之前提到,深度神经网络在训练中容易遇到梯度消失/爆炸的问题,这个问题产生的根源详见之前的读书笔记。在 Batch Normalization 中,我们将输入数据由激活函数的收敛区调整到梯度较大的区域,在一定程度上缓解了这种问题。不过,当网络的层数急剧增加时,BP 算法中导数的累乘效应还是很容易让梯度慢慢减小直至消失。这篇文章中介绍的深度残差 (Deep Residual) 学习网络可以说根治了这种问题。下面我按照自己的理解浅浅地水一下 Deep Residual Learning 的基本思想,并简单介绍一下深度残差网络的结构。
基本思想
回到最开始的问题,为什么深度神经网络会难以训练?根源在于 BP 的时候我们需要逐层计算导数并将这些导数相乘。这些导数如果太小,梯度就容易消失,反之,则会爆炸。我们没法从 BP 算法的角度出发让这个相乘的导数链消失,因此,可行的方法就是控制每个导数的值,让它们尽量靠近 1,这样,连乘后的结果不会太小,也不会太大。
现在,我们就从导数入手,看看如何实现上面的要求。由于梯度消失的问题比梯度爆炸更常见,因此只针对梯度消失这一点进行改进。
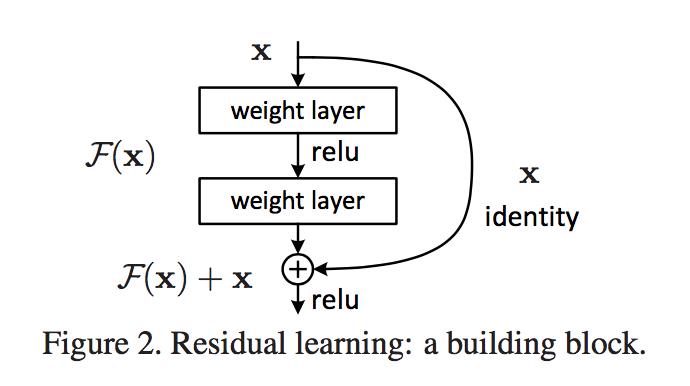
假设我们理想中想让网络学习出来的函数是 \\(F(x; {W_i})\\),但由于它的导数 \\(\\frac{\\partial F}{\\partial x}\\) 太小,所以训练的时候梯度就消失了。所谓太小,就是说 \\(\\frac{\\partial F}{\\partial x} \\approx 0\\),那么,我们何不在这个导数的基础上加上 1 或者减去 1,这样梯度不就变大了吗?(这里的 1 是为了满足之前提到的梯度靠近 1 这一要求,事实上,只要能防止梯度爆炸,其他数值也是可以的,不过作者在之后的实验中证明,1 的效果最好)
按照这种思路,我们现在想构造一个新的函数,让它的导数等于 \\(\\frac{\\partial F}{\\partial x}+1\\)。由这个导数反推回去,很自然地就得到一个我们想要的函数:\\(H(x)=F(x)+x\\),它的导数为:\\(\\frac{\\partial H}{\\partial x} = \\frac{\\partial F}{\\partial x}+1\\)。这个时候你可能会想,如果将原来的 \\(F(x)\\) 变成 \\(H(x)\\),那网络想要提取的特征不就不正确了吗,这个网络还有什么用?不错,我们想要的最终函数是 \\(F(x; {W_i})\\),这个时候再加个 \\(x\\) 上去,结果肯定不是我们想要的。但是,为什么一定要让网络学出 \\(F(x; {W_i})\\)?为什么不用 \\(H(x)\\) 替换原本的 \\(F(x;{W_i})\\),而将网络学习的目标调整为:\\(F(x)=H(x)-x\\)?要知道,神经网络是可以近似任何函数的,只要让网络学出这个新的 \\(F(x)\\),那么我们自然也就可以通过 \\(H(x)=F(x)+x\\) 得到最终想要的函数形式。作者认为,通过这种方式学习得到的 \\(H(x)\\) 函数,跟当初直接让网络学习出的 \\(F(x, {W_i})\\),效果上是等价的,但前者却更容易训练。
==================== UPDATE 2018.1.23 =====================
时隔几个月重新看这篇文章,发现当初的理解存在一个巨大的问题,在此,对那些被我误导的同学深深道歉
以上是关于论文笔记:Deep Residual Learning的主要内容,如果未能解决你的问题,请参考以下文章