转:NLP+句法结构︱中文句法结构(CIPS2016依存句法文法)
Posted 微冷不觉寒
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了转:NLP+句法结构︱中文句法结构(CIPS2016依存句法文法)相关的知识,希望对你有一定的参考价值。
NLP+句法结构(三)︱中文句法结构(CIPS2016、依存句法、文法)转自:https://www.cnblogs.com/maohai/p/6453389.html
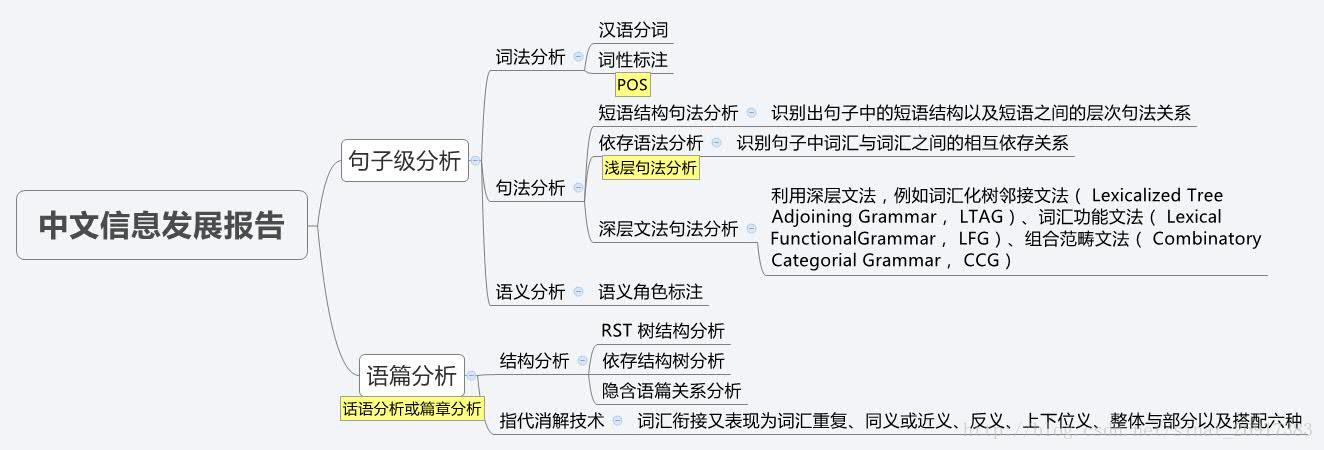
摘录自:CIPS2016 中文信息处理报告《第一章 词法和句法分析研究进展、现状及趋势》P8 -P11
CIPS2016> 中文信息处理报告下载链接:http://cips-upload.bj.bcebos.com/cips2016.pdf

一、依存句法分析
依存语法存在一个共同的基本假设:句法结构本质上包含词和词之间的依存(修饰)关系。一个依存关系连接两个词,分别是核心词( head)和依存词( dependent)。依存关系可以细分为不同的类型,表示两个词之间的具体句法关系。
目前研究主要集中在数据驱动的依存句法分析方法,即在训练实例集合上学习得到依存句法分析器,而不涉及依存语法理论的研究。数据驱动的方法的主要优势在于给定较大规模的训练数据,不需要过多的人工干预,就可以得到比较好的模型。因此,这类方法很容易应用到新领域和新语言环境。数据驱动的依存句法分析方法主要有两种主流方法:基于图( graph-based)的分析方法和基于转移( transition-based)的分析方法
1、基于图的依存句法分析方法
基于图的方法将依存句法分析问题看成从完全有向图中寻找最大生成树的问题。一棵依存树的分值由构成依存树的几种子树的分值累加得到。根据依存树分值中包含的子树的复杂度,基于图的依存分析模型可以简单区分为一阶和高阶模型。
高阶模型可以使用更加复杂的子树特征,因此分析准确率更高,但是解码算法的效率也会下降。基于图的方法通常采用基于动态规划的解码算法,也有一些学者采用柱搜索(beamsearch)来提高效率。学习特征权重时,通常采用在线训练算法,如平均感知器( averagedperceptron)。
2、基于转移的依存句法分析方法
基于转移的方法将依存树的构成过程建模为一个动作序列,将依存分析问题转化为寻找最优动作序列的问题。 早期,研究者们使用局部分类器(如支持向量机等)决定下一个动作。近年来,研究者们采用全局线性模型来决定下一个动作,一个依存树的分值由其对应的动作序列中每一个动作的分值累加得到。特征表示方面,基于转移的方法可以充分利用已形成的子树信息,从而形成丰富的特征,以指导模型决策下一个动作。模型通过贪心搜索或者柱搜索等解码算法找到近似最优的依存树。和基于图的方法类似,基于转移的方法通常也采用在线训练算法学习特征权重。
3、多模型融合的依存句法分析方法
基于图和基于转移的方法从不同的角度解决问题,各有优势。基于图的模型进行全局搜索但只能利用有限的子树特征,而基于转移的模型搜索空间有限但可以充分利用已构成的子树信息构成丰富的特征。详细比较发现,这两种方法存在不同的错误分布。因此,研究者们使用不同的方法融合两种模型的优势,常见的方法有:stacked learning;对多个模型的结果加权后重新解码(re-parsing);从训练语料中多次抽样训练多个模型(bagging)。
.
