* HBase框架基础(一)
官方网址:http://hbase.apache.org/
* HBase是什么妖怪?
要解释HBase,我们就先说一说经常接触到的RDBMS,即关系型数据库:
** mysql:
*** 有开源社区版本的,有企业收费版本的
*** 遵循主从架构
*** 端口号:3306
** sqlserver:
*** 微软公司开发的产品,主要用于windows平台下的项目
*** 端口号:1433
** oracle:
*** 超强的集群性能
*** 端口号:1521
再来说一说HBase这个非关系型数据库:
** HBase:
*** 灵感来自于Google的BigTable论文
*** 一般于Hadoop结合使用,是Hadoop项目的子项目
*** 基于key-value的形式存储数据
*** 高性能,高可靠,面向列,可伸缩的分布式存储系统
*** 没有sql语句,一般用API操作
*** 适用于单表数据量超大,且不能分表
*** 分布式架构,支持服务器在线添加和移除
接着说一说HBase和Hive的关系和区别:
** Hive:
*** 是数据仓库,不是数据库
*** 一般用于分析,并不会直接接入到在线业务
*** 实际上是将hql语句转化为mapreduce任务运行在yarn平台上
** HBase:
*** 面向列的非关系型数据库,分布式架构
*** 用于存储数据和检索数据,一般会直接接入在线业务
*** 不依赖于yarn和mapreduce
最后说一说RDBMS和HBase的区别:
*** RDBMS使用sql语句,HBase使用API
*** RDBMS基于行存储,HBase基于列存储且支持更好的压缩
*** RDBMS适用于存储结构化数据,HBase适用于存储结构化和非结构化数据
*** RDBMS支持事务处理,HBase不支持事务处理
*** RDBMS支持多表Join,HBase不支持多表Join
*** RDMBS更新表数据会自动更新索引文件,HBase需要手动建立索引,手动更新
*** RDMBS适用于业务逻辑复杂的存储环境,HBase不适合。
*** RDMBS不适合存储超大数据量的单表,HBase适合。
读完上边的内容,大概应该知道HBase是个什么妖怪了吧。
* HBase基本进程
HMaster
HMaster节点有如下功能:
** 为HRegionServer分配HRegion
** 负责HRegionServer的负载均衡
** 发现失效的HRegionServer并重新分配其上的HRegion
** HDFS上的垃圾文件回收
** 处理Schema更新请求
HRegionServer
** 维护HMaster分配给他的HRegion,处理HRegion的IO请求
** 负责切分正在运行过程中变的过大的HRegion
* HBase基本原理
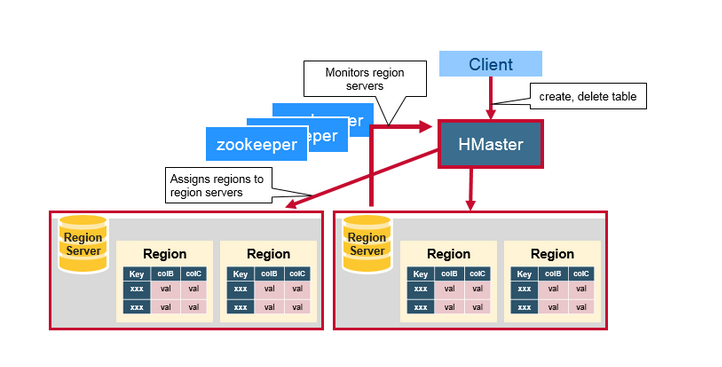
请看图:

