详细文章:
http://www.cnblogs.com/yuanchenqi/articles/5956943.html
http://www.diveintopython3.net/strings.html
需知:
1.在python2默认编码是ASCII, python3里默认是unicode
2.unicode 分为 utf-32(占4个字节),utf-16(占两个字节),utf-8(占1-4个字节), so utf-16就是现在最常用的unicode版本, 不过在文件里存的还是utf-8,因为utf8省空间
3.在py3中encode,在转码的同时还会把string 变成bytes类型,decode在解码的同时还会把bytes变回string
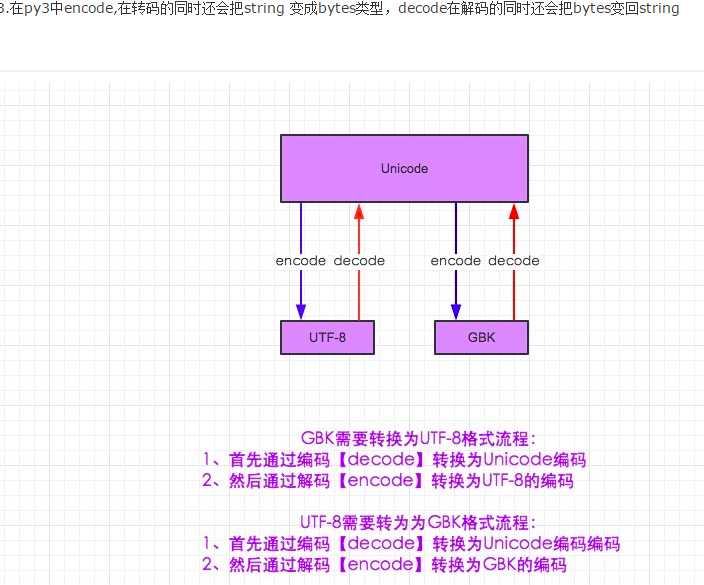
gbk-utf8
s.decode("gbk").encode("utf-8")先转为unicode再转为utf-8
utf-8-gbk
s.decode("utf-8").encode("gbk")先转为unicode再转为gbk
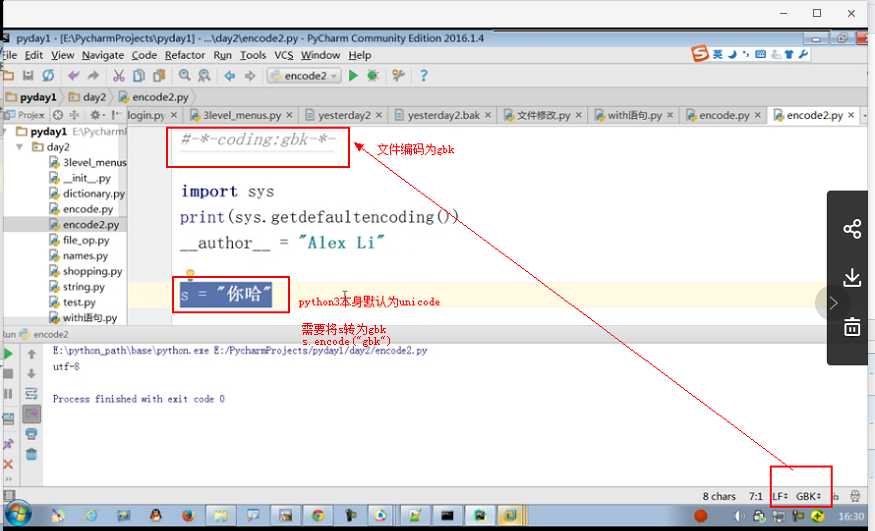
in python3
#-*-coding:gb2312 -*- #这个也可以去掉
__author__ = ‘Alex Li‘
import sys
print(sys.getdefaultencoding())
msg = "我爱北京天安门"
#msg_gb2312 = msg.decode("utf-8").encode("gb2312")
msg_gb2312 = msg.encode("gb2312") #默认就是unicode,不用再decode,喜大普奔
gb2312_to_unicode = msg_gb2312.decode("gb2312")
gb2312_to_utf8 = msg_gb2312.decode("gb2312").encode("utf-8")
print(msg)
print(msg_gb2312)
print(gb2312_to_unicode)
print(gb2312_to_utf8)
