Kylin与CDH兼容性剖析
Posted 哥不是小萝莉
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kylin与CDH兼容性剖析相关的知识,希望对你有一定的参考价值。
1. 概述
Apache Kylin™是一个开源的分布式分析引擎,提供Hadoop之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由eBay Inc. 开发并贡献至开源社区。它能在亚秒内查询巨大的Hive表。
2. 内容
在集成Kylin到CDH Hadoop环境中时,发现新版本Kylin-2.2.0无法集成到CDH Hadoop。环境信息如下:
- Hadoop:CDH-5.4.2,Hadoop-2.6
- Hive:Hive-2.1.1
- HBase:CDH-5.4.2,HBase-1.0.0
上述版本,如果使用apache-kylin-2.2.0-bin-cdh57.tar.gz集成,Kylin系统可以正常启动,但是在预编译Cube,将编译的结果写入HBase时会出现对应的类找不到。去翻阅CDH-HBase-1.0.0的源代码确实没有对应的类。在Kylin的JIRA中也有记录该现象,大家可以翻阅问题单:[KYLIN-1089]
2.1 Patch
针对该问题可以编辑源代码后,重新编译。需要注意的是,如果你想将pom.xml文件中的属性“hbase-hadoop2.version”改为“1.0.0-cdh5.4.2”,在编译的时候会出现“org.apache.hadoop.hbase.regionserver.ScannerContext.java”找不到。确实,在CDH版的HBase-1.0.0版本中该类不存在,在CDH中最低支持5.5.4,对应的Patch代码如下所示:
From c0e053d16fc8fa36947e6181589505b722ea54dd Mon Sep 17 00:00:00 2001 From: shaofengshi <shaofengshi@apache.org> Date: Fri, 11 Nov 2016 08:41:57 +0800 Subject: [PATCH] KYLIN-1089 support CDH 5.5/hbase1.0 --- pom.xml | 12 ++++++------ .../v1/coprocessor/observer/AggregateRegionObserver.java | 4 ++-- .../hbase/cube/v1/filter/TestFuzzyRowFilterV2EndToEnd.java | 3 +-- 3 files changed, 9 insertions(+), 10 deletions(-) diff --git a/pom.xml b/pom.xml index 9b84f23..8352e97 100644 --- a/pom.xml +++ b/pom.xml @@ -46,19 +46,19 @@ <project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding> <!-- Hadoop versions --> - <hadoop2.version>2.6.0-cdh5.7.0</hadoop2.version> - <yarn.version>2.6.0-cdh5.7.0</yarn.version> + <hadoop2.version>2.6.0-cdh5.5.4</hadoop2.version> + <yarn.version>2.6.0-cdh5.5.4</yarn.version> <!-- Hive versions --> - <hive.version>1.1.0-cdh5.7.0</hive.version> - <hive-hcatalog.version>1.1.0-cdh5.7.0</hive-hcatalog.version> + <hive.version>1.1.0-cdh5.5.4</hive.version> + <hive-hcatalog.version>1.1.0-cdh5.5.4</hive-hcatalog.version> <!-- HBase versions --> - <hbase-hadoop2.version>1.2.0-cdh5.7.0</hbase-hadoop2.version> + <hbase-hadoop2.version>1.0.0-cdh5.5.4</hbase-hadoop2.version> <kafka.version>0.8.1</kafka.version> <!-- Hadoop deps, keep compatible with hadoop2.version --> - <zookeeper.version>3.4.5-cdh5.7.0</zookeeper.version> + <zookeeper.version>3.4.5-cdh5.5.4</zookeeper.version> <curator.version>2.7.1</curator.version> <jackson.version>2.2.4</jackson.version> <jsr305.version>3.0.1</jsr305.version> diff --git a/storage-hbase/src/main/java/org/apache/kylin/storage/hbase/cube/v1/coprocessor/observer/AggregateRegionObserver.java b/storage-hbase/src/main/java/org/apache/kylin/storage/hbase/cube/v1/coprocessor/observer/AggregateRegionObserver.java index 7e25e4c..7139ca7 100644 --- a/storage-hbase/src/main/java/org/apache/kylin/storage/hbase/cube/v1/coprocessor/observer/AggregateRegionObserver.java +++ b/storage-hbase/src/main/java/org/apache/kylin/storage/hbase/cube/v1/coprocessor/observer/AggregateRegionObserver.java @@ -26,7 +26,7 @@ import org.apache.hadoop.hbase.client.Scan; import org.apache.hadoop.hbase.coprocessor.BaseRegionObserver; import org.apache.hadoop.hbase.coprocessor.ObserverContext; import org.apache.hadoop.hbase.coprocessor.RegionCoprocessorEnvironment; -import org.apache.hadoop.hbase.regionserver.Region; +import org.apache.hadoop.hbase.regionserver.HRegion; import