爬 NationalData ,虽然可以直接下,但还是爬一下吧
Posted YuW
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬 NationalData ,虽然可以直接下,但还是爬一下吧相关的知识,希望对你有一定的参考价值。
爬取的是分省月度数据,2017年的,包括:居民消费价格指数,食品烟酒类居民消费价格指数,衣着类居民消费价格指数,居住类居民消费价格指数,生活用品及服务类居民消费价格指数,交通和通信类居民消费价格指数,教育文化和娱乐类居民消费价格指数,医疗保健类居民消费价格指数,其他用品和服务类居民消费价格指数。
打开网站,地区数据-----分省月度数据,如图:
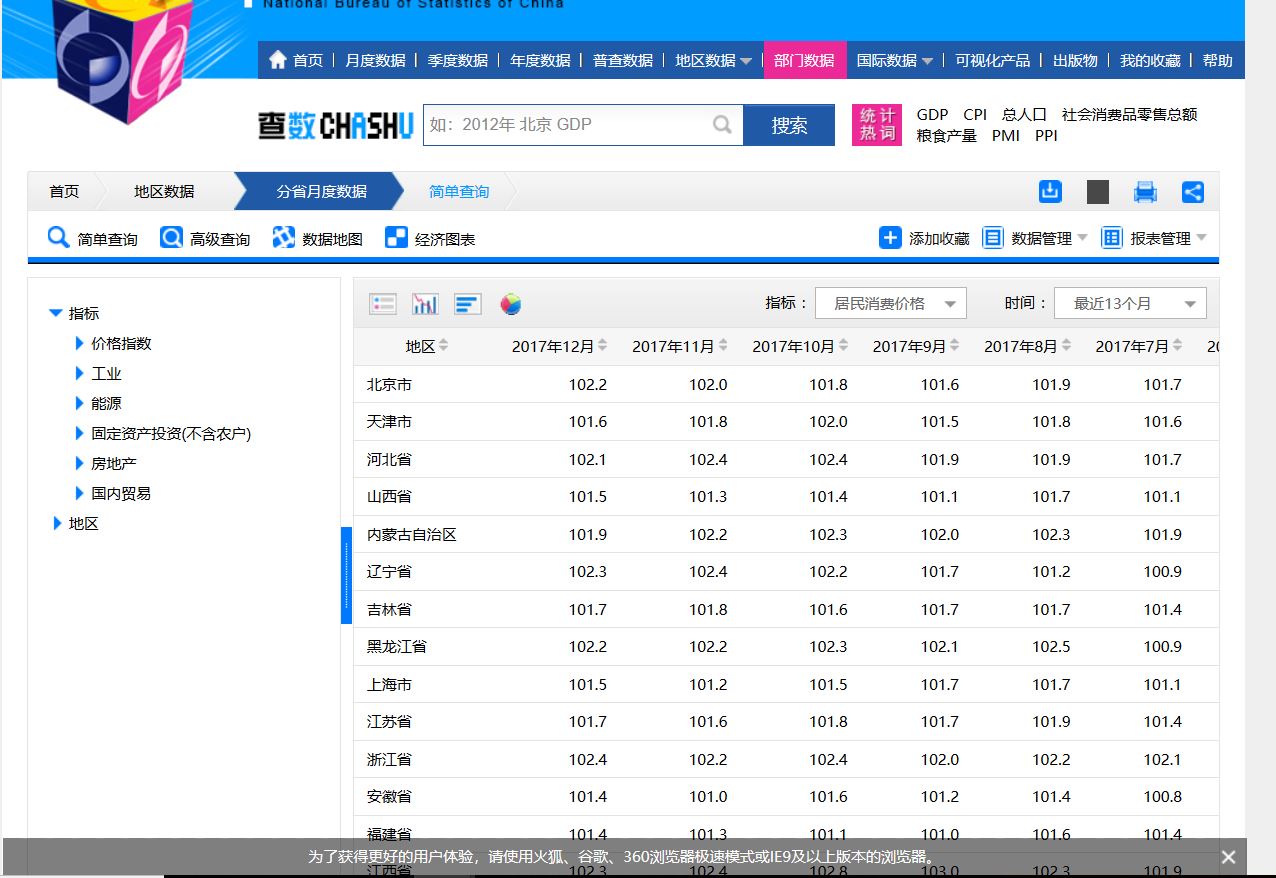
按F12,在按F5会出现3个请求url:
1:http://data.stats.gov.cn/easyquery.htm
2:http://data.stats.gov.cn/easyquery.htm?m=getOtherWds&dbcode=fsyd&rowcode=reg&colcode=sj&wds=[]&k1=1516511359046
3:http://data.stats.gov.cn/easyquery.htm?m=QueryData&dbcode=fsyd&rowcode=reg&colcode=sj&wds=[{"wdcode":"zb","valuecode":"A01010101"}]&dfwds=[]&k1=1516511359249
这三个请求url都有用,但这个爬虫只用了两个:2,3
2的效果图:

3的效果图:

代码如下:
import urllib
from urllib import request
from json import loads
import pymssql
# 发起请求
def getRequestBody(url):
return urllib.request.urlopen(url).read().decode(\'utf8\')
# 获取指标类型
def getTarget(url):
body = getRequestBody(url)
print(\'body\', body)
dicts = loads(body)
return dicts[\'returndata\']
url = \'http://data.stats.gov.cn/easyquery.htm?m=getOtherWds&dbcode=fsyd&rowcode=reg&colcode=sj&wds=[]&k1=1516507560165\'
targetList_returnData = getTarget(url) # list
