ‘age‘: 18})
dic = { 1:{ ‘name‘:‘aaron‘,‘sex‘:‘man‘,‘age‘:18}, 2:{‘name‘:‘alex‘,‘sex‘:‘man‘,‘age‘:28} } dic[1][‘name‘] = ‘ABC‘ dic[1][‘job‘] = ‘IT‘ dic[1].pop(‘sex‘) v = dic.get(1) dic2 = {3:{‘name‘:‘CBA‘,‘age‘:18}} dic.update(dic2) print(dic) print(v) for key in dic: print(key,dic[key])
常用操作:
- 索引 ----- --------------index
- 新增 -------------------append insert
- 删除 -------------------pop del
- 键、值、键值对 ------------- items
- 循环 ------------- for key in dict: print(‘%s:%s‘ % (key,dict[key]))
- 长度 -------------len
数据运算摘要:
数据运算
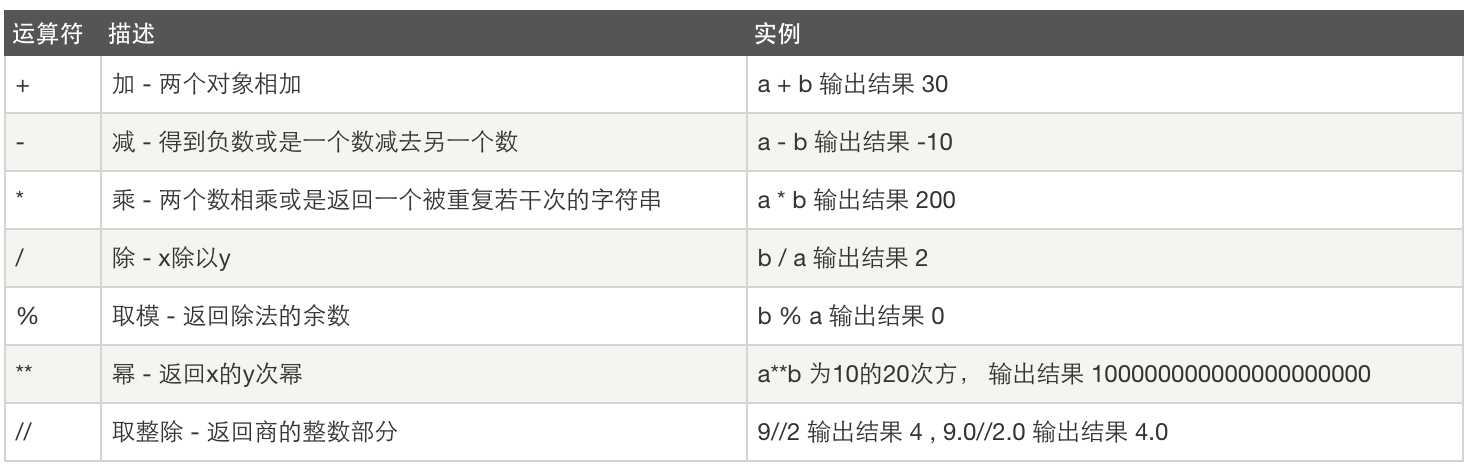
比较运算:

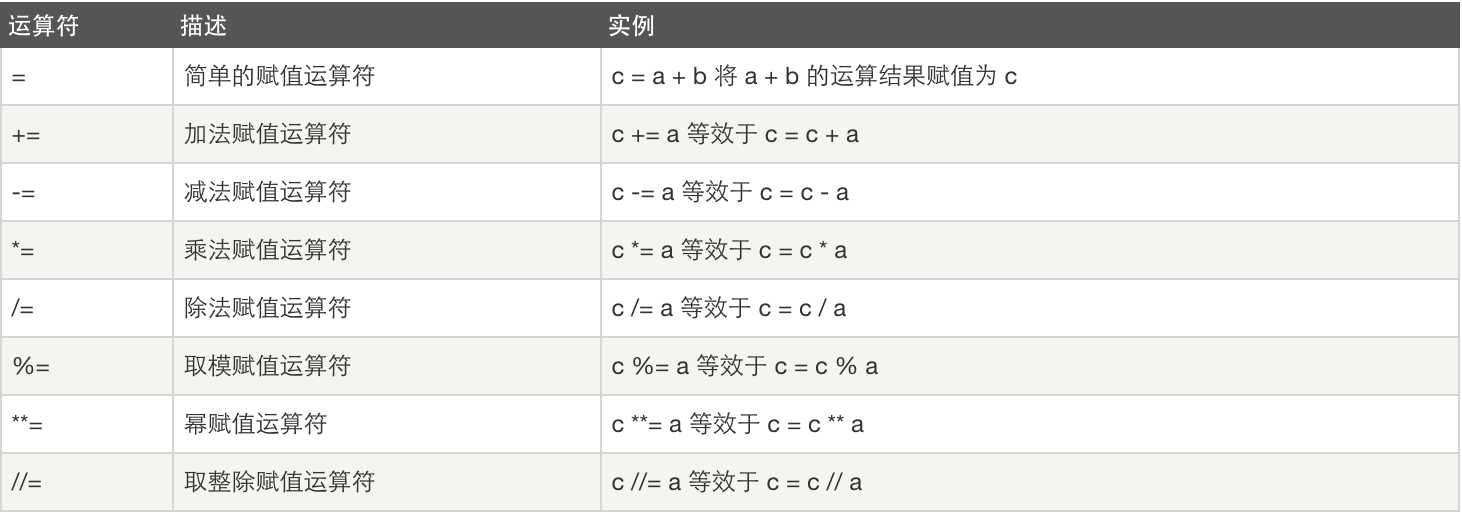
赋值运算:
逻辑运算:

成员运算:

身份运算:

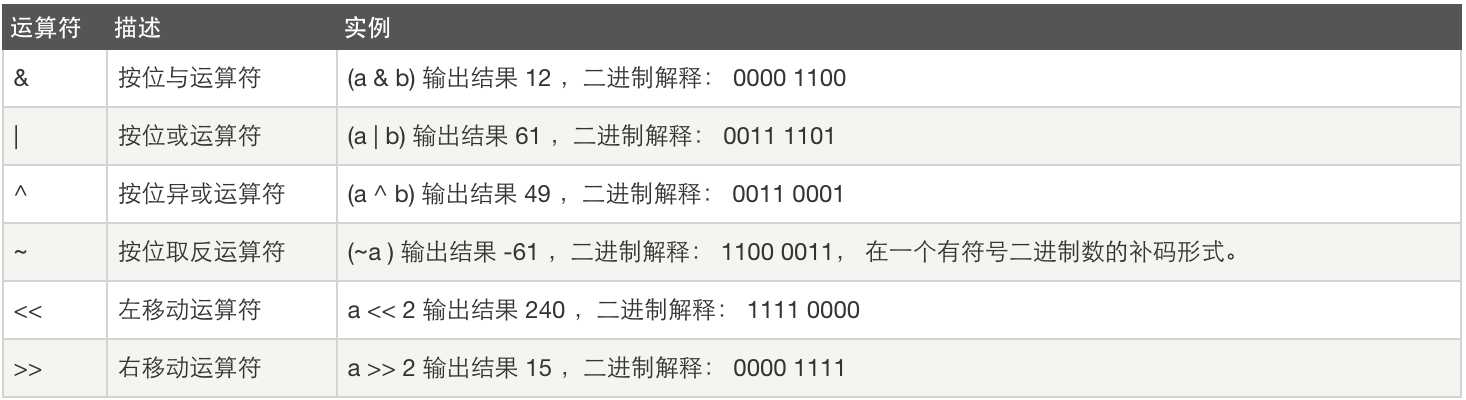
位运算:
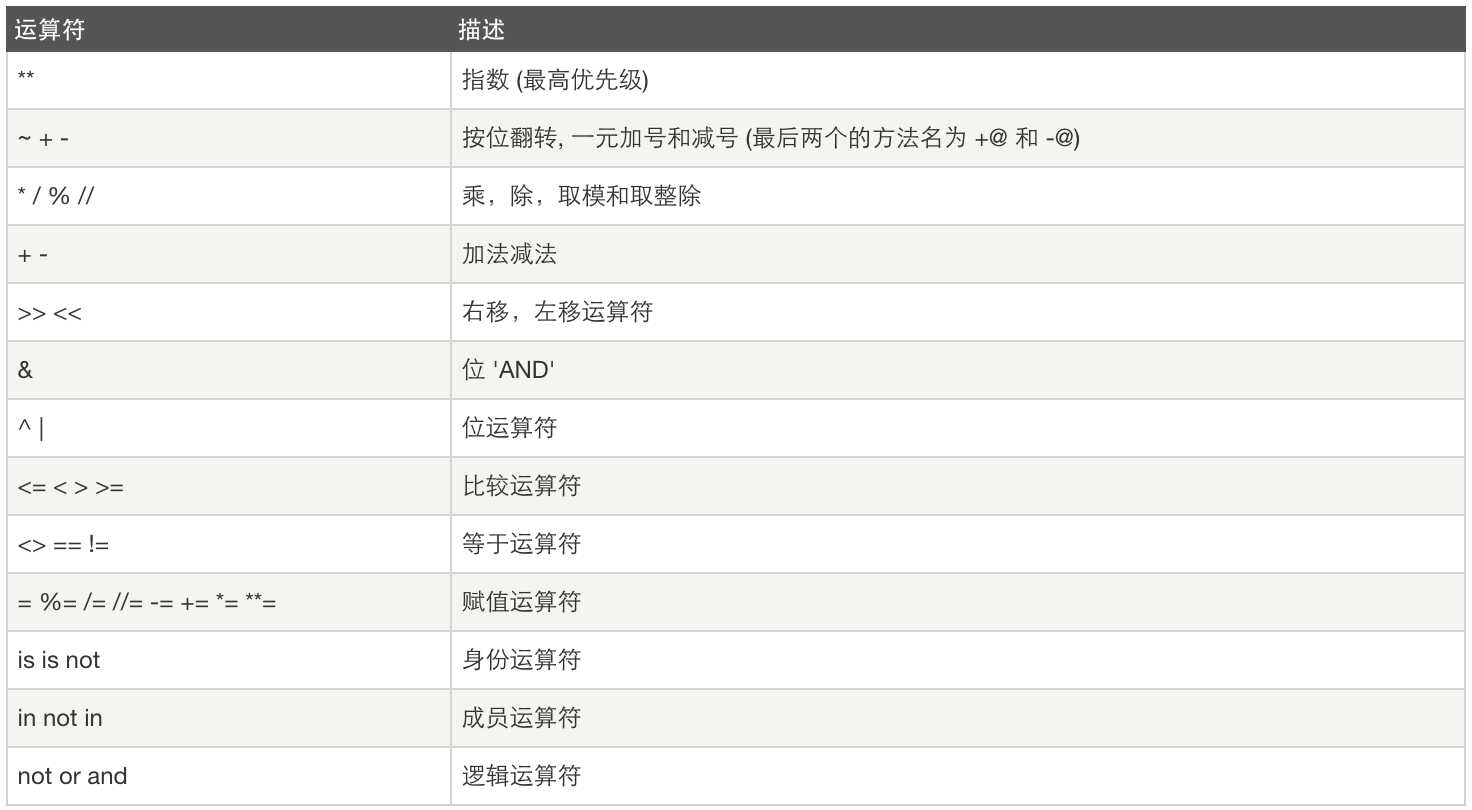
运算符优先级:
以上是关于python之Day2的主要内容,如果未能解决你的问题,请参考以下文章