作者:JSong 时间:2017.12
我想通过几篇文章,给评分卡的全流程一个中等粒度的介绍。另外我的本职工作不是消费金融的数据分析,所以本系列的文章会偏技术一些。
- 数据分析工具主要有Python3及pandas、sklearn等科学计算包,另外也会有自己的工具包reportgen。
- 信用记录数据采用Lending Club的公开数据,特征数目和样本数都比较理想。大家可以到官网(www.lendingclub.com)下载,或者关注我的微信公众号后台回复:⌠数据集 ⌡ 下载(含变量介绍和中文对照)。
- 为了讲清楚所有事,文章中会包含数学公式和Python实现代码
相信大家都知道自己的芝麻信用分,它可以提高花呗的额度,可以消费贷,可以不缴押金直接租车等。在未来,随着信息化进程越来越快,信用只会越来越重要。从现在开始,我们除了赚钱养家外,还有一项重要的任务就是维护自己的信用。
信用评分卡是一个通过个人数据设法对其还款能力和还款意愿进行定量评估的系统。在消费金融行业,信用评分卡主要有三种(A卡、B卡、C卡):
- A卡:申请评分卡,侧重贷前,
在客户获取期,建立信用风险评分,预测客户带来违约风险的概率大小; - B卡:行为评分卡,侧重贷中,在客户申请处理期,建立申请风险评分模型,预测客户开户后一定时期内违约拖欠的风险概率,有效排除了信用不良客户和非目标客户的申请;
- C卡:催收评分卡,侧重贷后,在帐户管理期,建立催收评分模型,对逾期帐户预测催收策略反应的概率,从而采取相应的催收措施。
简单来讲,评分卡用信用分数来预测客户的好坏,当判定你是一个“好人”时,你就可以享受银行或者金融公司的信用卡服务或者消费贷服务。另外B卡和C卡涉及到很多业务数据,所以本文主要介绍的是A卡。
一套完整的评分卡系统分为如下几个过程:
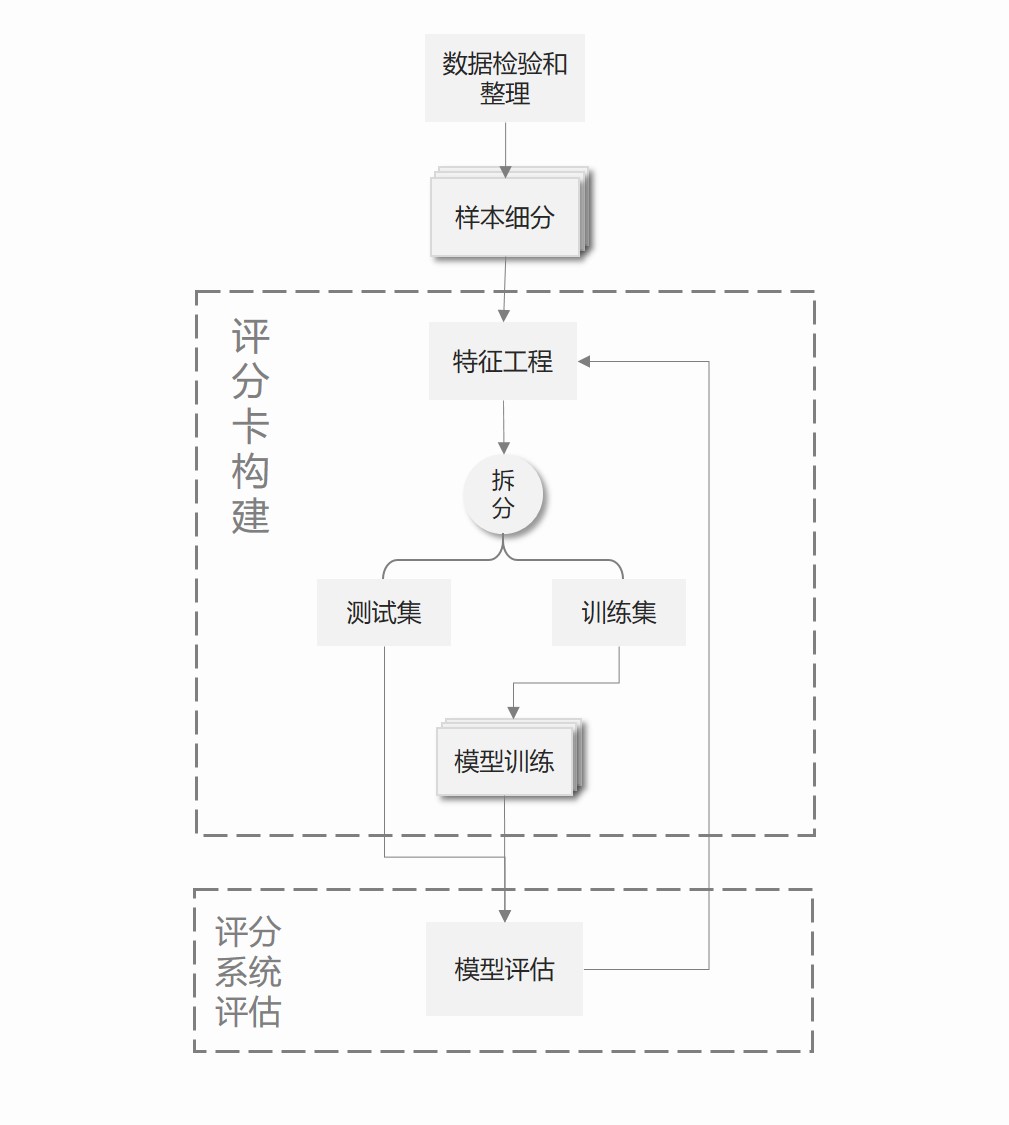
可以看到一共有六大模块,作为评分卡的第一篇文章,我将简单介绍一下每个模块的内容和作用,后续将详细介绍其中的三个模块。
1. 数据检验和整理
数据检验是对数据的有效性进行检验,比如没有150岁的人,或者没有21岁就已持有银行账户超过30岁的人。发现有特殊情况的,用特殊代码如9999标记,但它不应该被简单理解。如果存在缺失数据,规范做法是把它们作为缺失值进行编码,而不是试图估算填入一个实值。虽然这里只用了几句话来讲数据检验,但这其实可能是建立评分卡最耗时的步骤。
