决策树
Posted 下路派出所
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了决策树相关的知识,希望对你有一定的参考价值。
决策树
决策树是一种简单但广泛使用的分类器,它通过训练数据构建决策树,对未知的数据进行分类。决策树的每个内部节点表示在一个属性上的测试,每个分枝代表该测试的一个输出,而每个树叶结点存放着一个类标号。
在决策树算法中,ID3基于信息增益作为属性选择的度量,C4.5基于信息增益比作为属性选择的度量,CART基于基尼指数作为属性选择的度量。
- 优点
- 不需要任何领域知识或参数假设。
- 适合高维数据。
- 简单易于理解。
- 短时间内处理大量数据,得到可行且效果较好的结果。
- 缺点
- 对于各类别样本数量不一致数据,信息增益偏向于那些具有更多数值的特征。
- 易于过拟合。
- 忽略属性之间的相关性。
- 不支持在线学习

决策树
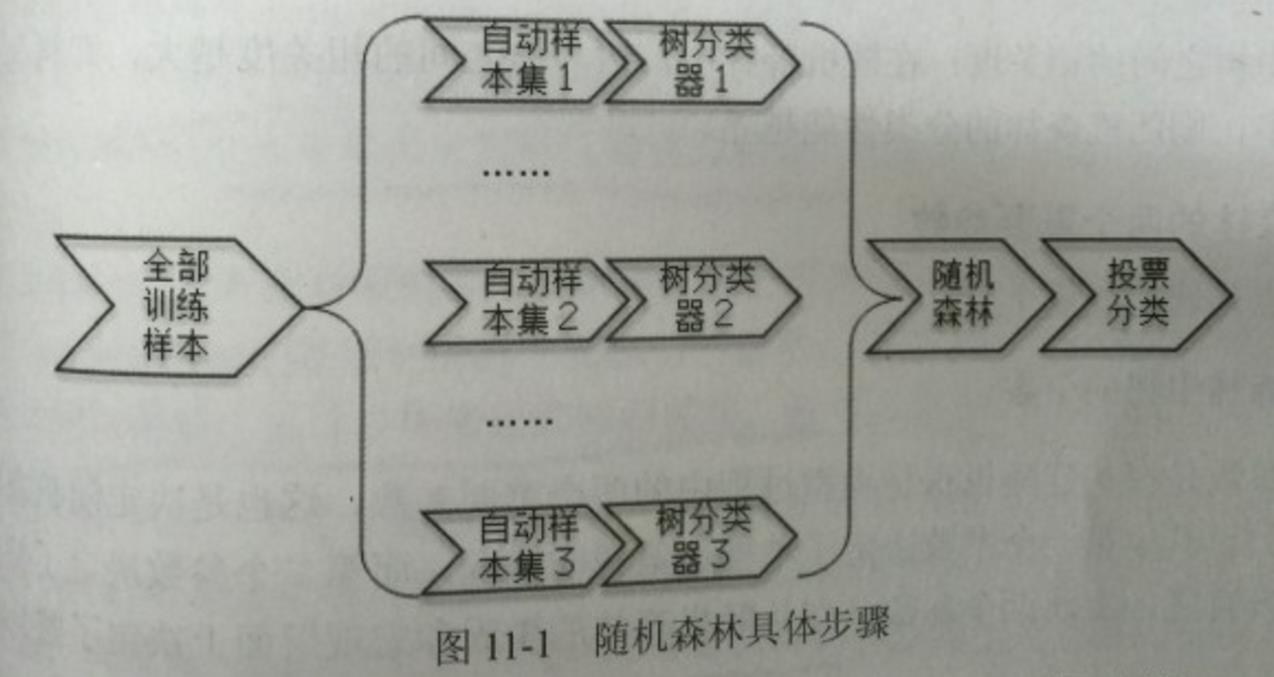
随机森林可以理解为多决策树森林,它是由多个多决策树分类器构成的集成学习模式。其中每个决策树可以理解为一个议员,它从样本集里面随机有放回的抽取一部分进行训练,这样,多个树分类器就构成了一个训练模型矩阵,可以理解为形成了一个议会吧。
然后将要分类的样本带入这一个个树分类器,然后以少数服从多数的原则,表决出这个样本的最终分类类型。
设有N个样本,M个变量(维度)个数,该算法具体流程如下:
1. 从原始训练集中使用Bootstraping方法随机有放回采样选出m个样本,共进行n_tree次采样,生成n_tree个训练集
2. 对于n_tree个训练集,我们分别训练n_tree个决策树模型
3. 对于单个决策树模型,假设训练样本特征的个数为n,那么每次分裂时根据信息增益/信息增益比/基尼指数选择最好的特征进行分裂
4. 将生成的多棵决策树组成随机森林。对于分类问题,按多棵树分类器投票决定最终分类结果;对于回归问题,由多棵树预测值的均值决定最终预测结果
框架流程:
以上是关于决策树的主要内容,如果未能解决你的问题,请参考以下文章