kafka log文件和offset原理
Posted ulysses_you
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kafka log文件和offset原理相关的知识,希望对你有一定的参考价值。
log与offset
日志存储路径根据配置log.dirs ,日志文件通过 topic-partitionId分目录,再通过log.roll.hours 和log.segment.bytes来分文件,默认是超过7天,或者是1GB大小就分文件,在kafka的术语中,这被称为段(segment )。例如00000000000000033986.log,文件名就是offset,除了数据文件之外,相应的还有一个index文件,例如00000000000000033986.index。记录的是该数据文件的offset和对应的物理位置,正是有了这个index文件,才能对任一数据写入和查看拥有O(1)的复杂度,index文件的粒度可以通过参数log.index.interval.bytes来控制,默认是是每过4096字节记录一条index,太小意味着读取效率更高但是index文件会变大。基于这个特性,可以根据时间找到粗粒度的offset。(0.10.0.1版本之后增加记录了时间戳,粒度更细)
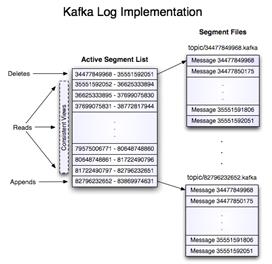
官方展示的log和segment关系
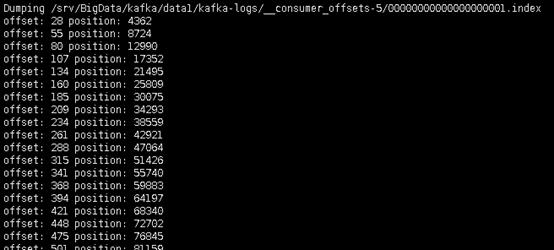
可以通过命令手动查看index文件
# /srv/BigData/kafka/data1/kafka-logs这个路径就是log.dirs,topic-9是topic-partitionId
./kafka-run-class.sh kafka.tools.DumpLogSegments --files /srv/BigData/kafka/data1/kafka-logs/topic-9/00000000000000033986.index
通过log找message流程
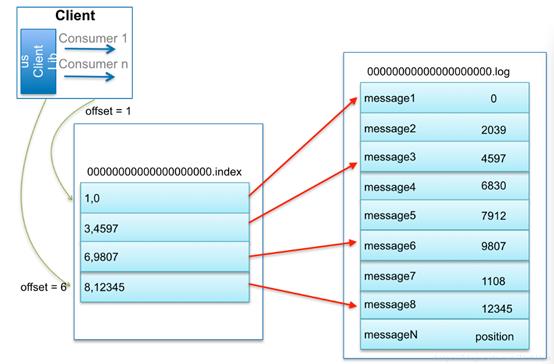
比如:要查找绝对offset为7的Message:
- 用二分查找确定它是在哪个LogSegment中,自然是在第一个Segment中。
- 打开这个Segment的index文件,也是用二分查找找到offset小于或者等于指定offset的索引条目中最大的那个offset。自然offset为6的那个索引是我们要找的,通过索引文件我们知道offset为6的Message在数据文件中的位置为9807。
- 打开数据文件,从位置为9807的那个地方开始顺序扫描直到找到offset为7的那条Message。
// 官方文档
以上是关于kafka log文件和offset原理的主要内容,如果未能解决你的问题,请参考以下文章