探索HashMap实现原理及其在jdk8数据结构的改进
Posted 学海无涯
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了探索HashMap实现原理及其在jdk8数据结构的改进相关的知识,希望对你有一定的参考价值。
因为网上已经太多的关于HashMap的相关文章了,为了避免大量重复,又由于网上关于java8的HashMap的相关文章比较少,至少我没有找到比较详细的。所以才有了本文。
本文主要的内容:
1.HashMap的数据结构,以及java 8的新特征
2.HashMap的put方法的实现原理
3.resize()到底做了什么事情,它是怎么扩容的
4.HashMap节点红黑树存储
HashMap的数据结构,以及java 8的新特征
下面来看下HashMap的主要两种存储方式是示意图(图片来自网络):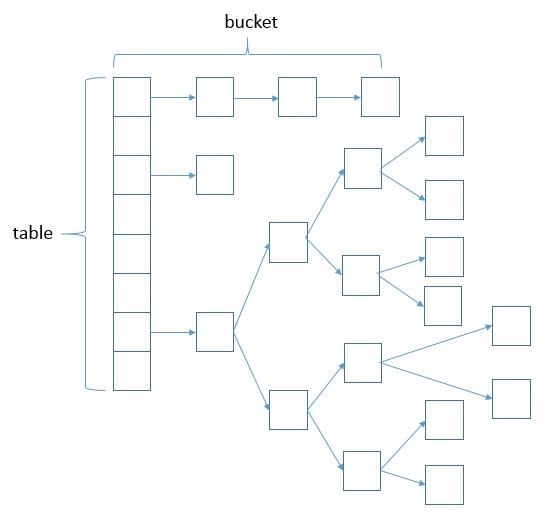
这就是java8的HashMap的数据结构,跟之前版本不一样的是当table达到一定的阀值时,bucket就会由链表转换为红黑树的方式进行存储,下面会做具体的源码分析。
-
HashMap的put方法实现原理
下面我们来看下关于put的方法,hashMap的Capacity的默认值为16,负载因子的默认值为0.75
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; //table为空就创建 if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; //确定插入table的位置,算法是(n - 1) & hash if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null); //在table的i位置发生碰撞,有两种情况,1、key值是一样的,替换value值, //2、key值不一样的有两种处理方式:2.1、存储在i位置的链表;2.2、存储在红黑树中 else { Node<K,V> e; K k; if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; //2.2 else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); //2.1 else { for (int binCount = 0; ; ++binCount) { if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); //超过了链表的设置长度8就扩容 if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } } //如果e为空就替换旧的oldValue值 if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); return oldValue; } } ++modCount; //threshold=newThr:(int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); //默认0.75*16,大于threshold值就扩容 if (++size > threshold) resize(); afterNodeInsertion(evict); return null; }
因为已经做了注释了具体请看注释,所以大部分细节就不多说了,下面说说hash的算法和寻址的算法
首先计算hash值
static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }
具体的计算过程用如下图表示,在设计hash函数时,因为目前的table长度2的N次方,而计算下标的时候,使用&位操作,而非%求余: 探索HashMap实现原理及其在jdk8数据结构的改进 - darrell - DARRELL的博客 请看putVal代码27/28行,当桶bucket大于TREEIFY_THRESHOLD(8)值时就执行treeifyBin,如果是之前java7之前的代码的话是要进行扩容的,但是java8可能会把这个bucket的链表上的数据转化为红黑树
final void treeifyBin(Node<K,V>[] tab, int hash) { int n, index; Node<K,V> e; //当tab.length<MIN_TREEIFY_CAPACITY(64)是还是进行resize if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY) resize(); else if ((e = tab[index = (n - 1) & hash]) != null) { TreeNode<K,V> hd = null, tl = null; do { TreeNode<K,V> p = replacementTreeNode(e, null); if (tl == null) hd = p; else { p.prev = tl; tl.next = p; } tl = p; } while ((e = e.next) != null); if ((tab[index] = hd) != null) //存储在红黑树 hd.treeify(tab); } }
resize到底做了什么事情,它是怎么扩容的
我们先看下resize这个方法吧,这段代码后面会讲到24行的treeify方法,也是本文的重点红黑树的存储,以为这个方法的实现方式还是有别与java7的,桶中存在一个链表,需要将链表重新整理到新表当中,因为newCap是oldCap的两倍所以原节点的索引值要么和原来一样,要么就是原(索引+oldCap)和JDK 1.7中实现不同这里不存在rehash
final Node<K,V>[] resize() { Node<K,V>[] oldTab = table; int oldCap = (oldTab == null) ? 0 : oldTab.length; int oldThr = threshold; int newCap, newThr = 0; if (oldCap > 0) { if (oldCap >= MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return oldTab; } else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY) newThr = oldThr << 1; // double threshold } else if (oldThr > 0) // initial capacity was placed in threshold newCap = oldThr; else { // zero initial threshold signifies using defaults newCap = DEFAULT_INITIAL_CAPACITY; newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); } if (newThr == 0) { float ft = (float)newCap * loadFactor; newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX_VALUE); } threshold = newThr; @SuppressWarnings({"rawtypes","unchecked"}) Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; table = newTab; if (oldTab != null) { for (int j = 0; j < oldCap; ++j) { Node<K,V> e; if ((e = oldTab[j]) != null) { oldTab[j] = null; if (e.next == null) newTab[e.hash & (newCap - 1)] = e; else if (e instanceof TreeNode) ((TreeNode<K,V>)e).split(this, newTab, j, oldCap); else { // preserve order //分别记录头和尾的节点 Node<K,V> loHead = null, loTail = null; Node<K,V> hiHead = null, hiTail = null; Node<K,V> next; do { next = e.next; if ((e.hash & oldCap) == 0) { if (loTail == null) loHead = e; else loTail.next = e; loTail = e; } else { if (hiTail == null) hiHead = e; else hiTail.next = e; hiTail = e; } } while ((e = next) != null); if (loTail != null) { loTail.next = null; newTab[j] = loHead; } if (hiTail != null) { hiTail.next = null; //把节点移动新的位置j+oldCap,这种情况不适用与链表的节点数大于8的情况 //链表节点大于8的情况会转换为红黑树存储 newTab[j + oldCap] = hiHead; } } } } } return newTab; }
HashMap节点红黑树存储
好了终于到treeify了,大部分内容都在注解中
final void treeify(Node<K,V>[] tab) { TreeNode<K,V> root = null; for (TreeNode<K,V> x = this, next; x != null; x = next) { next = (TreeNode<K,V>)x.next; x.left = x.right = null; if (root == null) { x.parent = null; x.red = false; root = x; } else { K k = x.key; int h = x.hash; Class<?> kc = null; //遍历root,把节点x插入到红黑树中,执行先插入,然后进行红黑树修正 for (TreeNode<K,V> p = root;;) { int dir, ph; K pk = p.key; if ((ph = p.hash) > h) dir = -1; else if (ph < h) dir = 1; else if ((kc == null && (kc = comparableClassFor(k)) == null) || (dir = compareComparables(kc, k, pk)) == 0) dir = tieBreakOrder(k, pk);//比较k和pk的值,用于判断是遍历左子树还是右子树 TreeNode<K,V> xp = p; if ((p = (dir <= 0) ? p.left : p.right) == null) { x.parent = xp; if (dir <= 0) xp.left = x; else xp.right = x; //修正红黑树 root = balanceInsertion(root, x); //退出循环 break; } } } } moveRootToFront(tab, root); }
上面主要做的是红黑树的insert,我们知道红黑树insert后是需要修复的,为了保持红黑树的平衡,我们来看下红黑树平衡的几条性质:
1.节点是红色或黑色。
2.根是黑色。
3.所有叶子都是黑色(叶子是NIL节点)。
4.每个红色节点必须有两个黑色的子节点。(从每个叶子到根的所有路径上不能有两个连续的红色节点。)
5.从任一节点到其每个叶子的所有简单路径都包含相同数目的黑色节点。
当insert一个节点之后为了达到平衡,我们可能需要对节点进行旋转和颜色翻转(上面的balanceInsertion方法)。具体操作这里就不细讲了,对红黑树的修复还不是很清楚的同学可以去参考下数据结构与算法分析这本书,我将在后面写一篇关于红黑树关于java实现的相关文章。
static <K,V> TreeNode<K,V> balanceInsertion(TreeNode<K,V> root, TreeNode<K,V> x) { //插入的节点必须是红色的,除非是根节点 x.red = true; //遍历到x节点为黑色,整个过程是一个上滤的过程 //xp=x.parent;xpp=xp.parent;xppl=xpp.left;xppr=xpp.right; for (TreeNode<K,V> xp, xpp, xppl, xppr;;) { if ((xp = x.parent) == null) { x.red = false; return x; } //如果xp的黑色就直接完成,最简单的情况 else if (!xp.red || (xpp = xp.parent) == null) return root; //如果x的父节点是x父节点的左节点 if (xp == (xppl = xpp.left)) { //x的父亲节点的兄弟是红色的(需要颜色翻转) if ((xppr = xpp.right) != null && xppr.red) { //x父亲节点的兄弟节点置成黑色 xppr.red = false; //父几点和其兄弟节点一样是黑色 xp.red = false; //祖父节点置成红色 xpp.red = true; //然后上滤(就是不断的重复上面的操作) x = xpp; } else { //如果x是xp的右节点整个要进行两次旋转,先左旋转再右旋转 if (x == xp.right) { root = rotateLeft(root, x = xp); xpp = (xp = x.parent) == null ? null : xp.parent; } if (xp != null) { xp.red = false; if (xpp != null) { xpp.red = true; root = rotateRight(root, xpp); } } } } //以左节点镜像对称就不做具体分析了 else { if (xppl != null && xppl.red) { xppl.red = false; xp.red = false; xpp.red = true; x = xpp; } else { if (x == xp.left) { root = rotateRight(root, x = xp); xpp = (xp = x.parent) == null ? null : xp.parent; } if (xp != null) { xp.red = false; if (xpp != null) { xpp.red = true; root = rotateLeft(root, xpp); } } } } } }
以上是关于探索HashMap实现原理及其在jdk8数据结构的改进的主要内容,如果未能解决你的问题,请参考以下文章