图像语义分割,简单而言就是给定一张图片,对图片上的每一个像素点分类。

图像语义分割,从FCN把深度学习引入这个任务,一个通用的框架事:前端使用FCN全卷积网络输出粗糙的label map,后端使用CRF条件随机场/MRF马尔科夫随机场等优化前端的输出,最后得到一个精细的分割图。
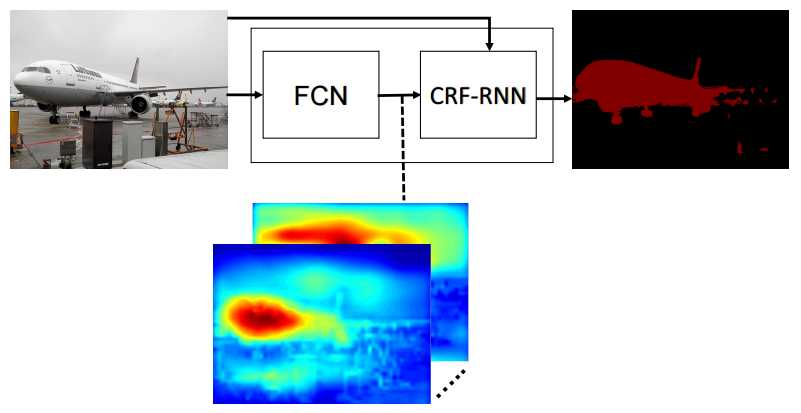
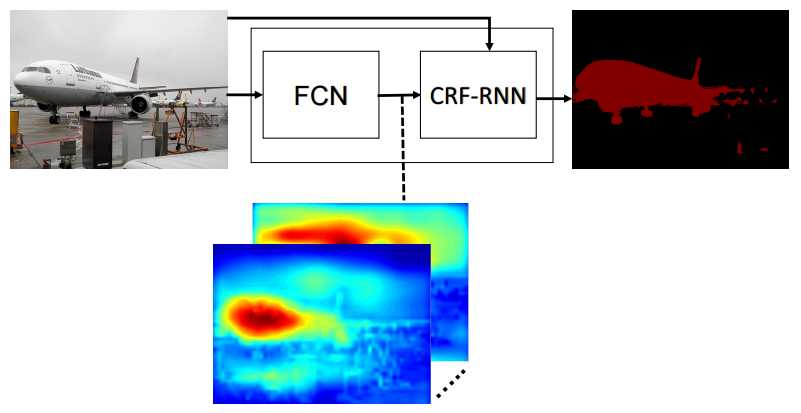
前端
为什么需要FCN?
分类网络通常会在最后连接几层全连接层,它会将原来二维的矩阵(图片)压缩成一维的,从而丢失了空间信息,最后训练输出一个标量,这就是我们的分类标签。
而图像语义分割的输出需要是个分割图,且不论尺寸大小,但是至少是二维的。所以,流行的做法是丢弃全连接层,换上全卷积层,而这就是全卷积网络了。具体定义请参看论文:《Fully Convolutional Networks for Semantic Segmentation》
FCN结构
在FCN论文中,作者的FCN主要使用了三种技术:
卷积(Convolutional)、上采样(Upsample)、跳层连接(Skip Layer)
卷积化即是将普通的分类网络,比如VGG16,ResNet50/101等网络丢弃全连接层,换上对应的卷积层即可。
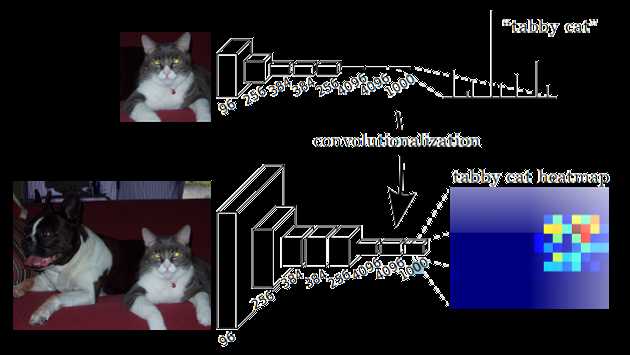
上采样即是反卷积(Deconvolution)。当然关于这个名字不同框架不同,Caffe和Kera里叫Deconvolution,而tensorflow里叫conv_transpose,在《信号与系统》这门课上,我们学过反卷积有定义,不是这里的上采样。所以叫conv_transpose更为合适。
众所周知,池化会缩小图片的尺寸,比如VGG16 五次池化后图片被缩小了32倍。为了得到和原图等大的分割图,我们需要上采样/反卷积。反卷积和卷积类似,都是相乘相加的运算。只不过后者是多对一,前者是一对多。而反卷积的前向和后向传播,只用颠倒卷积的前后向传播即可。所以无论优化还是后向传播算法都是没有问题。上池化的实现主要在于池化时记住输出值的位置,在上池化时再将这个值填回原来的位置,其他位置填0。图解如下:
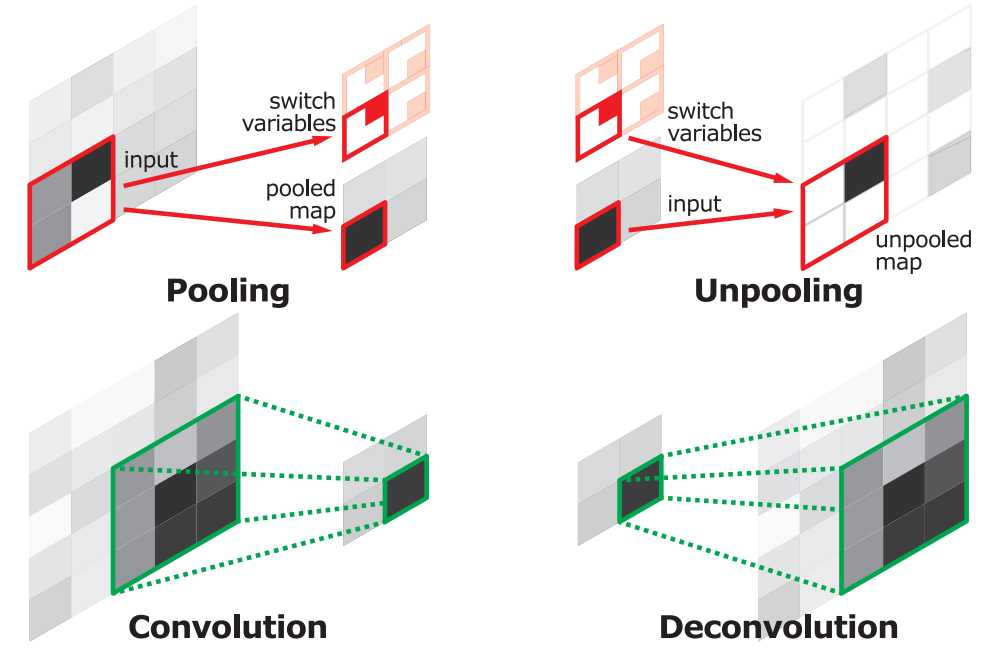
虽然文中说是可学习的反卷积,但是作者实际代码并没有让它学习,可能正是因为这个一对多的逻辑关系。代码如下:
1 layer { 2 name: "upscore" 3 type: "Deconvolution" 4 bottom: "score_fr" 5 top: "upscore" 6 param { 7 lr_mult: 0 8 } 9 convolution_param { 10 num_output: 21 11 bias_term: false 12 kernel_size: 64 13 stride: 32 14 } 15 }
可以看到lr_mult被设置为0。
跳层连接的作用就在于优化结果,因为如果将全卷积之后的结果直接上采样,得到的结果是很粗糙的,所以作者将不同池化层的结果进行上采样之后来优化输出。具体结构如下:
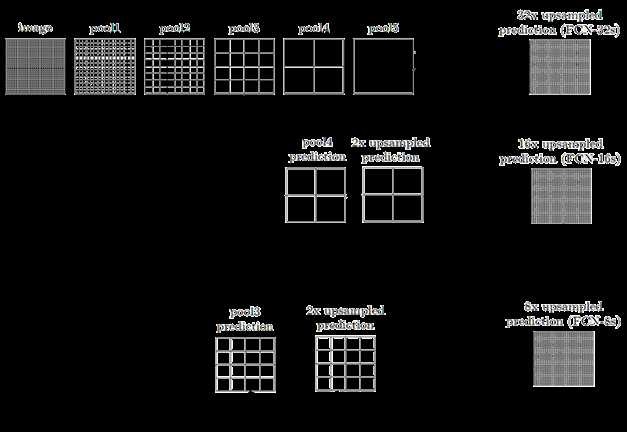
不同上采样得到的结果对比如下:

当然,你也可以将pool1, pool2的结果输出,再上采样输出。不过,作者说了这样得到的结果提升并不大。FCN是深度学习应用于图像语义分割的开山之作,所以得了CVPR2015的最佳论文。但是,还是有一些处理比较粗糙的地方,具体和后面对比就知道了。
FCN-alike
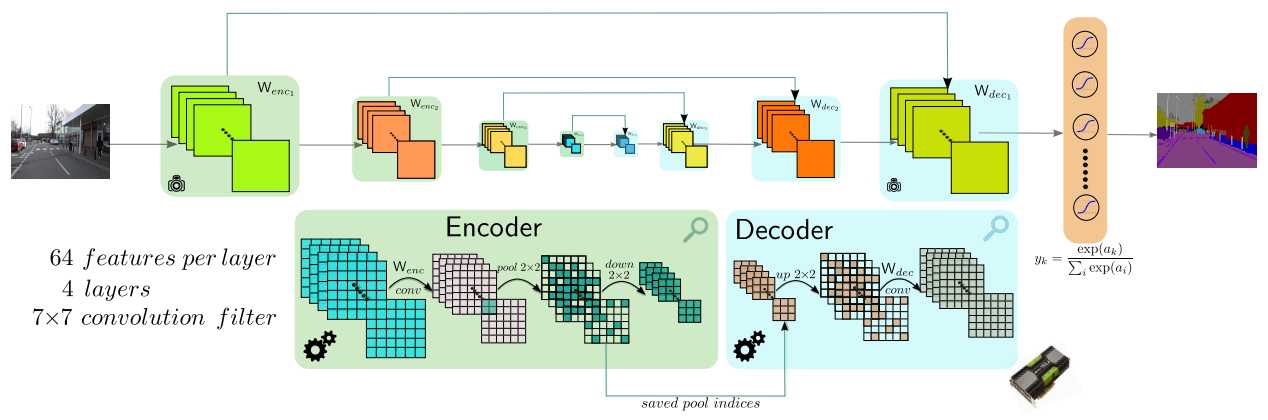
《SegNet: A Deep Convolutional Encoder-Decoder Architecture for Robust Semantic Pixel-Wise Labelling》则是一种结构上更为优雅的网络,SegNet使用一种概率自编码模型,这是一种无监督特征生成网络。当然,他们的label还是需要监督的。
DeepLab
DeepLab是Google提出的一个model,在VOC上的排名要比CRF as RNN的效果好。Deeplab仍然采用了FCN来得到score map,并且也是在VGG网络上进行fine-tuning。但是在得到score map的处理方式上,要比原FCN处理的优雅很多。