2. 样本细分
开始建立评分系统后,首先是决定是否要细分总体并为每部分建立不同的评分卡。例如为25岁以下和25岁以上的人各建立一个评分卡,或者为特殊行业的人建立一个评分卡。建立多个评分卡会带来大量额外的工作,所以只在改进预测效果时使用。
样本细分(segamentation)的理由有如下几个:
- 细分后不同部分的可得信息存在差异
- 某个特征与其他特征相互关联
- 细分方法与贷款机构的经营策略相符
不同细分部分之间的信息差异可能是由可得数据的多少引起的。例如年轻人的数据通常有限,相对年长的人,他们的数据只是一份很“薄”的文档。
如果存在高度相关但又有很强预测能力的几个特征变量时,我们可能会向导将这些特征分开单独使用。这能避免同一评分卡的预测变量相互影响。不过这在实践当中并不多见,通常相关度也没有大到必须要去处理它。
银行也因为要对不同的人采用不同的策略而决定细分样本。比如,相较与低收入人群或者老年人,银行可能对高收入人群或年轻人更主动。建立不同的评分卡并设定合格临界线,会使得交叉销售和追加销售的促销政策实施起来都更加容易。
3. 特征工程
稳健的评分卡通常有10~20个特征变量,而可用的特征远远多于这个数量。为了评分卡的泛化性能和稳健性,我们要剔除变量并且对已有变量进行一些处理。特征工程的主要任务是变量衍生、变量剔除和特征处理和编码。
有一些变量单独使用时可能没有具体的含义,如借款天数,需要进行衍生。
有一些变量区分好坏借款人的能力偏小,跟因变量几乎无关系。还有一些变量与其他确定要使用的变量高度相关甚至存在共线性。还有一些变量在时间上不稳定,很难用于预测。要分析前两个状况,我们可以用卡方和信息量计算特征对因变量的贡献。也可以用逐步回归来确定那些重要的变量。还可以利用正则化(例如岭回归、LASSO回归等)来检测共线性,且使得特征的系数稀疏化。
最初的数据中,特征的类型往往是多样性的,有连续的数值变量(如贷款金额),有无序的分类变量(如性别),也有有序的分类变量(如年龄段),还有还款日期等时间格式的变量、评价等文本型的变量等等。
