软件环境(Windows):
- Visual Studio
- Anaconda
- CUDA
- MinGW-w64
- conda install -c anaconda mingw libpython
- CNTK
- TensorFlow-gpu
- Keras-gpu
- Theano
- MKL
- CuDNN
参考书籍:谢梁 , 鲁颖 , 劳虹岚.Keras快速上手:基于Python的深度学习实战
Keras 简介
Keras 这个名字来源于希腊古典史诗《奥德赛》的牛角之门(Gate of Horn):Those that come through the Ivory Gate cheat us with empty promises that never see fullfillment.Those that come through the Gate of Horn inform the dreamer of trut.
Keras 的优点:
-
Keras 在设计时以人为本,强调快速建模,用户可以快速地将所需模型的结构映射到 Keras 代码中,尽可能减少编写代码的工作量。
-
支持现有的常见结构,比如 CNN、RNN 等。
-
高度模块化,用户几乎能够任意组合各种模块来构造所需的模型:
在 Keras 中,任何神经网络模型都可以被描述为一个图模型或者序列模型,其中的部件被划分为:
- 神经网络层
- 损失函数
- 激活函数
- 初始化方法
- 正则化方法
- 优化引擎 -
基于 Python,用户很容易实现模块的自定义操作。
-
能在 CPU 和 GPU 之间无缝切换。
1 Keras 中的模型
关于Keras模型
Keras 有两种类型的模型,序列模型(Sequential)和 函数式模型(Model),函数式模型应用更为广泛,序列模型是函数式模型的一种特殊情况。函数式模型也叫通用模型。
两类模型均有有两个主要的方法:
model.summary():打印出模型概况,它实际调用的是keras.utils.print_summarymodel.get_config():返回包含模型配置信息的 Python 字典。模型也可以从它的config信息中重构回去
对于 Model: Model.from_config 我不会使用。
对于 Sequential:
config = model.get_config()
model = Sequential.from_config(config)
model.get_layer():依据层名或下标获得层对象model.get_weights():返回模型权重张量的列表,类型为numpy.arraymodel.set_weights():从numpy.array里将权重载入给模型,要求数组具有与model.get_weights()相同的形状。
1.1 Sequential 序列模型
序列模型是函数式模型的简略版(即序列模型是通用模型的一个子类),为最简单的线性、从头到尾的结构顺序,不分叉。即这种模型各层之间是依次顺序的线性关系,在第 \\(k\\) 层和 \\(k+1\\) 层之间可以加上各种元素来构造神经网络。这些元素可以通过一个列表来制定,然后作为参数传递给序列模型来生成相应的模型。
Sequential模型的基本组件:
model.add,添加层;model.compile,模型训练的 BP 模式设置;model.fit,模型训练参数设置 + 训练;- 模型评估
- 模型预测
1.1.1 add:添加层
序贯模型是多个网络层的线性堆叠,也就是“一条路走到黑”。
可以通过向 Sequential 模型传递一个 layer 的 list 来构造该模型:
from keras.models import Sequential
from keras.layers import Dense, Activation
model = Sequential([Dense(32, input_shape=(784,)),
Activation(\'relu\'),
Dense(10),
Activation(\'softmax\'),
])
Using TensorFlow backend.
