与传统的浅层机器学习相比, 深度学习具有优秀的自动提取抽象特征的能力,并且随着分布式计算平台的快速发展,大数据的处理能力得到极大的提升,使得近年来DL在工程界得到广泛的应用,包括图像识别,语音识别,自然语言处理等领域,并取得比传统机器学习更好的效果提升。另一方面,智能推荐系统,本质上是从一堆看似杂乱无章的原始流水数据中,抽象出用户的兴趣因子,挖掘出用户的偏好,因此把深度学习与推荐系统相结合成为近年来DL发展的一个新热点,事实上,Spotify,Netflix,Facebook,Google等公司早已经对如何把深度学习应用到推荐系统中有了很多深入研究,并在实际应用中取得了很好的效果提升 [1]。

本文是深度学习在推荐系统实践应用系列文章的第一篇,详细介绍了如何把受限玻尔兹曼机(Restricted Boltzmann Machine, 下面统一简称RBM)应用到我们当前线上的推荐系统中,包括RBM的原理,在推荐系统的应用及其并行化实现的细节,后面两篇会详细介绍另外两个我们目前正在研究使用的深度神经网络,分别是递归神经网络(Recurrent Neural Network, RNN)和卷积神经网络(Convolutional Neural Network, CNN),详细介绍它们的原理,如何与智能推荐相结合以及线上的模型效果。
之所以把RBM作为第一篇进行讲解,一方面是因为它的结构相对比较简单,是一个只有可视层和隐藏层两层结构的网络;另一方面,从严格意义上说,RBM并不属于深层神经网络,它只是一个两层结构,并不“深”,但它同时也是构成其他深度神经网络的常用层次组件,因此,理解如何把RBM应用到推荐系统上,将有助于理解后面几个更复杂的深度学习算法的应用。
一:受限玻尔兹曼机与推荐系统
1.1 RBM网络结构定义
我们首先给出RBM的网络结构定义,RBM是由可视层和隐藏层相互连接的一个完全二分图网络结构,如下图所示,每一个神经元是一个二值单元,也就是每一个神经元的取值只能等于0或1:
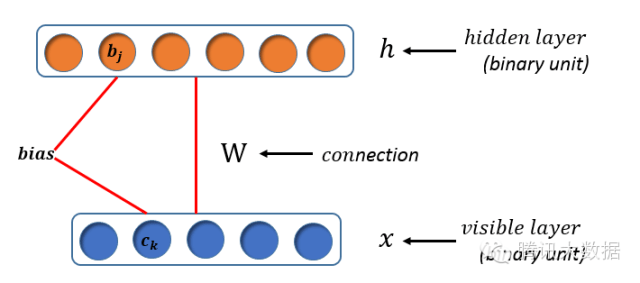
RBM的网络结构具有这样的特点: 可视层的每一个神经元与隐藏层的每一个神经元相互连接;可视层神经元之间,隐藏层神经元之间没有连线,这为我们后面的训练提供了一个很好的假设性条件:同一层的各神经元之间是相互独立的。对上面的网络结构,我们首先来定义下面的参数:

1.2 RBM与协同过滤
上一小节我们对RBM的结构定义进行了简要的阐述,那么怎么把该模型应用到推荐系统中呢?RBM本质上是一个编码解码器,具体来说,通过RBM,我们可以把原始输入数据从可视层映射到隐藏层,得到原始输入数据的隐因子(latent factor)向量表示,这一过程也称为编码过程,然后利用得到的隐藏层向量重新映射回可视层,得到新的可视层数据,这个过程称为解码过程,我们的目标是让解码后的结果能和原始数据尽量接近,这样,在解码的过程中,我们不但能得到已评分物品的新的评分数据,还能对未评分的物品的得分进行预测,这些未评分物品的分数从高到低的排序形成推荐列表。
从上面的分析可以看出,我们将RBM应用到推荐中去要解决下面的两个问题:
1. 如何用可视层来表示用户的听歌流水数据?
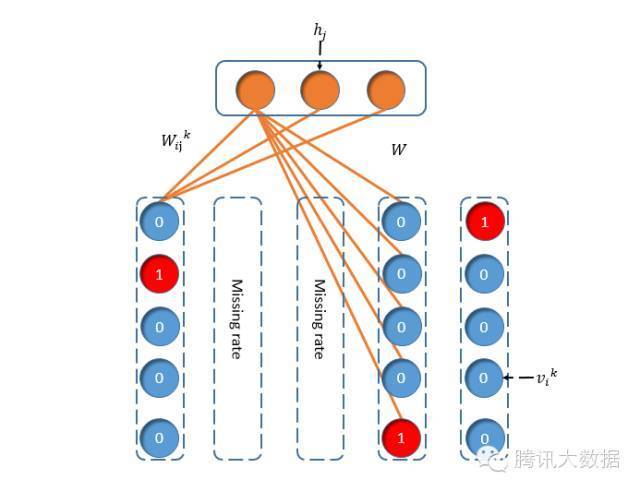
2. 如何处理missing数据?
正如上一段我们提到,用户的原始输入数据只对部分极少数的歌曲有评分,对没有评分的歌曲对应的神经元,也就是上图中的missing神经元,在训练权重时我们并不考虑这部分数据,每一个用户的数据将构成一个独立的RBM子模型,每一个用户的子模型只对其中关联到的权重值调整做出贡献,同理,每一个权重值的参数更新只由与该权重值相关联的用户数据来决定。
下面我们来看看修正的RBM模型对数据编码和解码的过程:
编码过程:利用原始数据,我们求取隐藏层的隐向量表示,这个过程是由条件概率公式求得:
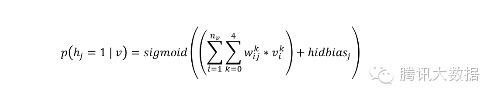
下图是编码过程的动态图展示:
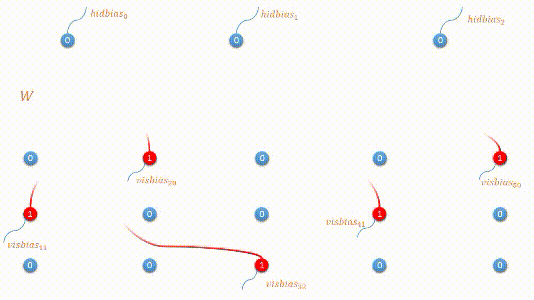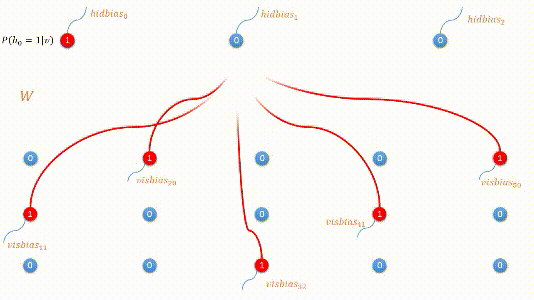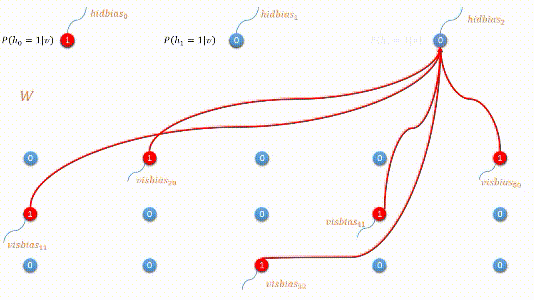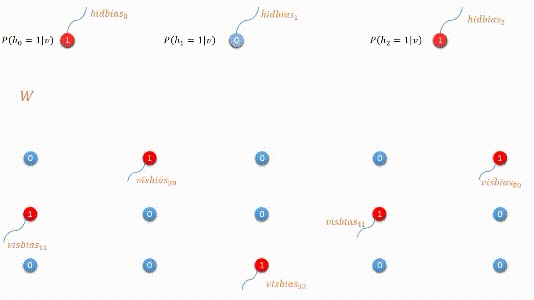


二:模型最优化 - 对比散度(contrastive divergence)
通过第一部分的叙述,我们已经知道了RBM的网络结构以及如何与推荐系统相结合,那么现在我们的问题就是如何训练模型,对于RBM来说,就是要训练出三个权重参数: 连接可视层与隐藏层的权重W,可视层结点的偏移量visbias,隐藏层结点的偏移量hidbias。
对于机器学习模型来说,我们首先要确定我们的目标训练函数是什么,对于RBM模型,它本质上是一个编码解码的过程,因此我们很自然的想法是:期望经过RBM编码和解码后的数据与原始的输入数据尽量接近,这也是最大似然参数估计的思想,即我们的最优化目标函数为:
训练RBM的最大困难在于负梯度的计算,Hinton教授于2002年提出了对比散度的算法,它有效解决了RBM训练速度的难题,也是当前RBM的标准训练算法,对比散度的思想是通过一种合理的采样方法, 以较少的采样样本来近似负梯度的所有组合空间,具体实现过程就是:我们从原始的输入数据出发,经过编码解码后得到新的可视层输入,这一个过程称为1步Gibbs采样,然后利用经过相同的过程,得到,重复这个过程次,最后得到,这个值就是最后负梯度的近似,这个过程被称为步Gibbs采样过程,下图就是步Gibbs采样过程的动态图展示:


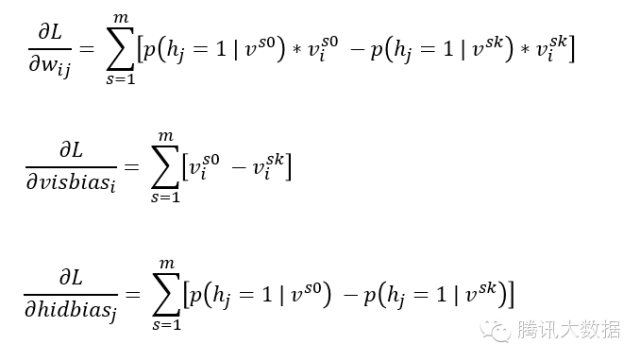
三:对比散度的并行化实现
