2容器初探
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2容器初探相关的知识,希望对你有一定的参考价值。
简单容器的分类:
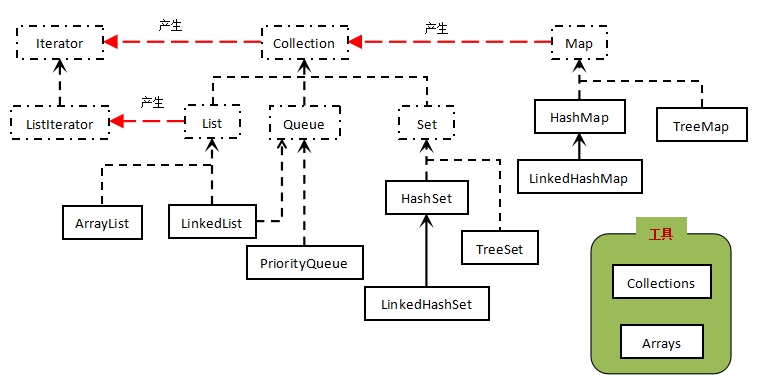
图1. 简单容器的分类
在“图1”中总结出了常用容器的简单关系。可以看到,只有4类容器:List、Set、Queue、Map。上图中虚线框表示一个接口,实线框表示一个具体的实现类,虚线箭头线表示一种“实现”关系,实线箭头线表示一种“继承”关系。红线箭头不表示实现与继承关系。
为了理清楚“图1”中简单容器的关系,首先从迭代器(Iterator)的作用开始讲解。
一、迭代器
迭代器是一个对象,它的工作是遍历并选择容器中的对象,而程序员不必要知道或关心容器的底层实现(无论List、Queue、Set都采用同样的方式来对待)。迭代器是一个轻量级的对象,创建它的代价很小,同样功能也简单(比如:只能单向移动)。只具备如下的功能:
①、使用方法iterator()要求容器返回一个Iterator。Iterator将准备好返回容器的第一个元素。
②、使用next()获得容器的下一个元素。
③、使用hasNext()检查容器中是否还有元素。
④、使用remove()将迭代器新近返回的元素删除。
迭代器真正的强大在于将遍历容器的操作与容器底层结构相分离。
例如:打印包含有Person对象的容器可以写下面一个方法,只需要向打印方法中传入一个迭代器即可,至于这个容器到底是List还是Set根本不需要关心。
1 void printPerson(Iterator<Person> itr){ 2 if(itr == null) 3 return; 4 while(itr.hasNext()){ 5 Person p = itr.next(); 6 System.out.println(p.getName() + " " + p.getAge()); 7 } 8 }
Collection接口中就定义有iterator()方法,所以如果容器是List、Set、Queue则只需要直接调用对象的iterator()方法便可以得到一个迭代器对象。
但是,Map容器并没有实现Collection接口,那么一个Map类型的容器该如何获得一个迭代器对象呢?Map定义了三个Collection视角的方法:
①、map.entrySet(); 返回一个Set<Entry<T, E>>对象,SetSet<Entry<T, E>>对象中有iterator()方法。
②、map.keySet(); 返回一个Set<T>对象,Set<T>对象中有iterator()方法。
③、map.values(); 返回一个Collection<T>对象,Collection<T>对象中有iterator()方法。
下面是一个迭代器用于Map的例子:


1 import java.util.*; 2 import java.util.Map.Entry; 3 public class Main{ 4 public static void main(String args[]){ 5 6 Map<Integer, String> map = new HashMap<>(); 7 map.put(1, "aaa"); 8 map.put(2, "bbb"); 9 map.put(3, "ccc"); 10 map.put(4, "ddd"); 11 12 Set<Entry<Integer, String>> setEntry = map.entrySet(); 13 Iterator<Entry<Integer, String>> itrEntry = setEntry.iterator(); 14 System.out.println("--------map.entrySet()--------"); 15 while(itrEntry.hasNext()){ 16 Entry<Integer, String> entry = itrEntry.next(); 17 Integer key = entry.getKey(); 18 String val = entry.getValue(); 19 System.out.print(key + ":" + val + " "); 20 } 21 22 Set<Integer> setKey = map.keySet(); 23 Iterator<Integer> itrKey = setKey.iterator(); 24 System.out.println("\\n\\n--------map.keySet()--------"); 25 while(itrKey.hasNext()){ 26 Integer key = itrKey.next(); 27 System.out.print(key + " "); 28 } 29 30 Collection<String> values = map.values(); 31 Iterator<String> itrValues = values.iterator(); 32 System.out.println("\\n\\n--------map.values()--------"); 33 while(itrValues.hasNext()){ 34 String val = itrValues.next(); 35 System.out.print(val + " "); 36 } 37 }
运行结果:

除此之外,ListIterator是一个更强大的Iterator的子类型,它只能够用于各种List类的访问。尽管Iterator只能够单向移动,但是ListIterator却能够双向移动。
二、List
public interface List<E> extends Collection<E> 可以看出,List接口直接继承Collection接口。
下面主要讲List接口的两个具体实现类ArrayList和LinkedList。
ArrayList底层的具体实现是一个Object[]对象。
在其调用add方法的时候会先检查底层Object[]对象是否还有足够的空间,如果空间足够则将元素添加到末尾;如果没有足够的空间则创建一个更大的Object[]数组,并将旧数组中的数据复制到新数组中间去。
