1.记录(record)
适用于小数据,并且用属性名方便查找
2.Key/Value 类型
a.属性列表
就是类似[{Key, Value}]的列表,可以通过proplists模块来处理这样的列表
当涉及到下面的操作的时候,proplists的性能要比lists还差
Bifs: keymember/3, keysearch/3, keyfind/3
b.有序字典 orddict
基于lists实现的有序字典,每个键只出现一次,并且插入会重新排序(也就是整个列表重新排序咯),还有一个是dict,一样的接口,但是dict判断是用=:=,orddict用==
当元素小于75个的时候,在复杂性和效率之间做了很好的平衡(不过谁用的时候还看是不是小于75个??)
c.散列字典 dict
dict是基于散列存储数据的,所以增删和查找的速度都很快,综合了数组和链表的优点,而且dict比orddict而言可以存储大数据。
d.平衡树gb_trees
根据《erlang趣学指南》字典的读取性能最好,GB树在其他方面的性能就更快一些,不过当需要排序的时候自然只能选择二叉树
总的选择顺序是:dict/gb_trees > lists > orddict
当然了,当数据量小的时候,只考虑方便使用和可读行好的结构,最后附上一张图
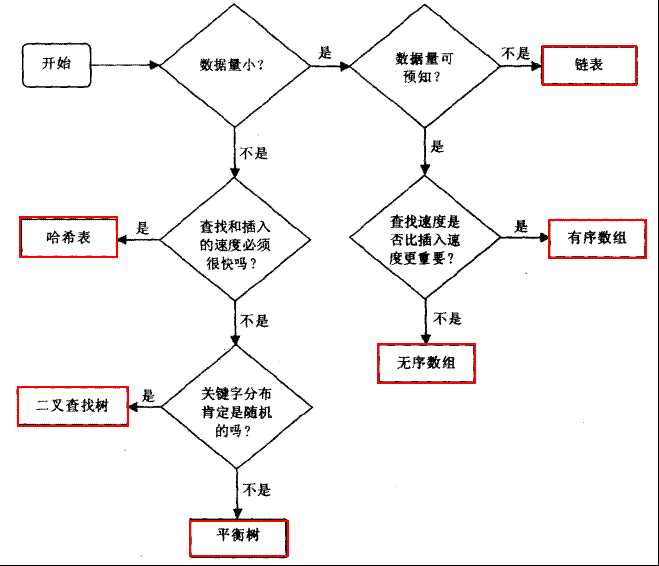
3.集合
a.ordsets 适用小数据,最慢的一种集合,同样基于lists实现的,这说明什么呢,如果我们自己要实现某种结构,没有算法支持少用lists做底层
b.sets 和dict相似,那么也支持大数据,也是读取性能比较好
c.gb_sets
The complexity on set operations is bounded by either O(|S|) or O(|T| * log(|S|)), where S is the largest given set, depending on which is fastest for any particular function call. For operating on sets of almost equal size, this implementation is about 3 times slower than using ordered-list sets directly. For sets of very different sizes, however, this solution can be arbitrarily much faster; in practical cases, often 10-100 times. This implementation is particularly suited for accumulating elements a few at a time, building up a large set (> 100-200 elements), and repeatedly testing for membership in the current set.
As with normal tree structures, lookup (membership testing), insertion, and deletion have logarithmic complexity.
官方文档,在生成集合操作的复杂度比ordset慢3倍,更适合一次插入100-200以上的情况,另外,查找,插入,删除都是对数复杂度。
d.sofs 用于处理集合和集合之间的关系
4.有向图
digraph digraph_utils
5.队列
queue采用两个list来实现,效率也很高,之前还被考过,有空看一下源码怎么写的==
参考: