ProtoBuf 与 gRPC
Posted 路人的技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ProtoBuf 与 gRPC相关的知识,希望对你有一定的参考价值。
用 Protobuf 很久了,但是一直觉得很简单,所以就没有做一个总结,今天想尝试一下 gRPC,顺带就一起总结一下。ProtoBuf 是个老同志了,应该是 2010 的时候发布的,然后被广泛使用,目前在市面上应该和 Facebook 的 thrift 应该是不相上下,无论是性能上,还是用户的支持度上。
What\'s ProtoBuf
ProtoBuf 是一种数据表达方式,根据 G 家自己的描述,应该叫做数据交换格式,注意这里使用的是 交换 字眼,也就是说着重于在数据的传输上,有别于 TOML 和 XML 较常用于配置(当然 WebService 一套也是用于数据交换)。
在使用 ProtoBuf 之后,很多时候,我都希望能够用它来替换 json 和 XML,因为相比较于这些工具,ProtoBuf 的优势比较明显。例如 json 虽然表达方便,语法清晰,但是,有一个硬伤就是没有 schema,对于 Client-Server 的应用/服务来说,这就意味着双方需要使用其他方式进行沟通 schema,否则将无法正确的交流;相比之下,XML 确实提供了强大的 Schema 支持,但是,可能因为年纪更大的缘故,XML 自身的语法啰嗦,更别说定义它的 Schema 了,一句话概括,那就是非常得不现代。
ProtoBuf 结构
ProtoBuf 目前有两个版本,分别是 proto2 和 proto3,虽然 proto3 看上去比 proto2 新,但是,在一些处理上其实被很多人所诟病,例如默认值和未定义的字段的处理上,proto3 不如 proto2;但是 proto3 确实也修正了 proto2 的很多问题和做了精简,所以这里我就直接上 proto3 了,不会差别很大,所以喜欢 proto2 的同学也不用纠结。
proto 的语法有点类似于定义一个类或者说结构体更合适一些,因为它没有方法,只有属性,一个简单的示例为:
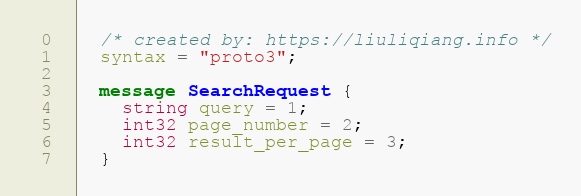 

- 第 1 行肯定是需要的,表面一下你用的是哪个版本,这里指明我的语法是 "proto3" 版本的
- 第 3 行这里就可以理解成定义了一个结构体,名字叫做:SearchRequest
- 第 4 - 6 行就是定义了结构体的属性了,类型 + 名字,这里后面的 "=1/2/3" 这个先不用关注,保证它不一样就好了
这样我们就定义了一个简单的 ProtoBuf,也就是这么简单,然后我们应该尝试一下如何用程序语言来使用这个结构。我这里使用的编程语言是 Go 语言,但是其实用什么语言都不是问题,因为步骤基本一致。
程序操作 ProtoBuf
不同于 json 可以直接被读取解析,ProtoBuf 因为一些元数据,所以在使用之前,我们需要通过工具生成 Model 类,然后再使用,工具安装可以参考官方的文档进行安装,安装完成之后我们直接使用命令生成即可:
$ protoc --go_out=. --python_out=. search.proto
这里从参数中可以看到,我生成了两种语言的 Model,分别是 Python 和 Go 的,类似的,如果你需要其他语言的 Model,可以将语言名字替换试试。
命令完成之后,我们可以在当前目录看到一些文件了:
 

然后我们就可以操作使用代码进行操作了,下面继续:
 

我这里就通过这个 Model 新建一个对象,然后将它序列化(Line 7),序列化之后看一下序列化结果的类型,然后再反序列化(Line 15)回来,然后再看看反序列化之后结果是否正常(Line 20 - 22)。如果你的代码写得没问题的话,那么对应的结果应该也是一样的:
 

