AWK ( 一 )
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AWK ( 一 )相关的知识,希望对你有一定的参考价值。
awk是一门编程语言,它支持条件判断、数组、循环等功能。所以,我们也可以把awk理解成一个脚本语言解释器。
grep 、sed、awk被称为linux中的"三剑客"。
这三个"剑客"各有特长。
grep 适合单纯的查找或匹配文本
sed 适合编辑匹配到的文本
awk 适合格式化文本,对文本进行较复杂格式处理。报告生成器,格式化文本输出。
AWK处理流程
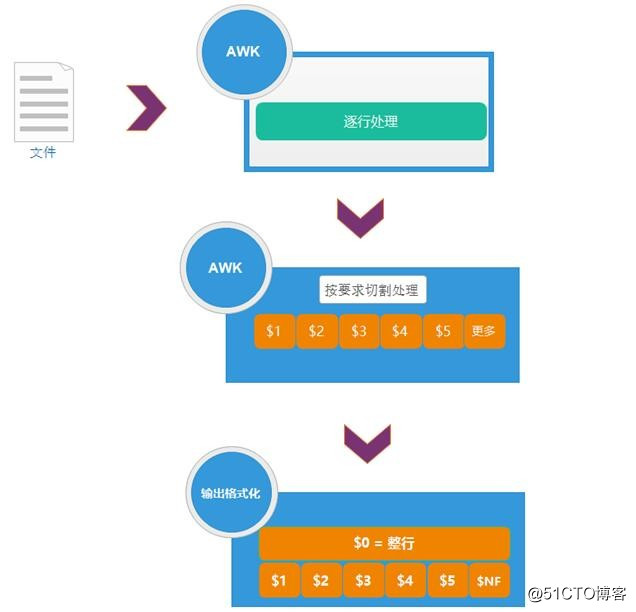
我们现在在linux的所使用的awk其实是gawk,也就是GNU awk,简称为gawk。在系统内使用awk和gawk其实是一样的
#ll /bin/awk
lrwxrwxrwx. 1 root root 4 Dec 13 20:15 /bin/awk -> gawk基本用法:
awk [options] ‘program‘ var=value file…
其中 program 通常是被单引号引中。
awk [options] -f programfile var=value file…
awk [options] ‘BEGIN{ action;… } pattern{ action;… } END{ action;… }‘ file ...awk 程序通常由:BEGIN语句块、program、 END语句块,共3部分组成
program又可以细分成pattern和action
? pattern 决定动作语句何时触发及触发事件
比如说可以使用正则表达式,总之就是读取进来数据会满足指定条件
? action 对满足指定条件数据进行处理,放在{}内指明
常用的2个动作就是打印到屏幕咯 print, printf。如果没有指定action动作,默认的动作就是 print $0记录、域和分割符
记录
文件的每一行称为记录,一般情况下,换行就为一条记录,
#cat file
line1-1:2:[email protected]:b:c:[email protected]:F:G
#awk ‘{print $0}‘ file
line1-1:2:[email protected]:b:c:[email protected]:F:G
这里就是1行记录
如果以@作为记录的分隔符,那么这一行数据里其实就是3行记录
#awk ‘BEGIN{RS="@"}{print $0}‘ awk
line1-1:2:3
a:b:c:d
E:F:G
域
由分隔符分隔的字段,对于每个域标记为记$1,$2..$n称为域标识。$0为所有域,也就是整条记录。不要跟shell中的$0混淆。
也可以把域理解为列,字段
域分隔符变量:FS(field sign)
$0 表示显示整行 ,$NF表示当前记录分割后的最后一个域($0和$NF均为内置变量)
$NF表示最后一个字段,NF表示当前记录被分隔符切开以后,一共有几个字段。
假如一条记录被分成了4列,那么NF的值就是4,$NF的值就是$4, 而$4表示当前记录的第4个字段,也就是最后一列。那么每条记录的倒数第二个字段可以写为$(NF-1)。注意括号。分隔符
输入记录分隔符 RS
默认:换行符
#awk -v RS="@" ‘{print $0}‘ file
a b c d
a b c d
---------------------------------------------
输出记录分隔符 ORS
默认:换行(\n)
#awk -v ORS="行分隔" ‘{print $0}‘ awk
line1-1:2:[email protected]:b:c:[email protected]:F:G行分隔line2-1:2:[email protected]:b:c:[email protected]:F:G行分隔
---------------------------------------------
字段分隔符 FS
默认:单个空格
使用使用2种格式:
#awk -F "@" ‘{print $2,$3}‘ file
a:b:c:d E:F:G
#awk -v FS="@" ‘{print $2,$3}‘ file
a:b:c:d E:F:G
---------------------------------------------
输出字段分隔符 OFS
默认:单个空格
#awk -F ":" -v OFS="===" ‘{print $1$2}‘ awk
line1-12
line2-12
注意那个,逗号
#awk -F ":" -v OFS="===" ‘{print $1,$2}‘ awk
line1-1===2
line2-1===2
awk工作原理
以文件passwd.txt为例:内容如下
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin #awk -F: ‘BEGIN {print "user","passwd","UID","GID"}/^root/{print $1,$2,$3,$4}END{print "file output complete" }‘ passwd.txt
现在通过分步演示说明上一条awk语句的执行过程:
第一步:执行BEGIN{action;… }语句块中的语句
#awk -F: ‘BEGIN {print "user","passwd","UID","GID"}‘ passwd.txt