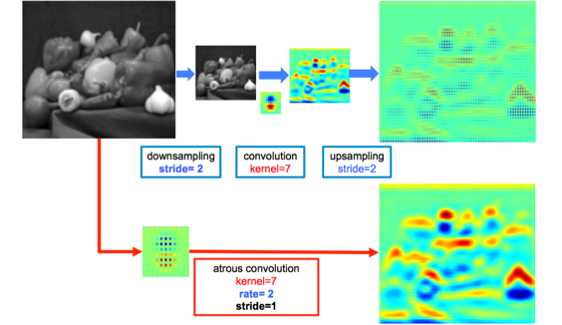
还记得FCN中是怎么得到一个更加dense的score map的吗? 是一张500x500的输入图像,直接在第一个卷积层上conv1_1加了一个100的padding。最终在fc7层勉强得到一个16x16的score map。虽然处理上稍显粗糙,但是毕竟人家是第一次将图像分割在CNN上变成end-to-end,并且在当时performance是state-of-the-art。
而怎样才能保证输出的尺寸不会太小而又不必加100 padding这样“粗糙的”做法呢?可能有人会说减少池化层不就行了,这样理论上是可以的,但是这样直接就改变了原先可用的结构了,而且最重要的一点是不能用以前的结构参数进行fine-tune了。
所以,Deeplab这里使用了一个非常优雅的做法:将VGG网络的pool4和pool5层的stride由原来的2改为了1,再加上 1 padding。就是这样一个改动,使得vgg网络总的stride由原来的32变成8,进而使得在输入图像为514x514时,fc7能得到67x67的score map, 要比FCN确实要dense很多很多。
但是这种改变网络结果的做法也带来了一个问题: stride改变以后,如果想继续利用vgg model进行fine tuning,会导致后面感受野发生变化。这个问题在下图(a) (b)体现出来了,注意花括号就是感受野的大小:
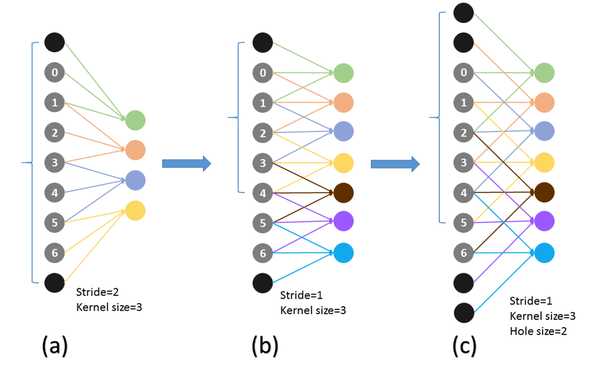
感受野就是输出feature map某个节点的响应对应的输入图像的区域。比如我们第一层是一个3*3的卷积核,那么我们经过这个卷积核得到的feature map中的每个节点都源自这个3*3的卷积核与原图像中3*3的区域做卷积,那么我们就称这个feature map的节点感受野大小为3*3。
具体计算公式为:
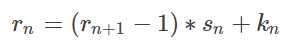
