1、因为在提交spark任务的时候没有指定节点的内存的大小,采用了默认的配置导致发生了以下的异常:
18/01/18 17:19:56 ERROR TransportClient: Failed to send RPC 8390558468059355291 to YP-TYHJ-APOLLO4200-7234/10.11.122.234:36047: java .nio.channels.ClosedChannelException java.nio.channels.ClosedChannelException 18/01/18 17:19:56 WARN NettyRpcEndpointRef: Error sending message [message = Heartbeat(8,[Lscala.Tuple2;@7d11b814,BlockManagerId(8, YP-TYHJ-APOLLO4200-7231, 39189))] in 1 attempts java.io.IOException: Failed to send RPC 8390558468059355291 to YP-TYHJ-APOLLO4200-7234/10.11.122.234:36047: java.nio.channels.Closed ChannelException at org.apache.spark.network.client.TransportClient$3.operationComplete(TransportClient.java:239) at org.apache.spark.network.client.TransportClient$3.operationComplete(TransportClient.java:226) at io.netty.util.concurrent.DefaultPromise.notifyListener0(DefaultPromise.java:680) at io.netty.util.concurrent.DefaultPromise.notifyListeners(DefaultPromise.java:567) at io.netty.util.concurrent.DefaultPromise.tryFailure(DefaultPromise.java:424) at io.netty.channel.AbstractChannel$AbstractUnsafe.safeSetFailure(AbstractChannel.java:801) at io.netty.channel.AbstractChannel$AbstractUnsafe.write(AbstractChannel.java:699) at io.netty.channel.DefaultChannelPipeline$HeadContext.write(DefaultChannelPipeline.java:1122) at io.netty.channel.AbstractChannelHandlerContext.invokeWrite(AbstractChannelHandlerContext.java:633) at io.netty.channel.AbstractChannelHandlerContext.access$1900(AbstractChannelHandlerContext.java:32) at io.netty.channel.AbstractChannelHandlerContext$AbstractWriteTask.write(AbstractChannelHandlerContext.java:908) at io.netty.channel.AbstractChannelHandlerContext$WriteAndFlushTask.write(AbstractChannelHandlerContext.java:960) at io.netty.channel.AbstractChannelHandlerContext$AbstractWriteTask.run(AbstractChannelHandlerContext.java:893) at io.netty.util.concurrent.SingleThreadEventExecutor.runAllTasks(SingleThreadEventExecutor.java:357) at io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:357) at io.netty.util.concurrent.SingleThreadEventExecutor$2.run(SingleThreadEventExecutor.java:111) at java.lang.Thread.run(Thread.java:745) Caused by: java.nio.channels.ClosedChannelException 18/01/18 17:19:56 ERROR CoarseGrainedExecutorBackend: RECEIVED SIGNAL 15: SIGTERM 18/01/18 17:19:57 INFO DiskBlockManager: Shutdown hook called 18/01/18 17:19:57 INFO ShutdownHookManager: Shutdown hook called
解决方法:
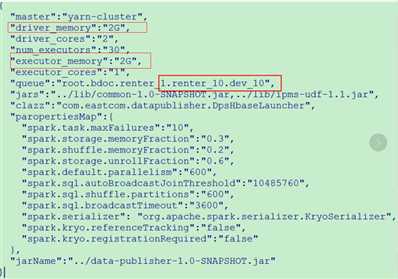
将driver_executor和executor_memory调大,调节原则:使用的资源有多大,就尽量去调节到最大的大小。
2、spark汇聚数据到hbase失败
ERROR Executor: Managed memory leak detected; size = 67371008 bytes, TID = 61301 18/01/16 15:49:00 ERROR Executor: Exception in task 41.8 in stage 120.0 (TID 61301) org.apache.hadoop.hive.ql.metadata.HiveException: parquet.hadoop.MemoryManager$1: New Memory allocation 1023098 bytes is smaller tha n the minimum allocation size of 1048576 bytes. at org.apache.hadoop.hive.ql.io.HiveFileFormatUtils.getHiveRecordWriter(HiveFileFormatUtils.java:249) at org.apache.spark.sql.hive.SparkHiveDynamicPartitionWriterContainer.org$apache$spark$sql$hive$SparkHiveDynamicPartitionWri terContainer$$newWriter$1(hiveWriterContainers.scala:240) at