user passwd UID GID
并没有处理passwd.txt内容,仅仅是打印了字符串,通常是用来当表头第二步:从文件或标准输入(stdin)读取一行,然后执行pattern{action;… }语句块,它逐行扫描文件,
从第一行到最后一行重复这个过程,直到文件全部被读取完毕。
指定以:分隔符
#awk -F: ‘BEGIN {print "user","passwd","UID","GID"}/^root/{print $1,$2,$3,$4}‘ passwd.txt
user passwd UID GID
root x 0 0
将每行记录分割之后,
其中pattern指定条件为以root为行首,所以,只有一条记录是符合条件的
action 的执行操作就是print 第1,2,3,4字段内容
----------------------------------------------------------------------------------
#awk -F: ‘BEGIN {print "user","passwd","UID","GID"}{print $1,$2,$3,$4}‘ passwd.txt
user passwd UID GID
root x 0 0
bin x 1 1
daemon x 2 2
将每行记录分割之后,
其中pattern没有指定,所以,所有的记录都是符合条件的
action 的执行操作就是print 第1,2,3,4字段内容。注意每个字段是属于内置变量,不要用引号。"$1" 这样会被以字符串显示出来。
第三步:当读至输入流末尾时,执行END{action;…}
#awk -F: ‘BEGIN {print "user","passwd","UID","GID"}/^root/{print $1,$2,$3,$4}END{print "file output complete" }‘ passwd.txt
user passwd UID GID
root x 0 0
file output complete
最后只打印了一条信息在行末。总结:
BEGIN语句块在awk开始从输入流中读取行之前被执行,
这是一个可选的语句块,比如变量初始化、打印输出表格的表头等语句通常可以写在BEGIN语句块中
END语句块在awk从输入流中读取完所有的行之后即被执行,比如打印所有行的分析结果这类信息汇总都是在END语句块中完成,
它也是一个可选语句块
pattern语句块中的通用命令是最重要的部分,也是可选的。如果没有提供pattern语句块,则默认执行{ print },即打印每一个读取
到的行,awk读取的每一行都会执行该语句块
print格式
print item1, item2, ...
? 要点:
? (1) 逗号分隔符
? (2) 输出的各item可以字符串,也可以是数值;当前记录的字段
? (3) 字符串,和特数的表示要用双引号。"srt" "\t" "\n"
? (4) 如省略item,相当于print $0 表示显示整行。
? 示例:
#awk -F: ‘{print $0}‘ /etc/passwd 等价于 #awk -F: ‘{print}‘ /etc/passwd
#awk -F: ‘{print $1"\t"$3}‘ /etc/passwd
#tail –3 /etc/fstab |awk ‘{print $2,$4}‘awk变量
内置变量
-v 是声明变量
输入记录分隔符 RS
默认:换行符
#awk -v RS="@" ‘{print $0}‘ awk2
a b c d
a b c d
---------------------------------------------
输出记录分隔符 ORS
默认:换行(\n)
#awk -v ORS="行分隔" ‘{print $0}‘ awk
line1-1:2:[email protected]:b:c:[email protected]:F:G行分隔line2-1:2:[email protected]:b:c:[email protected]:F:G行分隔
---------------------------------------------
字段分隔符 FS
默认:单个空格
使用使用2种格式:
#awk -F "@" ‘{print $2,$3}‘ awk
a:b:c:d E:F:G
a:b:c:d E:F:G
#awk -v FS="@" ‘{print $2,$3}‘ awk
a:b:c:d E:F:G
a:b:c:d E:F:G
---------------------------------------------
输出字段分隔符 OFS
默认:单个空格
#awk -F ":" -v OFS="===" ‘{print $1$2}‘ awk
line1-12
line2-12
注意那个,逗号
#awk -F ":" -v OFS="===" ‘{print $1,$2}‘ awk
line1-1===2
line2-1===2
---------------------------------------------
NF:字段数量
#awk -F: ‘{print NF}‘ /etc/passwd
7
#awk -F: ‘{print $(NF-1)}‘ /etc/passwd
/root
---------------------------------------------
NR:记录号
#awk -F: ‘{print NR}‘ /etc/passwd 相当于打印行号