其中rn表示第n层layer的输入的某个区域,sn表示第n层layer的步长,kn表示kernel/pooling size
Deeplab提出了一种新的卷积,带孔的卷积:Atrous Convolution。来解决两个看似有点矛盾的问题:
既想利用已经训练好的模型进行fine-tuning,又想改变网络结构得到更加dense的score map。
如下图(a) (b)所示,在以往的卷积或者pooling中,一个filter中相邻的权重作用在feature map上的位置是连续的。
为了保证感受野不发生变化,某一层的stride由2变为1以后,后面的层需要采用hole算法,具体来讲就是将连续的连接关系根据hole size大小变成skip连接。
上图(C)中使用hole为2的Atrous Convolution则感受野依然为7。(C)中的padding为2,如果再增加padding大小,是不是又变”粗糙”了?当然不会,因为是Atrous Convolution,连接是skip的,所以2个padding不会同时和一个filter相连。
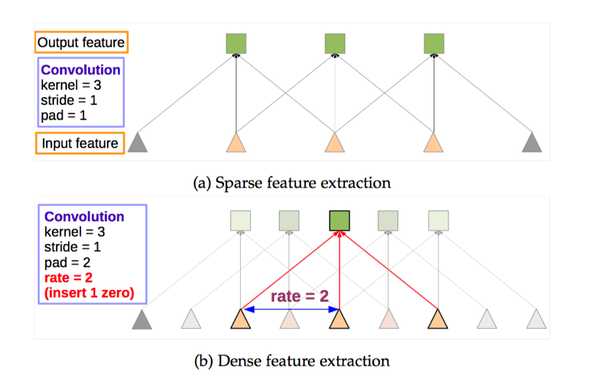
所以,Atrous Convolution能够保证在这样的池化后感受野不变,从而可以fine tune,同时也能保证输出的结果更加精细。即:
后端
DeepLab后面接了一个全连接条件随机场(Fully-Connected Conditional Random Fields)对分割边界进行refine。
DeepLab里只是变成了refine label map。CRF经常用于 pixel-wise的label 预测。把像素的label作为随机变量,像素与像素间的关系作为边,即构成了一个条件随机场且能够获得全局观测时,CRF便可以对这些label进行建模。全局观测通常就是输入图像。
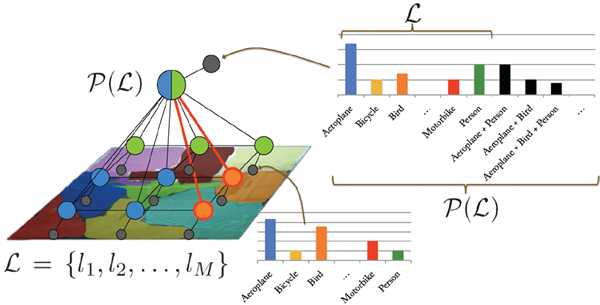
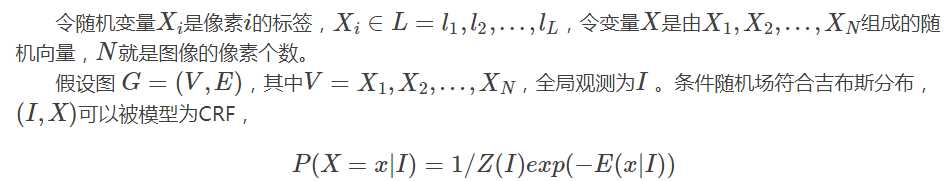
在全连接的CRF模型中,标签x 的能量可以表示为:


精细化的结果如下:
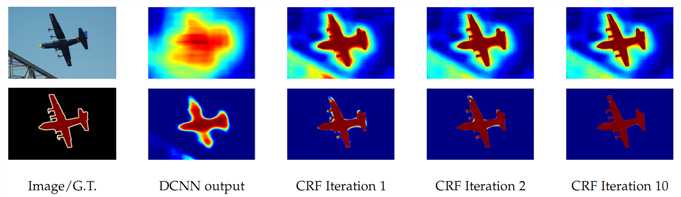