org.apache.spark.sql.hive.SparkHiveDynamicPartitionWriterContainer$$anonfun$getLocalFileWriter$1.apply(hiveWriterContaine rs.scala:249) at org.apache.spark.sql.hive.SparkHiveDynamicPartitionWriterContainer$$anonfun$getLocalFileWriter$1.apply(hiveWriterContaine rs.scala:249) at scala.collection.mutable.MapLike$class.getOrElseUpdate(MapLike.scala:189) at scala.collection.mutable.AbstractMap.getOrElseUpdate(Map.scala:91) at org.apache.spark.sql.hive.SparkHiveDynamicPartitionWriterContainer.getLocalFileWriter(hiveWriterContainers.scala:249) at org.apache.spark.sql.hive.execution.InsertIntoHiveTable$$anonfun$org$apache$spark$sql$hive$execution$InsertIntoHiveTable$ $writeToFile$1$1.apply(InsertIntoHiveTable.scala:112) at org.apache.spark.sql.hive.execution.InsertIntoHiveTable$$anonfun$org$apache$spark$sql$hive$execution$InsertIntoHiveTable$ $writeToFile$1$1.apply(InsertIntoHiveTable.scala:104) at scala.collection.Iterator$class.foreach(Iterator.scala:727) at scala.collection.AbstractIterator.foreach(Iterator.scala:1157) at org.apache.spark.sql.hive.execution.InsertIntoHiveTable.org$apache$spark$sql$hive$execution$InsertIntoHiveTable$$writeToF ile$1(InsertIntoHiveTable.scala:104) at org.apache.spark.sql.hive.execution.InsertIntoHiveTable$$anonfun$saveAsHiveFile$3.apply(InsertIntoHiveTable.scala:84) at org.apache.spark.sql.hive.execution.InsertIntoHiveTable$$anonfun$saveAsHiveFile$3.apply(InsertIntoHiveTable.scala:84) at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:66) at org.apache.spark.scheduler.Task.run(Task.scala:89) at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:227) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615) at java.lang.Thread.run(Thread.java:745) Caused by: parquet.hadoop.MemoryManager$1: New Memory allocation 1023098 bytes is smaller than the minimum allocation size of 104857 6 bytes. at parquet.hadoop.MemoryManager.updateAllocation(MemoryManager.java:125) at parquet.hadoop.MemoryManager.addWriter(MemoryManager.java:82) at parquet.hadoop.ParquetRecordWriter.<init>(ParquetRecordWriter.java:104) at parquet.hadoop.ParquetOutputFormat.getRecordWriter(ParquetOutputFormat.java:303) at parquet.hadoop.ParquetOutputFormat.getRecordWriter(ParquetOutputFormat.java:267) at org.apache.hadoop.hive.ql.io.parquet.write.ParquetRecordWriterWrapper.<init>(ParquetRecordWriterWrapper.java:65) at org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat.getParquerRecordWriterWrapper(MapredParquetOutputFormat.ja va:125) at org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat.getHiveRecordWriter(MapredParquetOutputFormat.java:114) at org.apache.hadoop.hive.ql.io.HiveFileFormatUtils.getRecordWriter(HiveFileFormatUtils.java:261) at org.apache.hadoop.hive.ql.io.HiveFileFormatUtils.getHiveRecordWriter(HiveFileFormatUtils.java:246) ... 19 more 18/01/16 15:49:00 WARN MemoryManager: Total allocation exceeds 50.00% (2,147,483,647 bytes) of heap memory Scaling row group sizes to 0.76% for 2100 writers 18/01/16 15:49:00 WARN TaskMemoryManager: leak 64.3 MB memory from org.apache.spark.unsafe[email protected]
解决办法:
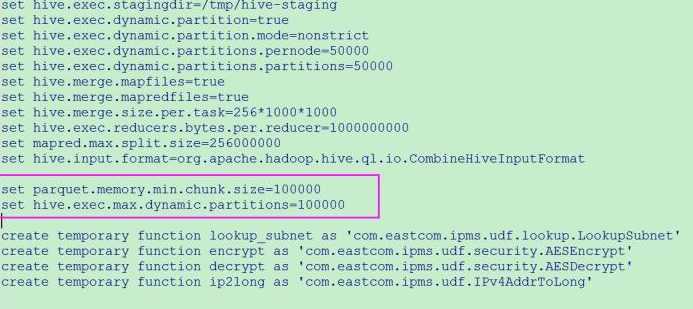
hive.Context.setConf("parquet.memory.min.chunk.size","100000")
hive.Context.setConf("hive.exec.max.dynamic.partitions","100000")