1
2
---------------------------------------------
FNR:分别统计各文件行数
#awk ‘{print FNR}‘ /etc/passwd /etc/fstab
---------------------------------------------
FILENAME:当前文件名
#awk ‘{print FILENAME}‘ /etc/fstab
---------------------------------------------
ARGC:命令行参数的个数,注意命令本身也算一个
#awk ‘{print ARGC}‘ /etc/fstab /etc/inittab
3
---------------------------------------------
ARGV:数组,保存的是命令行所给定的各参数
注意以下,ARGV[0],指的是命令本身
#awk ‘BEGIN{print ARGV[0]}‘ /etc/passwd /etc/fstab
awk
#awk ‘BEGIN{print ARGV[1]}‘ /etc/passwd /etc/fstab
/etc/passwd
#awk ‘BEGIN{print ARGV[2]}‘ /etc/passwd /etc/fstab
/etc/fstab
自定义变量
用户定义的变量,有两种方法可以自定义变量。
方法一:-v 变量名=变量值 变量名区分字符大小写。注意变量名的命名规则可以参考之前的bash编程
#awk -v 1abc=hunk ‘BEGIN{print 1abc}‘ 错误的变量命名
awk: fatal: `1abc‘ is not a legal variable name
#awk -v _1abc=hunk ‘BEGIN{print _1abc}‘
hunk
方法二:在program中直接定义。
变量定义与动作(action)之间需要用分号";"隔开
#awk ‘BEGIN{name="hunk";blog="http://blog.51cto.com/191226139";print name,blog}‘
hunk http://blog.51cto.com/191226139
引用外部的bash变量
#var="bash-variable"
#awk ‘BEGIN{print var}‘
输出为空
看到了吧,直接引用是不可以的
下面使用-v 定义就能正常引用。所以-v 也是有特定用途的。
#awk -v var2=$var ‘BEGIN{print var2}‘
bash-variable
另外,字段分割符也可以引用bash变量
#awk -F "$var" 使用-F时,外部变量只能引有一次,后续就无法再次引用了
#awk -v FS="$var" ‘BEGIN{print FS}‘总结
1.在awk中,只有在引用$0、$1等内置变量的值的时候才会用到"$",引用其他变量时,不管是内置变量,还是自定义变量,都不使用"$",而是直接使用变量名。
2.先定义变量,再使用。
3.awk 的 FS字段分隔符是支持正则表达式的,记得用双引号。
line1-1:2:[email protected]:b:c:[email protected]:F:G
#awk -F "[-:@]+" ‘{print $1,$2,$3,$4,$5,$6}‘ awk.txt
line1 1 2 3 a b
line2 1 2 3 a b
这里表示的是[ ] 内的字符- 或 :或 @ 可以作为分隔符,外面的+号是正则表达式的1个以上
4.awk 支持从文件读取指令
#cat awk_file
{user="username";uid="UID";print user":"$1,uid":"$3}
#awk -F ":" -f awk_file /etc/passwd
username:root UID:0
username:bin UID:1
利用printf 进行格式化输出
可以参考另一篇博客
printf 命令详解
printf 动作的用法与 printf 命令的用法非常相似,只是有略微的不同而已。
2点不同:
第一点:
在awk中使用printf动作时,指定的"格式"与列($1)之间需要用"逗号"隔开,
而使用printf命令时,指定的格式与传入的文本不需要使用"逗号"隔开
awk printf 动作 printf "FORMAT" ,item1, item2, item3...
普通命令 printf "FORMAT" item1 item2 item3 ...
#printf "%s\n" A B C
A
B
C
#echo "A B C"|awk ‘{printf "%s\n" $1}‘ $1前没有逗号
awk: (FILENAME=- FNR=1) fatal: not enough arguments to satisfy format string
`%s
A‘
^ ran out for this one
#echo "A B C"|awk ‘{printf "%s\n",$1}‘ $1前有逗号
A第二点:
在awk中使用printf动作时,指定的"格式"与列($N)需要一一对应,而使用printf命令时,则不需要
awk printf 动作 printf "FORMAT FORMAT FORMAT " ,item1, item2, item3...
普通命令 printf "FORMAT" item1 item2 item3 ...