Client:
包含访问HBase的接口,并维护cache来加快对HBase的访问。说白了,就是用来访问HBase的客户端。
HMaster:
这个东西是HBase的主节点,用来协调Client端应用程序和HRegionServer的关系,管理分配HRegion给HRegionserver服务器。
HRegionServer:
Hbase的从节点,管理当前自己这台服务器上面的HRegion,HRegion是Hbase表的基础单元组建,存储了分布式的表。HRegionserver负责切分在运行过程中变得过大的HRegion。
HRegion:
一个Table可以有多个HRegion,HBase使用rowKey将表水平切割成多个HRegion,每个HRegion都纪录了它的StartKey和EndKey(第一个HRegion的StartKey为空,最后一个HRegion的EndKey为空),由于RowKey是排序的,因而Client可以通过HMaster快速的定位每个RowKey在哪个HRegion中。HRegion由HMaster分配到相应的HRegionServer中,然后由HRegionServer负责HRegion的启动和管理,和Client的通信,负责数据的读(使用HDFS)。每个HRegionServer可以同时管理1000个左右的HRegion,出处请参看论文:BigTable(5 Implementation节):Each tablet server manages a set of tablets(typically we have somewhere between ten to a thousand tablets per tablet server))。
MemStore:
它是一个写缓存,数据先WAL[write ahead log](也就是HLog它是一个二进制文件,所有写操作都会先保证将数据写入这个Log文件后,才会真正更新MemStore,最后写入HFile中),在写入MemStore后,由MemStore根据一定的算法将数据Flush到底层HDFS文件中(HFile),一般而言,对于每个HRegion中的每个Column Family来说,有一个自己的MemStore。
StoreFile:
1个HStore,由一个MemStore和0~N个StoreFile组成。
HFile:
用于存储HBase的数据(Cell/KeyValue),在HFile中的数据是按RowKey、Column Family、Column排序,对于相同的数据单元,排序则按照时间戳(Timestamp)倒叙排列。
Zookeeper:
HBase内置有zookeeper,但一般我们会有其他的Zookeeper集群来监管master和regionserver,Zookeeper通过选举,保证任何时候,集群中只有一个活跃的HMaster,HMaster与HRegionServer 启动时会向ZooKeeper注册,存储所有HRegion的寻址入口,实时监控HRegionserver的上线和下线信息。并实时通知给HMaster,存储HBase的schema和table元数据,默认情况下,HBase 管理ZooKeeper 实例,Zookeeper的引入使得HMaster不再是单点故障。一般情况下会启动两个HMaster,非Active的HMaster会定期的和Active HMaster通信以获取其最新状态,从而保证它是实时更新的,因而如果启动了多个HMaster反而增加了Active HMaster的负担。如图:
* HBase的部署
** 整体规划图

** 安装Hadoop集群并启动之
$ tar -zxf hbase-0.98.6-hadoop2-bin.tar.gz -C /opt/modules/
** 启动Zookeeper
$ bin/zkServer.sh start
** 安装HBase
HBase下载传送门:链接:http://pan.baidu.com/s/1sk8DpbJ 密码:qrzj
** 修改配置文件
hbase-env.sh:
export JAVA_HOME=/opt/modules/jdk1.8.0_121
export HBASE_MANAGES_ZK=false
(注:该属性让HBase使用一个已有的不被HBase托管的Zookeepr集群)
hbase-site.xml:配置后如图

尖叫提示:注意此处的hbase.master属性只配置了60000端口,没有配置主机名,这是为了在多台机器节点上启动HMaster,即,为了HMaster开启高可用。
regionservers:
在我的集群环境下,将localhost改为
z01
z02
z03
创建backup-masters:
在我的集群环境下,声明备份的HMaster节点,我此处添加:
z02
尖叫提示:如果使用Notepad++工具编辑该文件,可能会造成文件格式不对而无法解析到正确的主机名,建议使用vi编辑器。
** 替换HBase的lib目录下的关于Hadoop和Zookeeper的jar包,以解决版本兼容问题
删除:
$ rm -rf lib/hadoop-*
$ rm -rf lib/zookeeper-3.4.6.jar
拷贝:
已整理好的jar传送门:链接:http://pan.baidu.com/s/1pLHf9H5 密码:ahpv
解压之后将文件夹里的jar拷贝到Hbase的lib目录下即可。替换后如图:

最后将整理好的在z01机器中的hbase安装包拷贝给z02,以及z03机器。
** 启动服务
首先做一个hadoop配置文件的软连接到hbase:
$ ln -s /opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/etc/hadoop/core-site.xml /opt/modules/cdh/hbase-0.98.6-cdh5.3.6/conf/core-site.xml
$ ln -s /opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/etc/hadoop/hdfs-site.xml /opt/modules/cdh/hbase-0.98.6-cdh5.3.6/conf/hdfs-site.xml
然后启动:
$ bin/hbase-daemon.sh start master
$ bin/hbase-daemon.sh start regionserver
或者软连接做好后直接:
$ bin/start-hbase.sh,然后可以通过浏览器访问到该Hbase:
http://z01:60010/,如图:

** HMaster HA
如果配置都没有问题,也启动成功了,我们可以接着在第二台机器上启动HMaster来成功配置高可用:
第二台机器:bin/hbase-daemon.sh start master,启动后,访问第二台机器地址的60010端口,即可发现,它会告知你active的HBase是哪一台,如图所示:

当然了,通过查看z02中的有关master日志也可以发现z02中的HMaster为standby,如下图所示:

最后测试:手动停掉活跃的HMaster,看看是否能够故障自动转移:
$ bin/hbase-daemon.sh stop master
* HBase基础概念
** HBase数据存储目录
*** /hbase/data/default
存储默认命令空间表文件,创建表的时候如果不指定命令空间(库),默认创建在default下面
*** /hbase/data/hbase
存储HBase元数据的表文件,HDFS中如图:

** 数据存储
HBase中存取数据直接使用字节数组,没有其他数据类型
** HBase存储结构
*** rowkey:行键
用来唯一标识每行数据,类似RDBMS中的唯一主键
*** Column Family(CF):列族
列族,拥有一个名称(string),包含一个或者多个相关列
*** Column:列
字段名称,或列名
*** Cell:单元格
最基本的存储单元,用于列的实际值的存储。
*** Timestamp:时间戳
数据插入到表中的时间
*** 版本
HBase中每个列的值可以有多个版本(副本),默认情况下,有3个版本,只显示最新的版本。
*** 存储形式:键值对
rowKey + Column Family + Timestamp:value
* HBase表的物理模型
** 表会根据rowKey被划分成多个region,默认情况下,刚开始每张表只有一个region
** 同一张表通常会基于rowKey被划分成多个region
** 同一张表的多个region被master分配到多台regionserver管理
** 同一台regionserver服务器可以管理不同的表的region
** 当某台regionserver服务器宕机以后,master会把这台服务器上面管理的region重新分配给其他的regionserver服务器
* HBase常用操作
接下来我们进行一些HBase的操作测试,测试前请确保你的节点中启动了对应的HMaster进程和HRegionServer
** 创建表测试
首先进入到HBase操作命令行:
$ bin/hbase shell,如下图:

接下来可以使用help命令来查看一些帮助提示:
hbase(main):001:0> help,如图:

使用list命令,可以查看当前数据库中有哪些数据表
hbase(main):002:0> list,我们现在没有什么表,如图:

好,那么下面我们来创建一个表:
这个表用来描述学生的一些基本信息吧:
hbase(main):003:0> create ‘student‘,‘info‘,执行后如图:

解释:
‘student‘:表名
‘info‘:列族名,就是说这个列族可能包含多个列,比如Info列族中可能包含name,sex等列,画个图不够严谨的解释下:

接下来往表里放置一些数据:
我先语言表述一下第一行执行的含义,后边以此类推:
向student这张表中插入数据,rowKey为1001,列族:列,为info:name,值value为Thomas
hbase(main):007:0> put ‘student‘,‘1001‘,‘info:name‘,‘Thomas‘
hbase(main):008:0> put ‘student‘,‘1001‘,‘info:sex‘,‘male‘
hbase(main):009:0> put ‘student‘,‘1001‘,‘info:age‘,‘18‘
OK,插入成功后,使用scan来看一下这张表内容
hbase(main):010:0> scan ‘student‘,如图:

接下来我们来看一些其他的命令
** 查看表结构
hbase(main):014:0> describe ‘student‘,如图:

** 更新数据/更新指定字段数据
hbase(main):018:0> put ‘student‘,‘1001‘,‘info:name‘,‘Nick‘
hbase(main):019:0> put ‘student‘,‘1001‘,‘info:age‘,‘100‘
完成后scan下如图:

** get查看数据
查看rowKey为1001的数据
hbase(main):021:0> get ‘student‘,‘1001‘,如图:

查看rowKey为1001,且列名为name的数据
get ‘student‘,‘1001‘,‘info:name‘,如图:

** scan查看数据
查看ROWKEY从1001到1007的数据,注意,规则为“前包含后不包含”,即下面的查询是不包含1007那一个rowKey的数据的。
hbase(main):023:0> scan ‘student‘,{STARTROW => ‘1001‘,STOPROW => ‘1007‘},如图:

** 删除数据
我们把1001这一rowKey的所有数据删除掉,使用命令:
deleteall ‘student‘,‘1001‘
如果只想删除某一个rowKey中的某一个列的数据,使用命令:
delete ‘student‘,‘1001‘,‘info:sex‘,然后scan一下如图:

** 清空数据表
hbase(main):030:0> truncate ‘student‘,如图:

** 删除表
首先需要先让该表为disable状态,使用命令:
hbase(main):033:0> disable ‘student‘
然后才能drop这个表,使用命令:
hbase(main):040:0> drop ‘student‘
尖叫提示:如果直接drop表,会报错:Drop the named table. Table must first be disabled,如图:

** 统计一张表有多少行数据
为了展示一张表有多少行数据,我先重新创建student表,并重新put数据,然后使用命令:
hbase(main):046:0> count ‘student‘

* 总结
这一节我们了解了Hbase的存储结构,以及相关特性,并与Hive以及RDBMS进行了一些对比说明,最后写了一点小练习,希望各位可以动手操作一下Hbase,在此之前确保你的集群正常运行。
个人微博:http://weibo.com/seal13
QQ大数据技术交流群(广告勿入):476966007
作者:Z尽际
链接:https://www.jianshu.com/p/44e0327798ad
來源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。