print(\'targetList_returnData\',targetList_returnData)
for targetIndex_returnData in range(len(targetList_returnData)):
targetDict_returnData = dict(targetList_returnData[targetIndex_returnData]) # dict
targetList_nodes = targetDict_returnData[\'nodes\'] # list
# 请求无法得到,但却有,只能硬来了
targetList_nodes.append({\'code\': \'A01010106\', \'name\': \'交通和通信类居民消费价格指数(上年同月=100)\', \'sort\': \'1\'})
targetList_nodes.append({\'code\': \'A01010107\', \'name\': \'教育文化和娱乐类居民消费价格指数(上年同月=100)\', \'sort\': \'1\'})
targetList_nodes.append({\'code\': \'A01010108\', \'name\': \'医疗保健类居民消费价格指数(上年同月=100)\', \'sort\': \'1\'})
targetList_nodes.append({\'code\': \'A01010109\', \'name\': \'其他用品和服务类居民消费价格指数(上年同月=100)\', \'sort\': \'1\'})
print(\'targetList_nodes\',targetList_nodes)
for targetIndex_nodes in range(len(targetList_nodes)):
targetDict_nodes = dict(targetList_nodes[targetIndex_nodes]) # dict
print(targetDict_nodes[\'code\'],targetDict_nodes[\'name\'])
#
url1 = \'http://data.stats.gov.cn/easyquery.htm?m=QueryData&dbcode=fsyd&rowcode=reg&colcode=sj\' \\
\'&wds=[{"wdcode":"zb","valuecode":"%s"}]&dfwds=[]\' %(targetDict_nodes[\'code\'])
body1 = getRequestBody(url1)
print(\'body1\',body1)
dictAll = loads(body1)
# 获取wdnodes键的name,以name当表名
dataList2 = dictAll[\'returndata\'][\'wdnodes\']
