023re模块(正则)
Posted Alos
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了023re模块(正则)相关的知识,希望对你有一定的参考价值。
之前我刚学的python知识点,没有题目进行熟悉,后面的知识点会有练习题,并且慢慢补充。
看到很多都是很简单的练习,碰到复杂、需要运用的再补充吧
#字符串中使用到正则表达式
s=\'hello world\' print(s.find(\'ll\')) ret=s.replace(\'ll\',\'aiq\') print(ret) print(s.split(\'o\'))
#字符串里面使用的是完全匹配
##引入正则:模糊匹配
#引入例子
import re ret=re.findall(\'w\\w{2}l\',\'hello world\',) print(ret) # [\'worl\']
##元字符(11个) . 通配符 ^尖角符(头) $(尾) * + { } [ ] \\ ( ) |
#.通配符
ret=re.findall(\'w..l\',\'hello world\',) print(ret) # [\'worl\']
.表示任何东西,但一个点只能表示一位
#^ 尖角符
ret=re.findall(\'^w..l\',\'hello world\',) print(ret) # []
^ 只是在开头匹配,world在开头才能匹配
#$
ret=re.findall(\'w..ld$\',\'hello world\',) print(ret) # [\'world\']
$ 只是在末尾匹配
#*
ret=re.findall(\'xia.*aiq\',\'xiawlgakwjegkawaiqweagkxiadajglagjgaaiqlskajweg\') print(ret) # [\'xiawlgakwjegkawaiqweagkxiadajglagjgaaiq\']
* 表示重复前面多个,包括0个,比如这里是重复多个‘.’
在例如:重复多个a
ret=re.findall(\'ba*\',\'uwefwoiafbaaaaaaaaaa\',) print(ret) # [\'xiawlgakwjegkawaiqweagkxiadajglagjgaaiq\']
#+
ret=re.findall(\'a+b\',\'aaaaabhweogna\') print(ret) # [\'aaaaab\']
+表示一个以上
#?
ret=re.findall(\'a?b\',\'aaaaabhweognabawegb\') print(ret) # [\'ab\',\'ab\',\'b\']
?表示0或者1个
# { }
ret=re.findall(\'a{5}b\',\'aaaaabjaweogldksgajaaab\') print(ret) # [\'aaaaab\'] # {5} 表示固定的有5个 ret=re.findall(\'a{1,5}b\',\'aaaaabjaweogldksgajaaab\') print(ret) # [\'aaaaab\',\'aaab\'] # {1,5} 表示1~5次的都可以
##. ^ $ * + ? { } 推荐使用 * + ?
##后面四个更常用
#[ ] 字符集:取消元字符的特殊功能(\\ ^ -)
ret=re.findall(\'a[c,d]iq\',\'aeawadiqawe\',) print(ret) # [\'adiq\'] ret=re.findall(\'[a-z]\',\'aiq\') print(ret) # [\'a\',\'i\',\'q\'] ret=re.findall(\'[.*]\',\'aiq\') # . * 都没有意义了 print(ret) # [] # 字符集里面加^ ret=re.findall(\'[^t]\',\'wjrttttt\') print(ret) # [\'w\',\'j\',\'r\'] ret=re.findall(\'[^t,j]\',\'wjrttttt\') #这里是出了\'t , j\'的其他字符 print(ret) # [\'w\',\'r\']
# \\ 特殊字符被去除特殊功能,普通字符被加上特殊功能
print(re.findall(\'\\d{11}\',\'aweoigw12354616579 12221845651\')) # [\'12354616579\'] print(re.findall(r\'I\\b\',\'Iloveq.\')) # [\'I\'] \\b表示特殊字符 print(re.search(\'aiq\',\'awekgwaeiaiqawefweaiq\',)) # <_sre.SRE_Matchobject;span=(9,12),match=\'aiq\'>
findall找字符串中全部符合的,返回一个列表
search找到第一个结果,返回一个不知道什么类型的东西。使用.group方法可以返回找到的字符串
没有找到不能调用.group方法
# \\\\ 找\\
ret=re.findall(\'\\\\\\\\\',\'abc\\de\') print(ret) # [\'\\\\\'] ret=re.findall(r\'\\\\\',\'abc\\de\') print(ret) # [\'\\\\\']
\\b在python解释器有特殊意义,加了r过后,python解释器就不会解释这个了
#()分组
print(re.search(\'(as)+\',\'sdjasasasaswefkajasasafw\').group())#asasasas ret=re.search(\'(?P<name>\\w{2})/(?P<age>\\d{2})\',\'xq/32\') # 命名分组 <?P<name> print(ret.group()) #xq/32 print(ret.group(\'name\')) #xq print(ret.group(\'age\')) #32
# | 管道符 代表或
print(re.search(\'(as)|3\',\'as3\').group()) # as ret=re.search(\'(?P<id>\\d{3})/(?P<name>\\w{3})\',\'weeew34ttt456/qqq\') # ?P<id> 这里是自己定义一个名字 print(ret.group()) # 456/qqq print(ret.group(\'id\')) # 456/qqq print(ret.group(\'name\')) # qqq