org.apache.hadoop.hbase.regionserver.RegionCoprocessorHost; import org.apache.hadoop.hbase.regionserver.RegionScanner; import org.apache.kylin.gridtable.StorageSideBehavior; @@ -99,7 +99,7 @@ public class AggregateRegionObserver extends BaseRegionObserver { // start/end region operation & sync on scanner is suggested by the // javadoc of RegionScanner.nextRaw() // FIXME: will the lock still work when a iterator is returned? is it safe? Is readonly attribute helping here? by mhb - Region region = ctxt.getEnvironment().getRegion(); + HRegion region = ctxt.getEnvironment().getRegion(); region.startRegionOperation(); try { synchronized (innerScanner) { diff --git a/storage-hbase/src/test/java/org/apache/kylin/storage/hbase/cube/v1/filter/TestFuzzyRowFilterV2EndToEnd.java b/storage-hbase/src/test/java/org/apache/kylin/storage/hbase/cube/v1/filter/TestFuzzyRowFilterV2EndToEnd.java index 04e2e8b..4e87093 100644 --- a/storage-hbase/src/test/java/org/apache/kylin/storage/hbase/cube/v1/filter/TestFuzzyRowFilterV2EndToEnd.java +++ b/storage-hbase/src/test/java/org/apache/kylin/storage/hbase/cube/v1/filter/TestFuzzyRowFilterV2EndToEnd.java @@ -44,7 +44,6 @@ import org.apache.hadoop.hbase.filter.FilterList; import org.apache.hadoop.hbase.filter.FilterList.Operator; import org.apache.hadoop.hbase.regionserver.ConstantSizeRegionSplitPolicy; import org.apache.hadoop.hbase.regionserver.HRegion; -import org.apache.hadoop.hbase.regionserver.Region; import org.apache.hadoop.hbase.regionserver.RegionScanner; import org.apache.hadoop.hbase.util.Bytes; import org.apache.hadoop.hbase.util.Pair; @@ -225,7 +224,7 @@ public class TestFuzzyRowFilterV2EndToEnd { scan.addFamily(cf.getBytes()); scan.setFilter(filter); List<HRegion> regions = TEST_UTIL.getHBaseCluster().getRegions(table.getBytes()); - Region first = regions.get(0); + HRegion first = regions.get(0); first.getScanner(scan); RegionScanner scanner = first.getScanner(scan); List<Cell> results = new ArrayList<Cell>(); -- 2.7.2
安装上述Patch文件中的内容,修改Kylin源代码文件中的内容后,在apache-kylin-2.2.0-bin/build/script/目录中运行package.sh脚本进行编译打包。
2.2 升级HBase版本
由于apache-kylin-2.2.0使用的是HBase1.1.x版本进行编译的,如果不编译Kylin源代码,可以通过升级HBase版本到1.1.x以上。比如,将CDH版的hbase-1.0.0-cdh5.4.2升级到hbase-1.2.0-cdh5.7.0版本。具体升级步骤比较简单这里就不多赘述了。
3. 实战演练
在Kylin-2.2.0中,省略了很多繁琐的配置,许多配置项都改为默认的配置属性了。只需在$KYLIN_HOME/conf目录中,编辑kylin.properties文件,配置如下属性值:
kylin.rest.servers=0.0.0.0:7070 kylin.job.jar=/data/soft/new/kylin/lib/kylin-job-2.2.0.jar kylin.coprocessor.local.jar=/data/soft/new/kylin/lib/kylin-coprocessor-2.2.0.jar
在$KYLIN_HOME/bin目录中运行sample.sh脚本,加载批处理Cube。会在Hive仓库中生成如下表:
kylin_account
kylin_cal_dt
kylin_category_groupings
kylin_country
kylin_sales
这里只是演练MapReduce批处理Cube,对于Spark和Kafka这类流式数据暂不操作。可以在$KYLIN_HOME/bin目录编辑kylin.sh脚本,将Kafka和Spark依赖注释掉。内容如下所示:
# .... function retrieveDependency() { #retrive $hive_dependency and $hbase_dependency source ${dir}/find-hive-dependency.sh source ${dir}/find-hbase-dependency.sh source ${dir}/find-hadoop-conf-dir.sh #source ${dir}/find-kafka-dependency.sh #source ${dir}/find-spark-dependency.sh #retrive $KYLIN_EXTRA_START_OPTS if [ -f "${dir}/setenv.sh" ]; then echo "WARNING: ${dir}/setenv.sh is deprecated and ignored, please remove it and use ${KYLIN_HOME}/conf/setenv.sh instead" source ${dir}/setenv.sh fi # ...
然后,运行check-env.sh脚本检测Kylin系统所需要环境依赖,比如Hadoop、Hive、HBase环境变量配置。在启动Kylin系统之前,需要将HBase的hbase-site.xml文件复制到$KYLIN_HOME/conf目录中,并修改该文件的Zookeeper客户端连接地址。在Kylin系统中,读取hbase-site.xml配置文件中的Zookeeper客户端地址时不需要指定2181端口,比如:之前的客户端地址为“dn1:2181,dn2:2181,dn3:2181”,改为“dn1,dn2,dn3”即可。
最后,执行kylin.sh start启动Kylin系统,系统默认登录用户名和密码为ADMIN/KYLIN。
3.1 预编译Cube
在Model中,选择 kylin_sales_cube批处理Cube进行编译,然后在Monitor模块中查看Cube编译的进度,如下图所示:
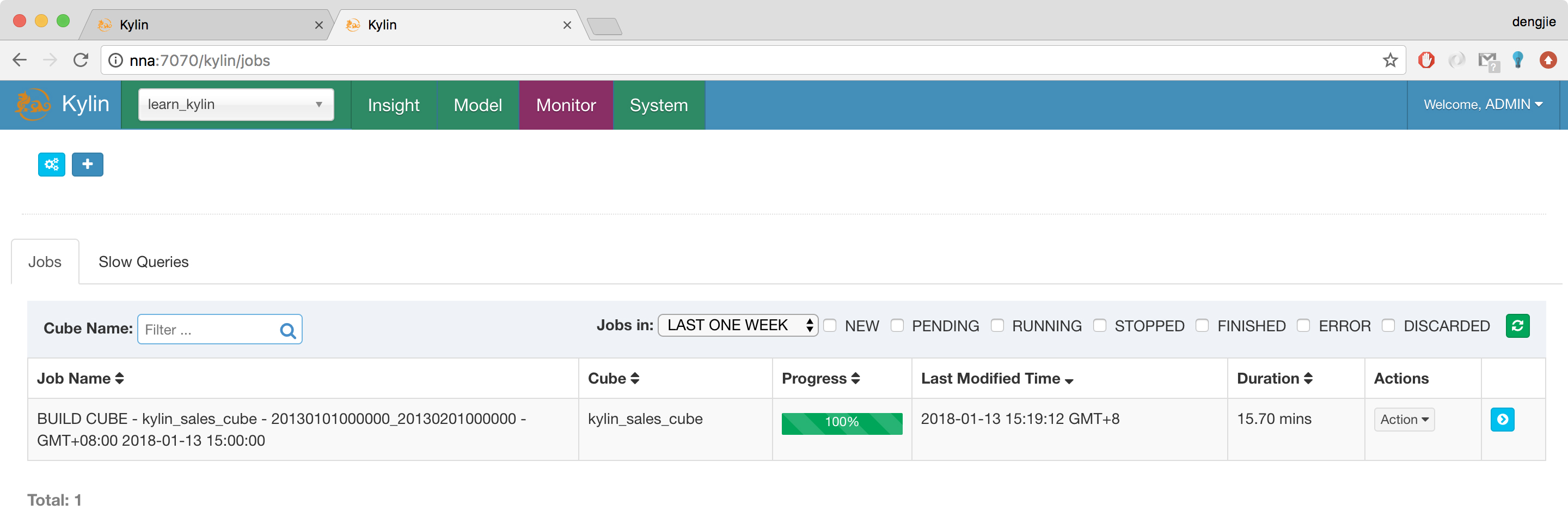
如果在编译Cube的过程中可能会出现连接异常,如下所示:
account.jetbrains.com:10020 failed on connection exception
出现这类问题,是Hadoop的historyserver服务没有启动,执行以下命令启动该进程服务:
mr-jobhistory-daemon.sh start historyserver
在编译成功后,在Model模块中,对应的Cube由Disable状态编译Ready状态,如下图所示:

从上图中可以知道,预编译之后的结果是存储在HBase中的,如表名为:KYLIN_Y8ASHHZ0GY
最后,在Insight模块中的SQL编辑区域,编写SQL代码查询对应的结果,如下图所示:

4.总结
在集成的过程当中需要注意版本的兼容性问题。在新版本的Kylin中引入的新特性Diagnosis,如果在预编译Cube中出现错误,在解决不了的情况下,可以使用Diagnosis功能,将编译产生的结果,通过Diagnosis导出发送给Kylin官方寻求解决方式。
5.结束语
这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉。
以上是关于Kylin与CDH兼容性剖析的主要内容,如果未能解决你的问题,请参考以下文章