阿里深度兴趣网络模型paper学习
Posted 笨兔勿应
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了阿里深度兴趣网络模型paper学习相关的知识,希望对你有一定的参考价值。
论文地址:Deep Interest Network for Click-Through Rate ...
这篇论文来自阿里妈妈的精准定向检索及基础算法团队。文章提出的Deep Interest Network (DIN),实现了推荐系统CTR预估模型中,对用户历史行为数据的进一步挖掘。同时,文章中提出的Dice激活函数和自适应正则方法也优化了模型的训练过程。
Motivation
CTR预估任务是,根据给定广告、用户和上下文情况等信息,对每次广告的点击情况做出预测。其中,对于用户历史行为数据的挖掘尤为重要,从这些历史行为中我们可以获取更多的关于用户兴趣的信息,从而帮助作出更准确的CTR预估。
许多应用于CTR预估的深度模型已经被提出。它们的基本思路是将原始的高维稀疏特征映射到一个低维空间中,也即对原始特征做了embedding操作,之后一起通过一个全连接网络学习到特征间的交互信息和最终与CTR之间的非线性关系。这里值得注意的一点是,在对用户历史行为数据进行处理时,每个用户的历史点击个数是不相等的,我们需要把它们编码成一个固定长的向量。以往的做法是,对每次历史点击做相同的embedding操作之后,将它们做一个求和或者求最大值的操作,类似经过了一个pooling层操作。论文认为这个操作损失了大量的信息,于是引入attention机制,提出一种更好的表示方式。
DIN方法基于对用户历史行为数据的两个观察:1、多样性,一个用户可以对多种品类的东西感兴趣;2、部分对应,只有一部分的历史数据对目前的点击预测有帮助,比如系统向用户推荐泳镜时会和用户点击过的泳衣产生关联,但是跟用户买的书就关系不大。于是,DIN设计了一个attention结构,对用户的历史数据和待估算的广告之间部分匹配,从而得到一个权重值,用来进行embedding间的加权求和。
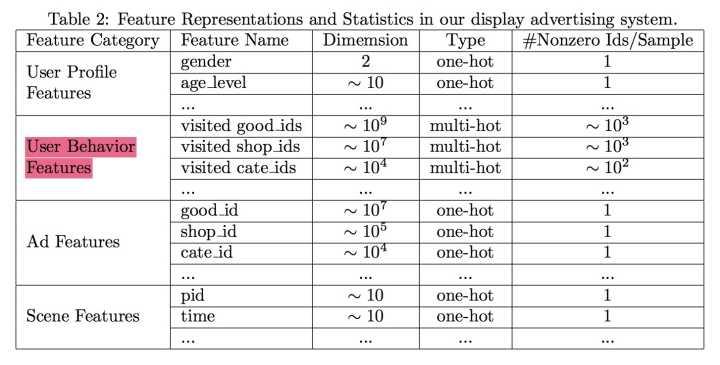
Model
- 模型结构
传统深度模型和DIN模型的对比如下图:
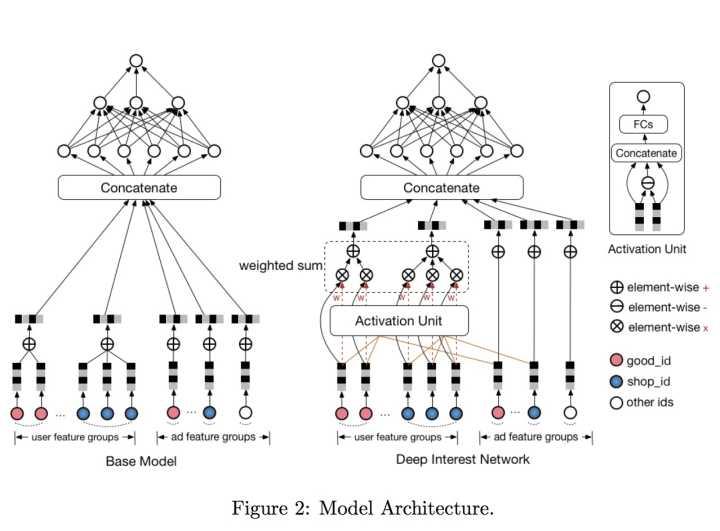
DIN模型在对用户的表示计算上引入了attention network (也即图中的Activation Unit) 。DIN把用户特征、用户历史行为特征进行embedding操作,视为对用户兴趣的表示,之后通过attention network,对每个兴趣表示赋予不同的权值。这个权值是由用户的兴趣和待估算的广告进行匹配计算得到的,如此模型结构符合了之前的两个观察——用户兴趣的多样性以及部分对应。attention network 的计算公式如下, 代表用户表示向量,
代表用户兴趣表示向量,
代表广告表示向量:
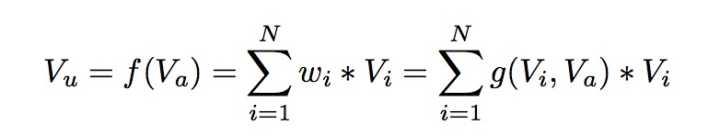
- 模型训练
a. 评价指标
不同于以往CTR模型采用AUC作为评价指标,论文采用的评价指标是自己设计的GAUC评价指标,并且实践证明了该评价指标更可靠。