也可以通过 .add() 方法一个个的将 layer 加入模型中:
model = Sequential()
model.add(Dense(32, input_shape=(784,)))
model.add(Activation(\'relu\'))
model.add(Dense(10))
model.add(Activation(\'softmax\'))
1.1.2 指定输入数据的 shape
模型需要知道输入数据的 shape,因此,Sequential 的第一层需要接受一个关于输入数据 shape 的参数,后面的各个层则可以自动的推导出中间数据的shape,因此不需要为每个层都指定这个参数。有几种方法来为第一层指定输入数据的 shape:
- 传递一个
input_shape的关键字参数给第一层,input_shape是一个 tuple 类型的数据,其中也可以填入None,如果填入None则表示此位置可能是任何正整数。数据的batch大小不应包含在其中。 - 有些2D层,如
Dense,支持通过指定其输入维度input_dim来隐含的指定输入数据 shape,是一个 Int 类型的数据。一些 3D 的时域层支持通过参数input_dim和input_length来指定输入 shape。 - 如果你需要为输入指定一个固定大小的
batch_size(常用于 stateful RNN 网络),可以传递batch_size参数到一个层中,例如你想指定输入张量的batch大小是 \\(32\\),数据shape是 \\((6,8)\\),则你需要传递batch_size=32和input_shape=(6,8)。
model = Sequential()
model.add(Dense(32, input_dim= 784))
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_6 (Dense) (None, 32) 25120
=================================================================
Total params: 25,120
Trainable params: 25,120
Non-trainable params: 0
_________________________________________________________________
model = Sequential()
model.add(Dense(32, input_shape=(784,)))
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_8 (Dense) (None, 32) 25120
=================================================================
Total params: 25,120
Trainable params: 25,120
Non-trainable params: 0
_________________________________________________________________
model = Sequential()
model.add(Dense(100, input_shape= (32, 32, 3)))
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_9 (Dense) (None, 32, 32, 100) 400
=================================================================
Total params: 400
Trainable params: 400
Non-trainable params: 0
_________________________________________________________________
Param 是 \\(400\\):\\(3 \\times 100 + 100\\) (包含偏置项)
model = Sequential()
model.add(Dense(100, input_shape= (32, 32, 3), batch_size= 64))
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_10 (Dense) (64, 32, 32, 100) 400
=================================================================
Total params: 400
Trainable params: 400
Non-trainable params: 0
_________________________________________________________________
1.1.3 编译
在训练模型之前,我们需要通过 compile 来对学习过程进行配置。
compile接收三个参数:
-
优化器
optimizer:该参数可指定为已预定义的优化器名,如rmsprop、adagrad,或一个Optimizer类的对象,详情见优化器optimizers。 -
损失函数
loss:该参数为模型试图最小化的目标函数,它可为预定义的损失函数名,如categorical_crossentropy、mse,也可以为一个自定义损失函数。详情见损失函数loss 。 -
指标列表
metrics:对分类问题,我们一般将该列表设置为metrics=[\'accuracy\']。指标可以是一个预定义指标的名字,也可以是一个用户定制的函数。指标函数应该返回单个张量,或一个完成metric_name - > metric_value映射的字典。 -
sample_weight_mode:如果你需要按时间步为样本赋权( 2D 权矩阵),将该值设为 “temporal”。
默认为 “None”,代表按样本赋权(1D 权)。在下面fit函数的解释中有相关的参考内容。 -
kwargs: 使用 TensorFlow 作为后端请忽略该参数,若使用 Theano 作为后端,kwargs的值将会传递给K.function
注意:
模型在使用前必须编译,否则在调用 fit 或 evaluate 时会抛出异常。
# For a multi-class classification problem
model.compile(optimizer=\'rmsprop\',
loss=\'categorical_crossentropy\',
metrics=[\'accuracy\'])
# For a binary classification problem
model.compile(optimizer=\'rmsprop\',
loss=\'binary_crossentropy\',
metrics=[\'accuracy\'])
# For a mean squared error regression problem
model.compile(optimizer=\'rmsprop\',
loss=\'mse\')
# For custom metrics
import keras.backend as K
def mean_pred(y_true, y_pred):
return K.mean(y_pred)
model.compile(optimizer=\'rmsprop\',
loss=\'binary_crossentropy\',
metrics=[\'accuracy\', mean_pred])
1.1.3 训练
Keras以 Numpy 数组作为输入数据和标签的数据类型。训练模型一般使用 fit 函数:
fit(self, x, y, batch_size=32, epochs=10, verbose=1, callbacks=None, validation_split=0.0, validation_data=None, shuffle=True, class_weight=None, sample_weight=None, initial_epoch=0)