CRF-alike
CRFasRNN
在深度学习中,我们都追求end-to-end的系统,所以Conditional Random Fields as Recurrent Neural Networks 这篇文章的套路更深了……把Mean Field算法嵌入在网络层中。自己写了caffe一层,用类似于Conv的操作模拟Mean Field的四步,具体实现细节可以参照论文中所给的代码。
马尔科夫随机场(MRF)
在Deep Parsing Network中使用的是MRF,它的公式具体的定义和CRF类似,只不过作者对二元势函数进行了修改:
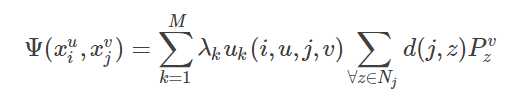
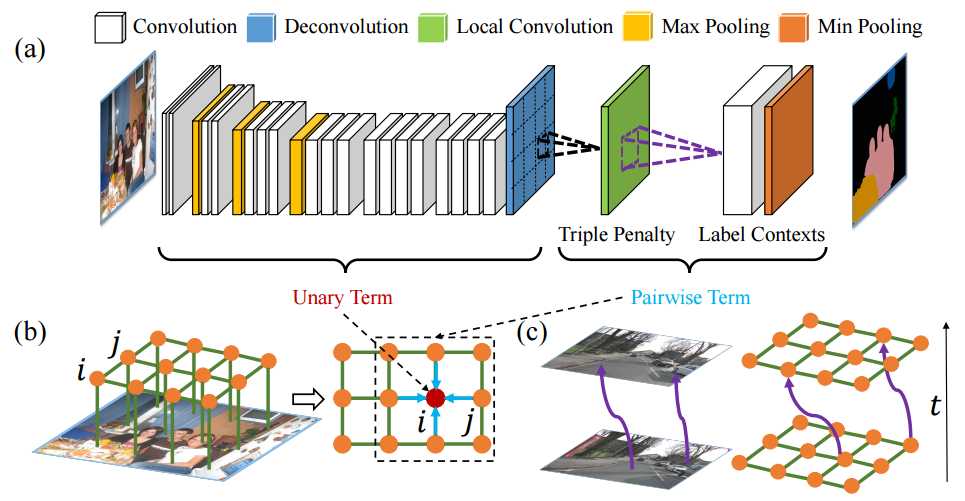
这个结构的优点在于:
- 将Mean fied 构造成CNN
- 联合训练并且可以one-pass inference,而不用迭代。
总结
深度学习+概率图模型(PGM)是一种趋势。深度学习可以更好的提取特征,而PGM能够从数学理论很好的解释事物本质间的联系。概率图模型的网络化也是一种趋势,我们目标是end-to-end的学习系统。
引用
[1]Fully Convolutional Networks for Semantic Segmentation
[2]Learning Deconvolution Network for Semantic Segmentation
[3]DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs
[4]Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs
[5]Conditional Random Fields as Recurrent Neural Networks
[6]SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
原文地址: http://blog.csdn.net/junparadox/article/details/52610744