ProtoBuf 节省字节
从上边的 Demo 里边你可能看不出 ProtoBuf 有什么特别好的优势,除了有 Schema 之外,但是,如果你看一下序列化之后的 data 的大小之后,你会发现它才 22 个 uint8,以为这什么,也就是说刚才的数据结构才占用 22 个字节,如果你用 json 和 XML 的话是多少?就拿 json 来说,key 和 value 两部分,value 的大小就算和 ProtoBuf 的 value 一样,那应该要 20 个字节,加上 key 超过 20 个字节,算下来至少的 40 个字节,可以认为这里至少省下了一半的空间。你会说这点小钱看不上,但是,你觉得在企业服务中,数据就这么几个?在大数据的场景下,每天的数据量随随便便几百个 G 甚至几十 T;在网络中,节省一半流量代价的下降将至少减少 2 倍以上,内存同理。
既然 ProtoBuf 能这么省字节,那么它是怎么做到的?不知道你还记得不,前面在定义 Message 的时候我让你先忽略掉的数字:

这个数字可是有大用处的,这里我们是写着连续的,但是事实上他们可以是不连续的,那么它们的用处是啥?根据官方文档的介绍,在序列化 ProtoBuf 的时候,它们也是以 Key-Value 的形式压缩的,但是,它们的 key 不是这里面的字面量,而是后面的数值,也就是说对于 "query" 这个字段,我们保存的不是 "query" 的字符串,而是 1 这个数字,这样就将我们的压缩量降低了一大截。
除此之外,对于 value 的处理也是有特别处理的,这里有点类似于 UTF 的处理方式,存在一种称为 varint 的类型,如果是 0-127 的数字,那么我们可以直接用 1 个字节(最多用了 7 位)表示,如果不够用了,要表示 128,那么分为两个字节,不同之处在于,低位的字节要取反码保存,就拿 128 来说吧:
 

这里有意思的地方在于 2 和 3 行,在第 2 行,我们可以看到是对低位的字节取反码,然后在第 3 行,是将高低位转化,最终成为了第 4 行中的表示。这里我有个疑惑就是,为啥要这么操作,文档中的说明是这样可以从左到右搜索字节,如果第一位为 1 则表示这个字节后面还有字节,那么如果我对高位进行取反的话也能得到同样的效果啊。
我认为,这里除了最高位是 1 表示还存在后续字节之外,将高低字节调转在解析的时候会方便不少,因为我们可以看到,字节流从左到右进行解析,最先解析的字节应该是最低位的,也就是说如果我们算 128 的话,最先解析的结果是 127 ,然后是 1,加起来就是 128 了。当然,这对于在程序语言中单类型可以表示完全的好像没什么优势,但是如果并不能表示完全的就有意义了,例如让一种不支持 64 位长整数的程序语言处理 uint64 的数值。
gRPC
ProtoBuf 除了经常被用于数据保存交换之外,还被用于定义 gRPC 服务,gRPC 也是 G 家公开的高性能 RPC 调用框架,号称高效,支持广(题外话,似乎度娘也开源了一款不错的 RPC 框架)。
使用 gRPC 的步骤其实还是很简单的,因为我们只需要做简单几步,就将整体的代码结构创建好了,剩下的工作都是填业务了。无论怎样,第一步肯定还是先明确一下接口的详情:
 

要定义一个接口,除了定义函数原型之外,还需要定义参数和返回值,gRPC 也一样,这里定义接口的形式和 Go 语言有点类似,语法为:
rpc 函数名 (参数) returns (返回值) {}
参数 和 返回值 都是我们在前面已经很熟悉的 Message 定义。有了这些定义之后,我们可以很简单得通过刚才的方式生成框架代码:
$ protoc proto/service.proto --go_out=plugins=grpc:service
随后我们就可以在 service 目录下发现生成的 Go 语言代码,然后我们看到文件:service/proto/service.pb.go,会发现已经生成了我们的函数:
 

重新根据我们自己的逻辑编辑它即可,但是这仅仅只是一个实现,并不能直接对外提供服务,所以我们还需要编写一段服务器的代码,用来驱动这个 service:
 

然后运行看看:
$ go run main.go
这就是如何搭配 ProtoBuf 和 gRPC 的一个方式。
Reference
以上是关于ProtoBuf 与 gRPC的主要内容,如果未能解决你的问题,请参考以下文章
如何为 gRPC 生成的 Java 代码实现 com.google.protobuf.BlockingRpcChannel?