当前对RBM的并行化训练已经有比较成熟的平台,如Theano,Caffe,TensorFlow等,我们在实现的过程没有采用上面的平台架构,而是采用了spark集群来训练,对比散度训练RBM过程本质上是一个梯度下降的最优化过程,下图是算法在spark的执行流程图:
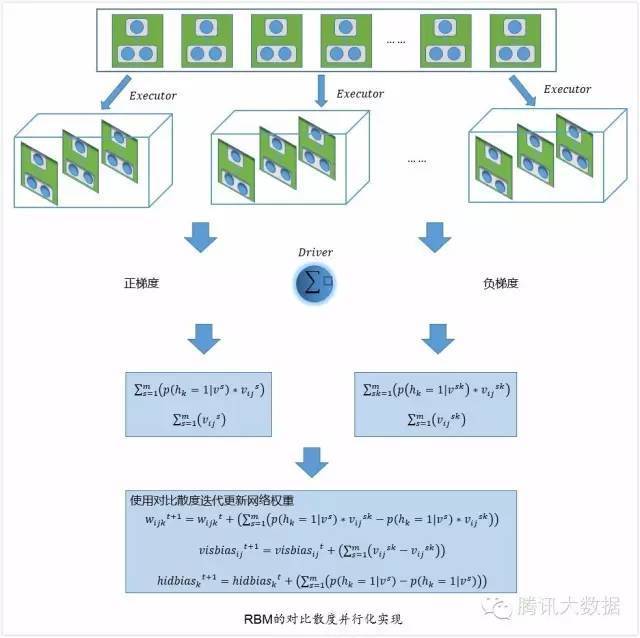
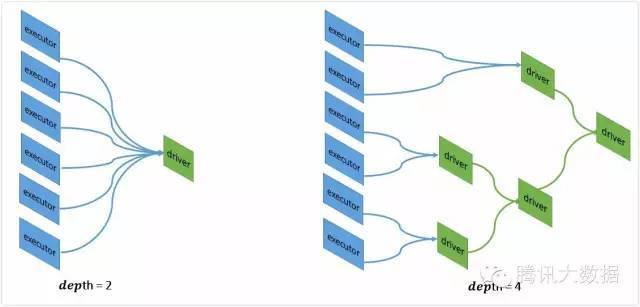
根据前面的描述,每一个用户的数据构成一个RBM子网络,集群首先是对数据和子模型进行切分,模型和数据在运行的过程中将被分配到不同的executor中执行,得到每一个子模型的正梯度以及k步Gibbs采样后的负梯度,然后子结果传送回driver端进行合并,一般来说为了防止全部数据返回造成driver端的网络通讯压力以及内存压力,我们可以采用树聚合的方式来优化,下图是树深度为2和树深度为4的效果图,注意不同线条的颜色代表数据在不同的单元中传输,从图中可以看出,深度越大,计算的步骤会变长,但每一次传输到driver的数据会减少,可以防止driver端内存溢出的问题。
四:线上模型融合
经过前面三节的分析,我们已经对RBM如何作用于推荐系统,RBM模型的训练等都有了比较深入的了解,最后我们需要利用训练好的模型来生成推荐数据并与其他算法模型进行融合,对推荐结果数据的计算,是利用已经训练完的权重参数,对输入数据进行一次编解码的过程,解码后的新数据,不但能重新生成已经操作过的数据的得分,还能对未操作过的数据预测得分,也就是1.2节的missing数据,这些missing数据的得分帮助我们对推荐数据进行排序。
要实现这个过程,我们有下面两种做法:一是直接离线批量生成所有用户的数据,但这种做法的计算量非常巨大;二是把训练好的权重单独保存,推荐数据的生成放到在线层实时计算,如下图所示:
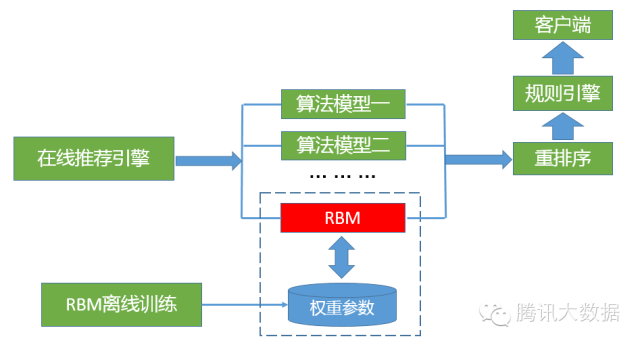
在应用中,我们采用的是第二种方法,这种做法相比第一种方法的好处有两个:一是结果不依赖于离线任务,防止了离线任务的失败对线上数据的影响;二是线上实时计算的结果数据能够与现有的算法模型数据的融合更加灵活,包括后续数据处理的规则过滤,重排序等。
五:小结
本文详细分析了RBM在推荐系统中的应用,从文中分析可以看出,RBM对推荐系统的提升主要得益于它具有自动提取抽象特征的能力,这也是深度学习作用于推荐系统的基础。后面的文章中,将继续分析RNN和CNN如何在提取抽象特征的基础上,进一步提升推荐系统的性能。