AUC的含义是正样本得分比负样本得分高的概率。在CTR的实际应用场景中,CTR预测常被应用于对每个用户的候选广告进行排序,也即最终想得到的效果是每个用户的AUC达到最高。同时,不同用户的AUC之间也确实存在差别,有的用户天生点击率就高,有的用户却不怎么喜欢点击广告。
以往的评价指标是对样本不区分用户地进行AUC计算。论文采用的GAUC计算了用户级别的AUC,在将其按展示次数进行加权,消除了用户偏差对模型评价的影响,更准确地描述了模型对于每个用户的表现效果。

b. 激活函数
论文提出了一种新的激活函数,实验效果表现优于PReLU,是一种data dependent的激活函数。首先,PReLU的定义如下:
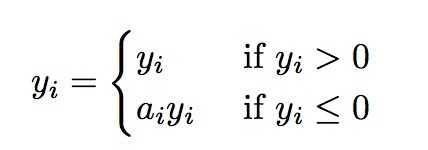
它其实是ReLU的改良版,ReLU可以看作是 ,相当于输出
经过了一个在0点的阶跃整流器。由于ReLU在
小于0的时候,梯度为0,可能导致网络停止更新,PReLU对整流器的左半部分形式进行了修改,使得
小于0时输出不为0。
然而论文里认为,对于所有输入不应该都选择0点为整流点。于是提出了一种data depende- nt的方法,并称该激活函数为Dice函数,形式如下:
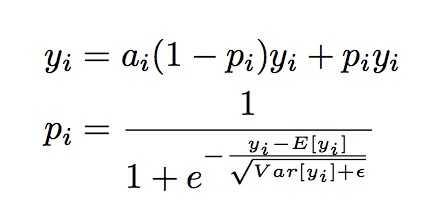
可以看出, 值这个概率值决定着输出是取
或者是
,
也起到了一个整流器的作用。这里注意获取
的两步操作:首先,对
进行均值归一化处理,这使得整流点是在数据的均值处,实现了data dependent的想法;其次,经过一个sigmoid函数的计算,得到了一个0到1的概率值,巧合的是最近google提出的Swish函数形式为
在多个实验上证明了比ReLU函数
表现更优。
c. 自适应正则
在CTR预估任务中,用户行为数据具有长尾分布的特点,也即数据非常的稀疏。为了防止模型过拟合,论文设计了一个自适应的正则方法。


代表了特征
出现的频率。该正则项惩罚了出现频率低的item,取得了不错的效果。
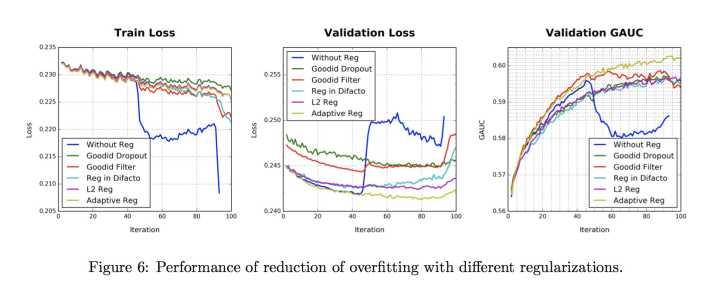
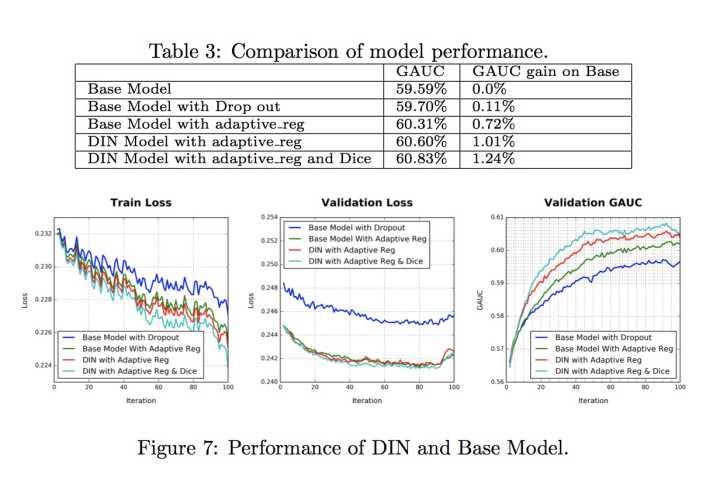
Result
可以看到DIN的效果好于Base模型,同时Dice激活函数和自适应正则都为模型效果带来提升。
Innovation
- 论文着力于在CTR预估任务中对用户历史数据的挖掘。基于对用户兴趣的两个观察——兴趣多样性和兴趣与广告部分对应,提出了深度兴趣网络DIN。
- DIN的主要想法是,在对用户的表示上引入了attention机制,也即对用户的每个兴趣表示赋予不同的权值,这个权值是由用户的兴趣和待估算的广告进行匹配计算得到的。这个想法和seq2seq模型中attention的想法类似,seq2seq模型中对应每个输出
都会通过attention结构学习得到一个输入的表示
,改变以往用固定向量表示的方式,使得网络学习更加灵活。
- DIN在训练过程和评价指标上都有一些技巧,尤其论文中提出了Dice激活函数和自适应正则为模型效果都带来了提升
以上是关于阿里深度兴趣网络模型paper学习的主要内容,如果未能解决你的问题,请参考以下文章