#printf "%s\n" A B C
A
B
C
#echo "A B C"|awk ‘{printf "%s\n%s\n%s\n",$1,$2,$3}‘ 格式与列一一对应
A
B
C以上2点需要特别注意。
操作符
算术运算
x+y, x-y, x*y, x/y, x^y, x%y
-x: 转换为负数
#awk ‘BEGIN {printf "%d\n", -(3-1)}‘
-2
+x: 转换为数值
#awk ‘BEGIN {print 3+5}‘
8
#awk ‘BEGIN {printf "%f\n",1/3}‘ 比bash要强,支持浮点数
0.333333字符串操作符
没有符号的操作符
#awk ‘BEGIN{print "abc-edf"}‘赋值操作符
=, +=, -=, *=, /=, %=, ^= ++, --
#awk ‘BEGIN{i=10;m+=i;print i}‘
10
#awk ‘BEGIN{i=10;++i;print i}‘
11
#awk ‘BEGIN{unset i;i=10;++i;print i}‘
11
比较操作符
| 操作符 | 含义 | 示例 |
|---|---|---|
| < | 小于 | a < b |
| <= | 小于等于 | a <= b |
| == | 等于 | a == b |
| != | 不等于 | a != b |
| >= | 大于等于 | a >= b |
| > | 大于 | a > b |
| ~ | 与正则匹配(包含的关系) | a ~ b |
| !~ | 与正则不匹配 | a !~ b |
#awk -F: ‘$3 < 10 {printf "%3d %-8s %6d\n", NR,$1,$3}‘ /etc/passwd
1 root 0
2 bin 1
3 daemon 2
4 adm 3
5 lp 4
6 sync 5
7 shutdown 6
8 halt 7
9 mail 8
#awk -F: ‘$1 == "hunk" {print NR,$1,$3}‘ /etc/passwd
32 hunk 500使用正则表达式时的注意要点
在使用如~这种匹配关系时,必须加双引号或者/ / 。与搜索匹配正则位置的语法不一样。
匹配正则,注意是包含的关系。
#awk ‘$0 ~ "root" {print NR,$1,$3}‘ /etc/passwd
1 root:x:0:0:root:/root:/bin/bash
11 operator:x:11:0:operator:/root:/sbin/nologin
不匹配正则
#awk ‘$0 !~ "/bin/bash" {print NR,$1,$3}‘ /etc/passwd
2 bin:x:1:1:bin:/bin:/sbin/nologin
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
4 adm:x:3:4:adm:/var/adm:/sbin/nologin
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
6 sync:x:5:0:sync:/sbin:/bin/sync
7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdownawk命令在使用扩展正则表达式,需要将正则表达式放入了"/ /"中.如果正则中包含"/",则需要进行转义.比如说:
#df | awk ‘/\/dev\/sd/{print $0}‘
/dev/sda3 8652808 2437492 5769108 30% /
/dev/sda1 487652 35608 426444 8% /boot当使用 {a,b},{a,} 这种次数匹配的正则表达式时,需要配合--posix选项或者--re-interval选项
#awk ‘/(abc){2,2}/{print $0}‘ demo.txt
输出为空
#awk --re-interval ‘/(abc){2,2}/{print $0}‘ demo.txt
abcabckkal
#awk --posix ‘/(abc){2,2}/{print $0}‘ demo.txt
abcabckkal
#awk --re-interval ‘/(abc){2,}/{print $0}‘ demo.txt
abcabckkal
这种写法貌似不支持
#awk --re-interval ‘/(abc){,2}/{print $0}‘ demo.txt
输出为空
awk 的行范围模式
语法:
awk / 正则表达式1 /,/ 正则表达式2 /{动作}
#awk ‘/^lp/,/^games/{print NR,$0}‘ /etc/passwd
匹配以lp为行首到以games行首之间的范围
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
6 sync:x:5:0:sync:/sbin:/bin/sync
7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
8 halt:x:7:0:halt:/sbin:/sbin/halt
9 mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
10 uucp:x:10:14:uucp:/var/spool/uucp:/sbin/nologin
11 operator:x:11:0:operator:/root:/sbin/nologin
12 games:x:12:100:games:/usr/games:/sbin/nologin逻辑操作符
&& (与),|| (或),! (非)
#seq 1 10 | awk ‘$1 >= 3 && $1 <= 6 {print $0}‘ && (与)
3
4
5
6
#seq 1 10 | awk ‘$1 == 3 || $1 == 6 {print $0}‘ || (或)
3
6
#seq 1 10 | awk ‘!($1 < 5) {print $0}‘ ! (非)
5
6
7
8
9
10
以上是关于AWK ( 一 )的主要内容,如果未能解决你的问题,请参考以下文章