正则表达式
Posted 带带大师兄丶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了正则表达式相关的知识,希望对你有一定的参考价值。
字符组:
正则 |
待匹配字符 |
匹配 |
说明 |
[0123456789] |
8 |
True |
在一个字符组里枚举合法的所有字符,字符组里的任意一个字符 |
[0123456789] |
a |
False |
由于字符组中没有"a"字符,所以不能匹配 |
[0-9] |
7 |
True |
也可以用-表示范围,[0-9]就和[0123456789]是一个意思 |
[a-z] |
s |
True |
同样的如果要匹配所有的小写字母,直接用[a-z]就可以表示 |
[A-Z] |
B |
True |
[A-Z]就表示所有的大写字母 |
[0-9a-fA-F] |
e |
True |
可以匹配数字,大小写形式的a~f,用来验证十六进制字符 |
字符:
元字符 |
匹配内容 |
| . | 匹配除换行符以外的任意字符 |
| \\w | 匹配字母或数字或下划线 |
| \\s | 匹配任意的空白符 |
| \\d | 匹配数字 |
| \\n | 匹配一个换行符 |
| \\t | 匹配一个制表符 |
| \\b | 匹配一个单词的结尾 |
| ^ | 匹配字符串的开始 |
| $ | 匹配字符串的结尾 |
| \\W |
匹配非字母或数字或下划线 |
| \\D |
匹配非数字 |
| \\S |
匹配非空白符 |
| a|b |
匹配字符a或字符b |
| () |
匹配括号内的表达式,也表示一个组 |
| [...] |
匹配字符组中的字符 |
| [^...] |
匹配除了字符组中字符的所有字符 |
量词:
量词 |
用法说明 |
| * | 重复零次或更多次 |
| + | 重复一次或更多次 |
| ? | 重复零次或一次 |
| {n} | 重复n次 |
| {n,} | 重复n次或更多次 |
| {n,m} | 重复n到m次 |
.^$:
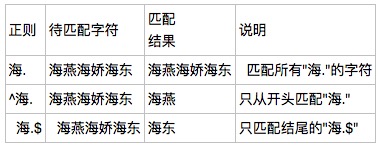
*+?{}:

字符集[] [^]:
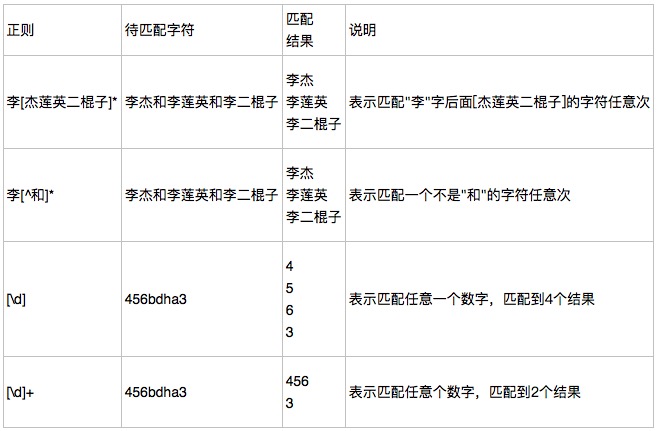
分组()与 或 | [^]:
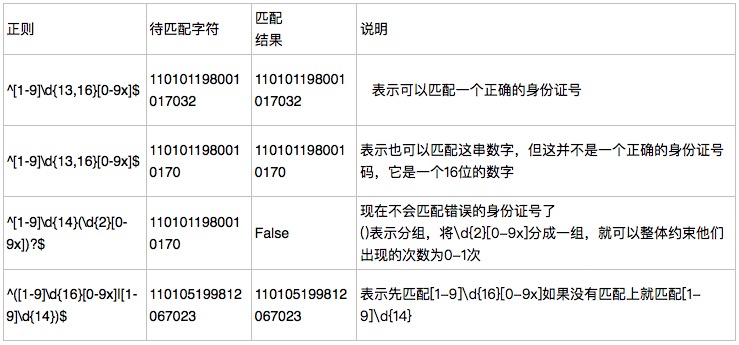
身份证号码是一个长度为15或18个字符的字符串,如果是15位则全部有数字组成,首位不能为0;如果是18位,则前17位全部是数字,末位可能是数字或x,下面我们尝试用正则来表示:
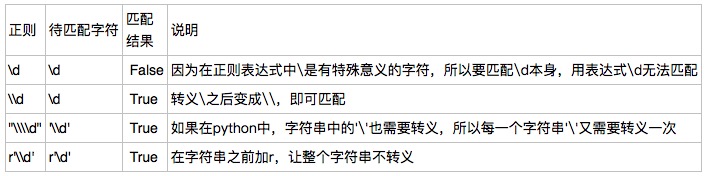
转义符\\:
在正则表达式中,有很多有特殊意义的是元字符,比如\\d和\\s等,如果要在正则中匹配正常的"\\d"而不是"数字"就需要对"\\"进行转义,变成\'\\\\\'。
在python中,无论是正则表达式,还是待匹配的内容,都是以字符串的形式出现的,在字符串中\\也有特殊的含义,本身还需要转义。所以如果匹配一次"\\d",字符串中要写成\'\\\\d\',那么正则里就要写成"\\\\\\\\d",这样就太麻烦了。这个时候我们就用到了r\'\\d\'这个概念,此时的正则是r\'\\\\d\'就可以了。
贪婪匹配:
贪婪匹配:在满足匹配时,匹配尽可能长的字符串,默认情况下,采用贪婪匹配
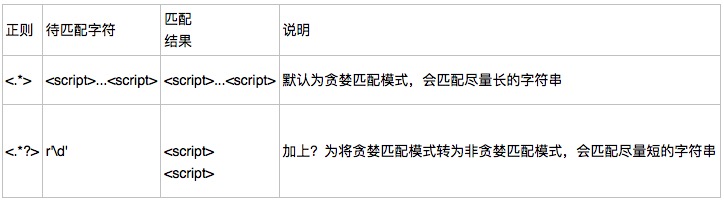
几个常用的非贪婪匹配Pattern
*? 重复任意次,但尽可能少重复
+? 重复1次或更多次,但尽可能少重复
?? 重复0次或1次,但尽可能少重复
{n,m}? 重复n到m次,但尽可能少重复
{n,}? 重复n次以上,但尽可能少重复
.*?的用法:
. 是任意字符
* 是取 0 至 无限长度
? 是非贪婪模式。
何在一起就是 取尽量少的任意字符,一般不会这么单独写,他大多用在:
.*?x
就是取前面任意长度的字符,直到一个x出现
以上是关于正则表达式的主要内容,如果未能解决你的问题,请参考以下文章
正则表达式匹配特定的 URL 片段而不是所有其他 URL 可能性