Storm 第一章 核心组件及编程模型
Posted IT-執念
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Storm 第一章 核心组件及编程模型相关的知识,希望对你有一定的参考价值。
1 流式计算
流式计算:数据实时产生、实时传输、实时计算、实时展示
代表技术:Flume实时获取数据、Kafka/metaq实时数据存储、Storm/JStorm实时数据计算、Redis实时结果缓存、持久化存储(mysql)。
一句话总结:将源源不断产生的数据实时收集并实时计算,尽可能快的得到计算结果。
2 Storm是什么
Storm 是用来实时处理数据,特点:低延迟、高可用、分布式、可扩展、数据不丢失,提供简单容易理解的接口,便于开发。
3 Storm 与Hadoop的区别
Storm用于实时计算,Hadoop用于离线计算。
Storm处理的数据保存在内存中,源源不断;Hadoop处理的数据保存在文件系统中,一批一批。
Storm处理的数据通过网络传输进来;Hadoop的数据保存在磁盘。
Storm与Hadoop编程模型相似。
4 运用场景
4.1 日志分析
从海量日志中分析出特定的数据,并将分析结果存入外部存储器用来辅助决策。
4.2 管道决策
将一个数据从一个系统传输到另外一个系统,比如将数据同步到Hadoop。
4.3 消息转换器
将接受到的消息按照某种格式进行转化,存储到另外一个系统比如消息中间件。
5 Storm核心组件
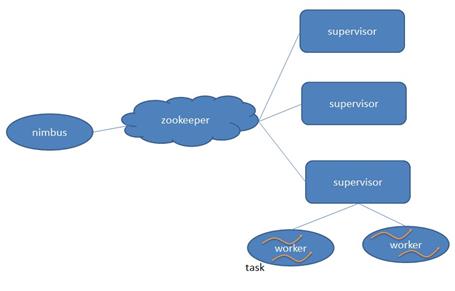
5.1 组件功能:
Nimbus:负责资源分配和任务调度
Supervisor:负责接收nimbus分配的任务,启动和停止属于自己管理的worker进程。通过配置文件设置当前supervisor上启动多少个worker。
Worker:运行具体处理组件逻辑的进程,Worker运行的任务类型只有两种,一种是Spout任务,一种是bolt任务。
Task:worker中每一个spout/bolt的线程称为一个task。在storm0.8之后,task不再与物理线程对应,不同的spout/bolt的task可能会共享一个物理线程,该线程称之为executor。
6 Storm编程模型
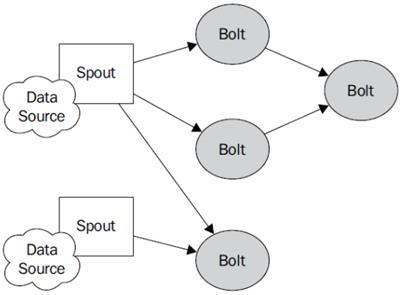
6.1 组件解释
Topology:Storm中运行的一个实时应用程序的名称。(拓扑)
Spout:在一个topology中获取源数据流的组件。通常情况下spout会从外部数据源中读取数据,然后转换为topology内部的源数据。
Bolt:接受数据然后执行处理的组件,用户可以在其中执行自己想要的操作。
Tuple:一次消息传递的基本单元,理解为一组消息就是一个Tuple。
Stream:表示数据的流向。
7 流式计算一般架构图

其中flume用来获取数据
Kafka用来临时保存数据
Strom用来计算数据
Redis是个内存数据库,用来保存数据。
以上是关于Storm 第一章 核心组件及编程模型的主要内容,如果未能解决你的问题,请参考以下文章