斯坦福大学公开课机器学习:machine learning system design | trading off precision and recall(F score公式的提出:学习算法中如何平
Posted 橙子牛奶糖
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了斯坦福大学公开课机器学习:machine learning system design | trading off precision and recall(F score公式的提出:学习算法中如何平相关的知识,希望对你有一定的参考价值。
一般来说,召回率和查准率的关系如下:1、如果需要很高的置信度的话,查准率会很高,相应的召回率很低;2、如果需要避免假阴性的话,召回率会很高,查准率会很低。下图右边显示的是召回率和查准率在一个学习算法中的关系。值得注意的是,没有一个学习算法是能同时保证高查准率和召回率的,要高查准率还是高召回率,取决于自己的需求。此外,查准率和召回率之间的关系曲线可以是多样性,不一定是图示的形状。

如何取舍查准率和召回率数值:
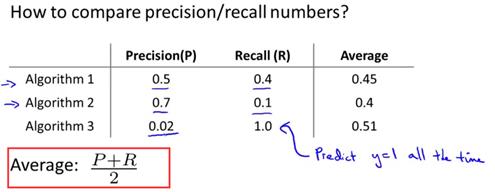
一开始提出来的算法有取查准率和召回率的平均值,如下面的公式average=(P+R)/2。显然,在给出的三个算法当中,算法3的平均值是最高的,然而通过查准率(0.02)和召回率(1.0)可以看出这并不是一个很好的模型。因此,取平均值这个评估模式是不可取的。
如果采用F score算法来同时评估查准率和召回率,则是比较有用的算法。分子的PR决定了查准率(P)和召回率(R)必须同时比较大,才能保证F score数值比较大。假如查准率或者召回率很低,接近于0,直接导致的后果PR值非常低,趋近于0,也就是F score也很低。
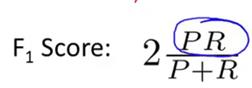
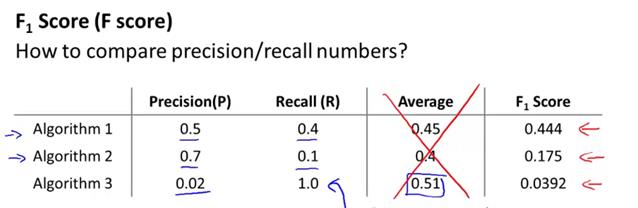
此时再比较三个算法,可发现算法1是最优的,同时我们观察到算法3在这个公式中F score值是最低的。很好的说明了算法3不是一个很好的模型(查准率太低)。说明F score是一个很好的同时评估查准率和召回率的公式。
以上是关于斯坦福大学公开课机器学习:machine learning system design | trading off precision and recall(F score公式的提出:学习算法中如何平的主要内容,如果未能解决你的问题,请参考以下文章
Coursera公开课-Machine_learing:编程作业6
斯坦福大学公开课机器学习:machine learning system design | data for machine learning(数据量很大时,学习算法表现比较好的原理)
斯坦福大学公开课机器学习: advice for applying machine learning | regularization and bais/variance(机器学习中方差和偏差如何相互
斯坦福大学公开课机器学习:advice for applying machine learning - deciding what to try next(设计机器学习系统时,怎样确定最适合最正确的
斯坦福大学公开课机器学习:advice for applying machine learning | learning curves (改进学习算法:高偏差和高方差与学习曲线的关系)