dataList2.pop()
name = dataList2[0][\'nodes\'][0][\'cname\']
if name.find(\'(\') != -1:
name = name[:name.find(\'(\')] + \'2017\'
print(name)
# 获取wdnodes键的地区
regionList = dataList2[1][\'nodes\']
# 获取datanodes键的内容
dataList1 = dictAll[\'returndata\'][\'datanodes\']
# 控制遍历,以删除2016年12月的数据,只要2017年的数据
index = 1
# 控制插入的地区
region = 0
# 存储具体数据
data = []
for dataIndex1 in range(len(dataList1)):
if index <= 12:
# 获取‘datanodes’的指数数据
data_f = dataList1[dataIndex1][\'data\'][\'data\']
print(data_f,index)
data.append(data_f)
conn = pymssql.connect(host=\'localhost\', user=\'sa\', password=\'123456c\', database=\'NationalData\', charset=\'utf8\')
cur = conn.cursor()
if index == 12:
print(regionList[region][\'cname\'])
sql =\'\'\'insert into {} values(\'{}\',{},{},{},{},{},{},{},{},{},{},{},{});\'\'\'\\
.format(name,regionList[region][\'cname\'],data[0],data[1],data[2],data[3],data[4],data[5],data[6],data[7],data[8],data[9],data[10],data[11])
region += 1
cur.execute(sql)
conn.commit()
cur.close()
conn.close()
elif index == 13:
data = []
index = 0
index += 1
break
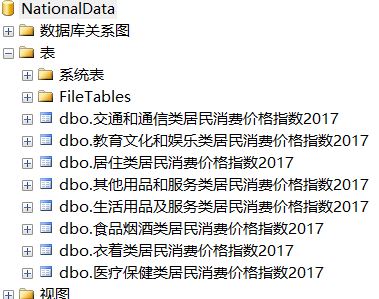
数据库有如下表:
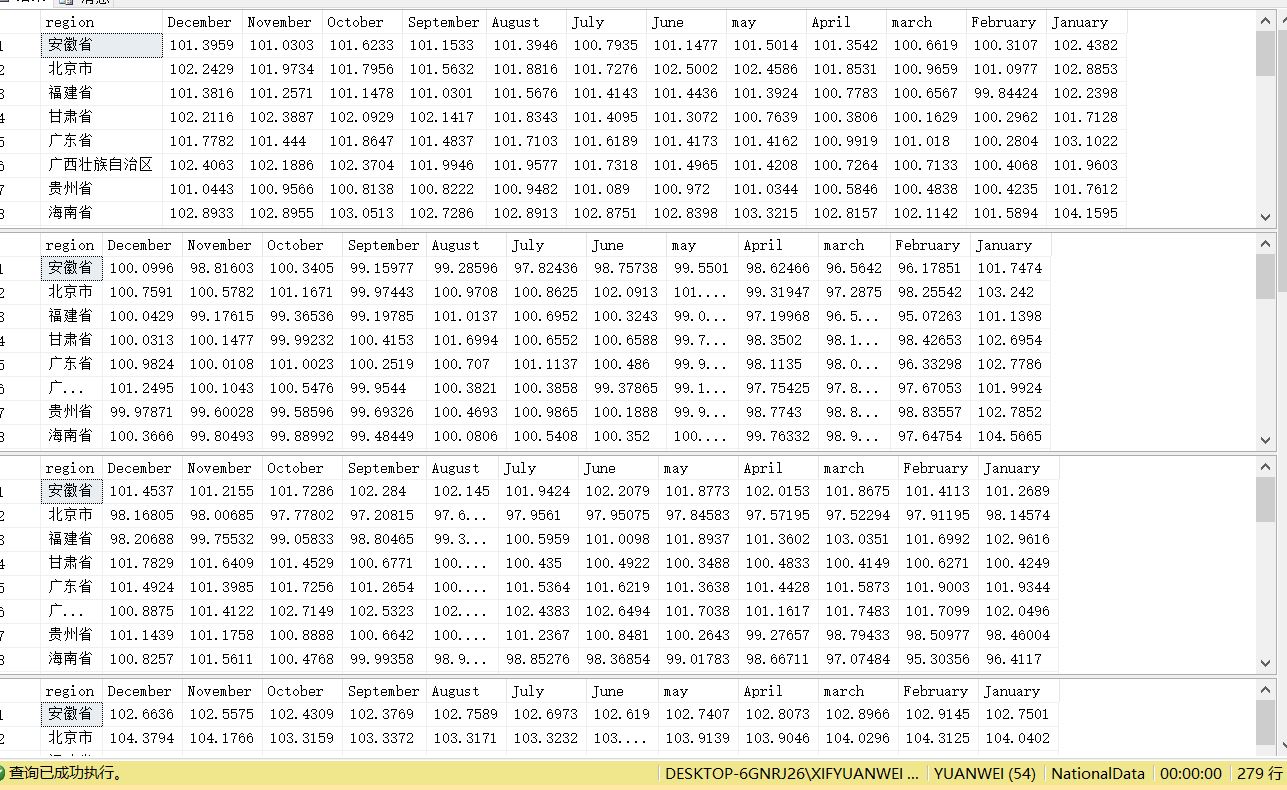
结果:
以上是关于爬 NationalData ,虽然可以直接下,但还是爬一下吧的主要内容,如果未能解决你的问题,请参考以下文章