对于分类变量,类别数目不能过多,要保证每类中含有总体一定百分比(至少5%)的样本数量,这能避免计算属性集分数时过大的样本方差,通过粗分类减少类别数量能提高系统的稳健性。粗分类既是一门科学也是一门艺术,对序数变量来说要尽量保证每类中包含事实上相邻的属性。另外,就算类别数量合适,对于部分算法(如逻辑回归、GBDT等)来说,还是不够。我们要对这些变量进行编码,常用的有哑变量(dumpy)方法和WOE编码,前者将学历变量(高中及以下、本科、硕士及以上)转换成2(为避免共线性,所以只有2个)个变量:是否是高中及以下、是否是本科。后者通过计算每一个类别对因变量的WOE(证据权重)来重编码。
对于连续数值变量,我们也可以将它离散化,也可以成为特征分箱。离散化的方法也有很多种,如等分、等频、卡方分箱等。
4. 训练测试集拆分
这个没啥好讲的,因为评分系统考虑的是其泛化性能,所以要留出一部分数据来评估。如果数据充足,我们倾向于分出20%~30%的样本作为测试集。当然也不是所有情况都得拆分,例如随机森林。
5.模型训练
逻辑回归是最经典的建立评分卡的方法,其最强大的理论优势在于它直接给出了可加的对数比率分数,结果可以快速转化成信用分数。不过逻辑回归的缺点是准确率不足够高,有时候我们也会用集成学习的方法、如GBDT、XGBoost等。这里就不进一步展开各个算法的理论和优劣啦
6. 模型评估
当一个评分卡已经构建完成,并且有一组个人分数和其对应的好坏状态的数据时,我们想知道所构建的评分卡是否可靠?可靠程度如何?而这取决于如何去定义这个“好”字。我们至少有三种角度可以来评估:
- 评分卡分类划分的准确程度,如错误率、准确率、召回率、F1
- 评分卡的判别能力,评估评分卡将好人和坏人分离开的程度,如KS统计量、ROC曲线、GINI系数
- 评分卡概率预测的校准精度
模型训练好后,一般有两种输出值,一种是预测的类别(好人/坏人、0/1),一种是预测的概率,如该样本被判别为坏人的概率值。当然后者可以通过设置阈值转化成前者。
如果已经有了预测类别,那我们可以构建混淆矩阵,然后便可以方便的计算准确率、召回率、F1分数等
| 实际坏人 | 实际好人 | |
|---|---|---|
| 预测坏人 | TP(真正例) | FP(假反例) |
| 预测好人 | FN(假正例) | TN(真反例) |
如果有预测概率,其实际上给的是好人的概率分布和坏人的概率分布。常用的有ROC曲线、KS距离和KL距离
one more thing