.
二、短语结构句法分析
短语结构句法分析的研究基于上下文无关文法( Context Free Grammar, CFG)。
上下文无关文法可以定义为四元组 【T, N, S, R】,其中 T 表示终结符的集合(即词的集合), N 表示非终结符的集合(即文法标注和词性标记的集合), S 表示充当句法树根节点的特殊非终结符,而 R 表示文法规则的集合,其中每条文法规则可以表示为 Ni-r ,这里的r表示由非终结符与终结符组成的一个序列(允许为空)。
.
.
三、深层文法句法分析
1、词汇化树邻接文法,简称 LTAG
对树邻接文法( TAG)进行词汇化扩展得到的。。在树邻接文法中,有两种子树操作:替换( Substitution)和插接( Adjunction)。
词汇化语法是给所有基本树都和具体词关联起来,使得树更加具有个性化。
2、词汇功能文法,简称 LFG
LFG 把语言看成是由多维结构组成的,每一维都用特殊规则、概念和格式表示成一个特殊结构
LFG 包含两种最基本的结构:
1) F-结构,用于表示语法功能; 2) C-结构,用于表示句法功能。除此之外还有一些其他结构,用于表示浅层信息,例如谓词论元关系等。
3、组合范畴文法,简称 CCG
一种类型驱动的词汇化文法,通过词汇范畴显式地提供从句法到语义的接口,属于短语结构文法
.
.
四、深度学习的句法分析
深度学习则把原子特征进行向量化,在利用多层神经元网络提取特征。所谓向量化就是把词、词性等用低维、连续实数空间上的向量来表示,从而便于寻找特征组合与表示,同时容易进行计算。 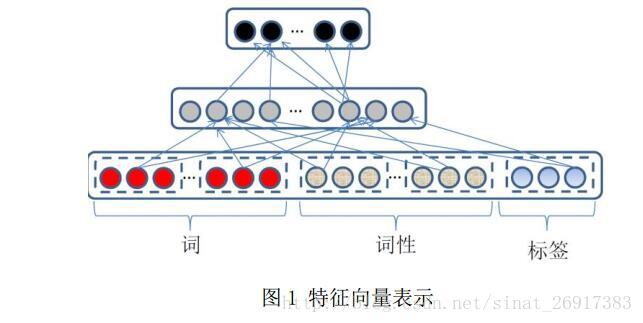
在图 1 中,把词、词性、类别标签等原子特征表示为向量,然后利用多层网络进行特征提取。深度学习在特征表示方面有如下优点:
1)只需要原子特征。这些原子特征以前是通过人工的自由组合形成最终的一元特征、二元特征、三元特征、四元特征甚至更多元的组合。
这种人工组合最后取得较好的效果,但是事实上我们不知道怎么组合能形成最佳的特征集合。深度学习将所有的原子特征向量化之后,直接采用向量乘法以及非线性等各种运算从理论上能实现任意元的特征组合。
2)能使用更多的原子特征。比如基于图的模型中,在建立弧时,不仅仅使用左边第一个词、右边第一个词等原子特征,还可以使用左边整个词序列、右边整个词序列的特征。研究人员把这种基于深度学习的特征表示方法分别应用在基于图的句法分析模型和基于转移的句法分析模型上,实验结果表明深度学习方法开始在句法中发挥作用。
以上是关于转:NLP+句法结构︱中文句法结构(CIPS2016依存句法文法)的主要内容,如果未能解决你的问题,请参考以下文章