使用findall方法得到的结果 [(\'xq\', \'32\')]
################################################################
正则表达式的方法
1、findall():匹配的结果返回到了一个列表里面
2、search():返回匹配到的第一个对象,可以调用group方法返回结果
3、match():只在字符开始匹配,和^号效果一样,但是 返回对象
4、split():先按j分,然后在把分开的部分按s分
ret=re.split(\'[j,s]\',\'djksal\') # ****** print(ret) # [\'d\',\'k\',\'al\']
5、sub():代替
ret=re.sub(\'x..ui\',\'aiq\',\'xijuialwewejgaiq\') print(ret) # aiqalwewejgaiq
6、compile():编译了一个规则,通过规则对象
k=re.compile(\'\\.com\') ret=k.findall(\'afaewlj.comawelgkj\') print(ret) # [\'.com\']
7、finditer():得到一个可迭代对象
ret=re.finditer(\'\\d\',\'sweg273932hk2k3jt23jk\') print(next(ret).group())
#看一本书上的贪婪性匹配算法和懒惰性匹配算法
上面都是贪婪的
#懒惰性匹配算法
result=re.findall(\'<.+>\',\'aiq<book><title>python</title><author>jiang<author></book>ai\') print(result) # 贪婪性[\'<book><title>python</title><author>jiang<author></book>\'] result=re.findall(\'<.+?>\',\'aiq<book><title>python</title><author>jiang<author></book>ai\') print(result) # 懒惰性 [\'<book>\', \'<title>\', \'</title>\', \'<author>\', \'<author>\', \'</book>\']
感觉就是后面加了个问号,书上的例子都是这样。没错,就是多了个?
################################################################
练习:
1、查找字符串中的6位数
result=re.findall(\'\\d{6}\',\'hold on 16574 153486 46514 56ef5 sa5fef 486456\') print(result) # [\'153486\',\'486456\']
2、中国电话号码(0751-6228666,021-62232333,区号2-3位,后面号码6-8位)
result=re.findall(\'0\\d{2,3}-\\d{6,8}\',\'电话号码:0750-6225680,姓名:qq\') print(result)
3、题目:写出正则表达式,从一个字符串中提取链接地址。比如
"IT面试题博客中包含很多 <a href=http://hi.baidu.com/mianshiti/blog/category/微软面试题> 微软面试题 </a> "
则需要提取的地址为 " http://hi.baidu.com/mianshiti/blog/category/微软面试题 "


1 import re 2 content="IT面试题博客中包含很多<ahref=http://hi.baidu.com/mianshiti/blog/category/微软面试题>微软面试题</a>" 3 #result=re.search(\'http(s?)://(\\w+(.\\w+)*/(\\w*)?)+\',content).group() 4 #result1=re.findall(\'(http(s?)://(\\w+(.\\w+)*/(\\w*)?)+)\',content) 5 result=re.search(\'http(s?)://(\\w+(.\\w+)*/(\\w*)?)+\',content).group() 6 print(result) 7 # 标准答案 \'<a(?: [^>]*)+href=([^>]*)(?: [^>]*)*>\' # 这个我没有看明白是什么意思 8 #(http(s?)://(\\w+(.\\w+)*/(\\w*)?)+)这样使用findall的是[(\'http://hi.baidu.com/mianshiti/blog/category/微软面试题\',\'\',\'hi.baidu.com/mianshiti/blog/category/微软面试题\',\'/category\',\'微软面试题\')] 9 #应该是找到全部符合的,然后找小的符合的。调用search就是我想要的 10 #如果是http(s?)://(\\w+(.\\w+)*/(\\w*)?)+这样,就不是我想要的,可能()是分组的问题导致的
4、题目:验证电子邮箱地址
1 import re 2 x=input(\'输入邮箱地址:\') 3 result=re.search(\'^(\\w)+(\\.\\w)*(-\\w)*(_\\w)*@\\w+((\\.\\w+)+)$\',x).group() 4 print(result) 5 # 答案的正则是‘^(\\w)+(\\.\\w+)*@(\\w)+((\\.\\w+)+)$\' ,我做的是加上答案后想了一下加的
作业:
计算器
思路,先算最里面括号的内容,里面可能出现加减乘除和幂运算(做成方法运算),然后结果代替原来的,循环。
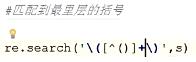
re.search(\'\\([^()]+\\)\',\'((3+6)*3)\') # 取最里面的括号
1-2*((60-30+(-40/5)*(9-2*5/3+7/3*99/4*2998+10*568/14))-(-4*3)/(16-3*2))
难度加深 2*(-15)-(-6)/(-2) 的这类
太多的东西解决不了,后期再补上,很多东西没有学,先学其他,做好总结再说
以上是关于023re模块(正则)的主要内容,如果未能解决你的问题,请参考以下文章