本文的最后,我们先来简单看看LendingClub的数据,这里就可以用到reportgen的新功能。之前我们要简单了解一份数据,需要针对每个变量或者每一种类型的变量单独画图。这里我们将这件事封装成了一个函数,并导出为PPTX,这样便于我们在建模过程中反查看数据
我选用的是2016年Q4的数据,原始数共103546条,145个变量。数据获取(含2016Q4、2017Q1、2017Q2、2017Q3、LCDataDictionary)可以关注公众号并回复:⌠数据集 ⌡ 下载
import pandas as pd
import reportgen as rpt
# 字段的中文对照表,暂时只翻译了一部分
datadict=pd.read_excel(\'.\\\\LendingClubData\\\\LCDataDictionary.xlsx\')
columnnew=dict(zip(datadict.loc[datadict[\'中文名称\'].notnull(),\'LoanStatNew\'],datadict.loc[datadict[\'中文名称\'].notnull(),\'中文名称\']))
data=pd.read_csv(\'.\\\\LendingClubData\\\\LoanStats_2016Q4.csv\',skiprows=1)
data=data.rename(columns=columnnew)
# 去除缺失率大于80%的字段
missing_pct=data.apply(lambda x : (len(x)-x.count())/len(x))
data=data.loc[:,missing_pct[missing_pct<0.80].index]
rpt.AnalysisReport(data,\'LendingClub数据概览\');
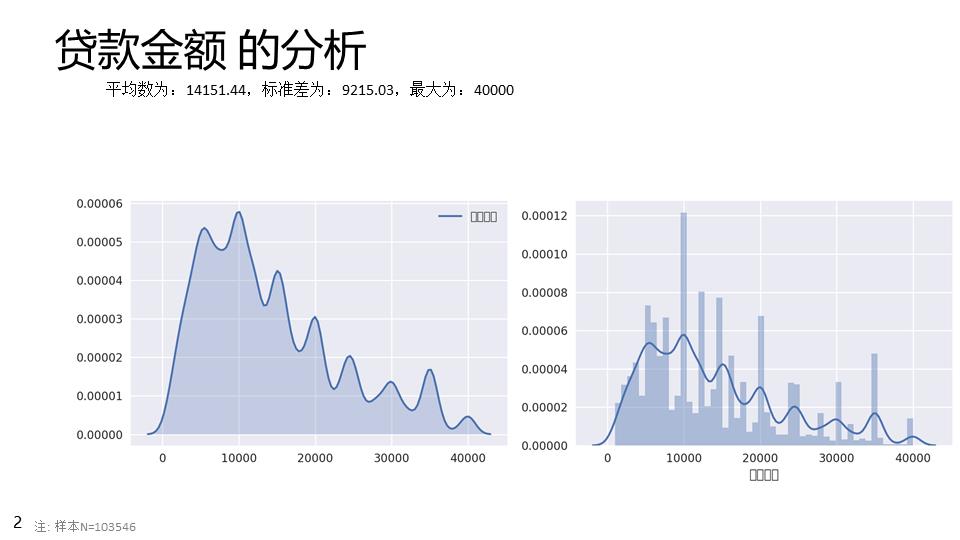
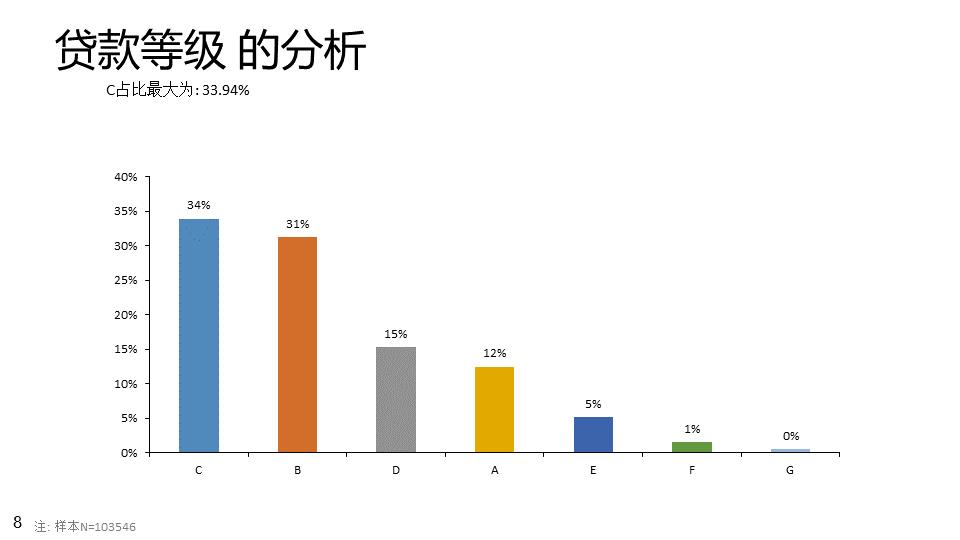
生成的ppt如下:


参考文献
[1]. 消费信用模型:定价、利润与组合
[2]. 利用LendingClub数据建模(网址:https://zhuanlan.zhihu.com/p/21550547 )
本系列文章
评分卡文章系列:
个人公众号,文章首发与此,转载请声明