扩容过程调用elementData = Arrays.copyOf(elementData, newCapacity) 来完成,elementData 就是ArrayList底层Object[]对象。copyOf方法最终会调用下面的方法来实现:
1 public static <T,U> T[] copyOf(U[] original, int newLength, Class<? extends T[]> newType) { 2 @SuppressWarnings("unchecked") 3 T[] copy = ((Object)newType == (Object)Object[].class) 4 ? (T[]) new Object[newLength] 5 : (T[]) Array.newInstance(newType.getComponentType(), newLength); 6 System.arraycopy(original, 0, copy, 0, Math.min(original.length, newLength)); 7 return copy; 8 }
可以看出,扩容原理就是新创建一个相同类型的新数组,同时将老数组中的数据复制到新数组中间去。
其实,继续追踪System.arraycopy的具体实现,可以引出另外一个问题:
public static native void arraycopy(Object src, int srcPos, Object dest, int destPos, int length);
啊哈,JDK中根本看不见System.arraycopy的源代码。却发现了native这个关键字。
|
tips: 之前没去深入了解过底层的东西,在CSDN中找到一篇简要介绍native关键字的博客。http://blog.csdn.net/youjianbo_han_87/article/details/2586375 下面是博客的原文: native关键字用法 native是与C++联合开发的时候用的!java自己开发不用的! 使用native关键字说明这个方法是原生函数,也就是这个方法是用C/C++语言实现的,并且被编译成了DLL,由java去调用。 这些函数的实现体在DLL中,JDK的源代码中并不包含,你应该是看不到的。对于不同的平台它们也是不同的。这也是java的底层机制,实际上java就是在不同的平台上调用不同的native方法实现对操作系统的访问的。
native的意思就是通知操作系统, 这个函数你必须给我实现,因为我要使用。 所以native关键字的函数都是操作系统实现的, java只能调用。 java是跨平台的语言,既然是跨了平台,所付出的代价就是牺牲一些对底层的控制,而java要实现对底层的控制,就需要一些其他语言的帮助,这个就是native的作用了。 |
LinkedList底层的具体实现是一个链表结构。
直接看其add方法的源码:
public boolean add(E e) { linkLast(e); return true; }
继续查看linkLast的源码:
void linkLast(E e) { final Node<E> l = last; final Node<E> newNode = new Node<>(l, e, null); last = newNode; if (l == null) first = newNode; else l.next = newNode; size++; modCount++; }
恩,没错。就是在链表末尾添加一个新的节点。
对比ArrayList和LinkedList的区别:
①、底层实现不同,ArrayList底层是数组,LinkedList底层是一个单向链表。
②、从底层实现分析特性:ArrayList擅长于随机访问,但是对中间位置的插入和删除操作较慢;LinkedList则删除与插入和删除操作,随机访问速度较慢。
③、两个list都是通过位置索引编号来查询元素的。
三、Set
Set集合最大的特性是:集合中的元素不能重复。
Set最常被使用的一个功能就是测试归属性,可以很容易的查询某个元素是否在某个Set中。所以,查找就成了Set集合中最重要的操作。通常使用HashSet的实现,它对快速查找进行了优化。
HashSet使用了散列,元素的迭代输出没有任何规律性。
TreeSet 将元素存储在“红-黑树”数据结构中,元素的迭代输出按照递增的方式进行。
LinkedHashSet 使用了散列,看起来它使用了链表来维护元素的插入顺序。
其底层实现后面再专门研究。
四、Queue
队列是一种典型的先进先出FIFO容器。其在并发编程中特别重要。
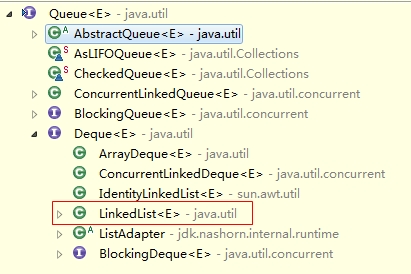
可以看到Queue有很多的具体实现类。但是,现在只关注其中的一个实现类:LinkedList。没错,LinkedList实现了Queue接口,那么我们可以将一个LinkedList向上转型为一个Queue,从而实现基本的FIFO操作。
下面介绍几个和Queue相关的方法:
①、boolean offer(E e)方法在允许的情况下将一个元素插入到队尾,或者返回false。
②、peek()和element()方法将在不移除的情况下返回队头。队列为空,peek()返回null,element()抛出异常。
③、poll()和remove()方法将移除并返回队头。队列为空,poll()返回null,remove()抛出异常。
五、Map
Map具有将对象映射到对象的能力。
Map可以和其它的Collection一样,很容器将其扩展到多维。只需要将其值设置为Map(扩展Map的值可以是其它容器,甚至是其它Map)。所以,Map的组合可以快速的生成强大的数据结构,比如:随机数分布统计应用等。
HashMap 使用散列,查找速度快。插入和查询“键值对”的开销是固定的。可以通过构造器设置容量和负载因子,以调整容器的性能。
TreeMap 基于红黑树的实现。查看“键”或“键值对”时,它们会被排序(次序由Comparable或Comparator决定)。TreeMap的特点在于,所得到的结果是经过排序的。TreeMap是唯一的带有subMap()方法的Map,它可以返回一个子树。
LinkedHashMap 类似于HashMap,但是迭代器遍历它时,取得“键值对”的顺序是其插入时的次序,或者是最近最少使用LRU的次序。只比HashMap慢一点;而在迭代访问时反而更快,因为它使用链表维护内部次序。
后面深入研究Map的具体实现。如果没有特别的限制,应该默认使用HashMap,因为它对速度进行了优化。
Map使用“键”的要求:
①、任何“键”都必须具有一个equals()方法(这也解释了为什么容器中不能放置原始数据类型,而只能放包装数据类型)。
②、如果“键”被用于散列Map,那么它还必须具有恰当的hashCode()方法。
③、如果“键”被用于TreeMap,它必须实现Comparable接口。
六、Foreach与迭代器
看一个foreach很简单的例子:
void foreachTest(){ int[] arr = {1,2,3,4,5,6,7,8}; for(int i : arr){ System.out.print(i + " "); } }
很简洁的就输出了数组中的所有元素,根本不需要关心数组中元素的个数。
foreach能够用于数组,那么,能够用于上面介绍的容器吗?如果我们自己定义一个奇葩容器,它能用foreach输出吗?
原理:foreach之所以能够工作,是因为java SE5引入了新的被称为Iterable的接口,该接口包含了一个能够产生Iterator对象的iterator()方法,并且Iterable接口被foreach用来在序列中移动。所以,不难理解,如果你创建了任何实现Iterable接口的类都能够将它用于foreach语句中。
为了印证上面对于foreach的原理,下面定义一个类,它实现了Iterable接口,那么这个类的对象就可以应用于foreach语句中。
1 import java.util.*; 2 public class IterableTest implements Iterable<String>{ 3 private String[] str = {"aaa","bbb","ccc","ddd","eee"}; 4 5 //重写iterator()方法,使得其支持foreach 6 public Iterator<String> iterator() { 7 return new Iterator<String>(){//匿名内部类 8 private int index = 0; 9 public boolean hasNext() { 10 if(index < str.length){ 11 return true; 12 } 13 return false; 14 } 15 public String next() { 16 return str[index++]; 17 } 18 }; 19 } 20 21 //测试看IterableTest对象是否能够运用于foreach中 22 public static void main(String[] args){ 23 IterableTest itrTst = new IterableTest(); 24 for(String str : itrTst){//IterableTest 对象用于foreach语句中 25 System.out.print(str + " "); 26 } 27 } 28 }
现在提出一个新的问题:对于IterableTest 类,我们希望在默认前向迭代器的基础上,添加产生反向迭代器的能力。因此,我们不能够使用覆盖,而是添加一个能够产生Iterable对象的方法,该方法可以用于foreach语句。
改造代码如下:
1 import java.util.*; 2 public class IterableTest implements Iterable<String>{ 3 4 private String[] str = {"aaa","bbb","ccc","ddd","eee"}; 5 6 //重写iterator()方法,使得其支持foreach 7 public Iterator<String> iterator() { 8 return new Iterator<String>(){//匿名内部类 9 private int index = 0; 10 11 public boolean hasNext() { 12 if(index < str.length){ 13 return true; 14 } 15 return false; 16 } 17 public String next() { 18 return str[index++]; 19 } 20 }; 21 } 22 /* 23 * 通过reversed()方法得到一个Iterable对象,该对象重写了 24 * iterator()方法实现了反向迭代器的功能 25 */ 26 public Iterable<String> reversed(){ 27 return new Iterable<String>(){ 28 public Iterator<String> iterator() { 29 return new Iterator<String>(){ 30 private int current = str.length - 1; 31 32 public boolean hasNext() { 33 if(current >= 0){ 34 return true; 35 } 36 return false; 37 } 38 39 public String next() { 40 return str[current--]; 41 } 42 }; 43 } 44 }; 45 } 46 47 //测试看IterableTest对象是否能够运用于foreach中 48 public static void main(String[] args){ 49 IterableTest itrTst = new IterableTest(); 50 for(String str : itrTst){//正向迭代器 51 System.out.print(str + " "); 52 } 53 54 System.out.println(); 55 for(String str : itrTst.reversed()){//反向迭代器 56 System.out.print(str + " "); 57 } 58 } 59 }
以上是关于2容器初探的主要内容,如果未能解决你的问题,请参考以下文章