本函数将模型训练 epochs 轮,其参数有:
-
x:输入数据。如果模型只有一个输入,那么x的类型是 numpy array,如果模型有多个输入,那么x的类型应当为 list,list 的元素是对应于各个输入的 numpy array -
y:标签,numpy array -
batch_size:整数,指定进行梯度下降时每个 batch 包含的样本数。训练时一个 batch 的样本会被计算一次梯度下降,使目标函数优化一步。 -
epochs:整数,训练的轮数,每个 epoch 会把训练集轮一遍。 -
verbose:日志显示,0为不在标准输出流输出日志信息,1为输出进度条记录,2为每个epoch输出一行记录 -
callbacks:list,其中的元素是 keras.callbacks.Callback 的对象。这个 list 中的回调函数将会在训练过程中的适当时机被调用,参考回调函数 -
validation_split:\\(0 - 1\\) 之间的浮点数,用来指定训练集的一定比例数据作为验证集。验证集将不参与训练,并在每个 epoch 结束后测试的模型的指标,如损失函数、精确度等。- 注意,validation_split 的划分在 shuffle 之前,因此如果你的数据本身是有序的,需要先手工打乱再指定validation_split,否则可能会出现验证集样本不均匀。
-
validation_data:形式为(X, y)的 tuple,是指定的验证集。此参数将覆盖 validation_spilt。 -
shuffle:布尔值或字符串,一般为布尔值,表示是否在训练过程中随机打乱输入样本的顺序。若为字符串 “batch”,则是用来处理 HDF5 数据的特殊情况,它将在 batch 内部将数据打乱。 -
class_weight:字典,将不同的类别映射为不同的权值,该参数用来在训练过程中调整损失函数(只能用于训练) -
sample_weight:权值的numpy array,用于在训练时调整损失函数(仅用于训练)。可以传递一个 1D 的与样本等长的向量用于对样本进行 \\(1\\) 对 \\(1\\) 的加权,或者在面对时序数据时,传递一个的形式为(samples,sequence_length)的矩阵来为每个时间步上的样本赋不同的权。这种情况下请确定在编译模型时添加了sample_weight_mode=\'temporal\'。 -
initial_epoch: 从该参数指定的 epoch 开始训练,在继续之前的训练时有用。
fit函数返回一个 History 的对象,其 History.history 属性记录了损失函数和其他指标的数值随 epoch 变化的情况,如果有验证集的话,也包含了验证集的这些指标变化情况
注意:
要与之后的 fit_generator 做区别,两者输入 x/y 不同。
案例一:简单的2分类
\\(epoch = batch\\_size \\times iteration\\) ,\\(10\\) 次 epoch 代表训练十次训练集
from keras.models import Sequential
from keras.layers import Dense, Activation
# 模型搭建阶段
model= Sequential() # 代表类的初始化
# Dense(32) is a fully-connected layer with 32 hidden units.
model.add(Dense(32, activation=\'relu\', input_dim= 100))
model.add(Dense(1, activation=\'sigmoid\'))
# For custom metrics
import keras.backend as K
def mean_pred(y_true, y_pred):
return K.mean(y_pred)
model.compile(optimizer=\'rmsprop\',
loss=\'binary_crossentropy\',
metrics=[\'accuracy\', mean_pred])
# Generate dummy data
import numpy as np
data = np.random.random((1000, 100))
labels = np.random.randint(2, size=(1000, 1))
# Train the model, iterating on the data in batches of 32 samples
model.fit(data, labels, epochs =10, batch_size=32)
Using TensorFlow backend.
Epoch 1/10
1000/1000 [==============================] - 3s - loss: 0.7218 - acc: 0.4780 - mean_pred: 0.5181
Epoch 2/10
1000/1000 [==============================] - 0s - loss: 0.7083 - acc: 0.4990 - mean_pred: 0.5042
Epoch 3/10
1000/1000 [==============================] - 0s - loss: 0.7053 - acc: 0.4850 - mean_pred: 0.5174
Epoch 4/10
1000/1000 [==============================] - 0s - loss: 0.6978 - acc: 0.5400 - mean_pred: 0.5074
Epoch 5/10
1000/1000 [==============================] - 0s - loss: 0.6938 - acc: 0.5250 - mean_pred: 0.5088
Epoch 6/10
1000/1000 [==============================] - 0s - loss: 0.6887 - acc: 0.5290 - mean_pred: 0.5196
Epoch 7/10
1000/1000 [==============================] - 0s - loss: 0.6847 - acc: 0.5570 - mean_pred: 0.5052
Epoch 8/10
1000/1000 [==============================] - 0s - loss: 0.6797 - acc: 0.5530 - mean_pred: 0.5134
Epoch 9/10
1000/1000 [==============================] - 0s - loss: 0.6749 - acc: 0.5790 - mean_pred: 0.5126
Epoch 10/10
1000/1000 [==============================] - 0s - loss: 0.6728 - acc: 0.5920 - mean_pred: 0.5118
<keras.callbacks.History at 0x1eafe9b9240>
1.1.4 evaluate 模型评估
evaluate(self, x, y, batch_size=32, verbose=1, sample_weight=None)
本函数按 batch 计算在某些输入数据上模型的误差,其参数有:
-
x:输入数据,与 fit 一样,是 numpy array 或 numpy array 的 list -
y:标签,numpy array -
batch_size:整数,含义同 fit 的同名参数 -
verbose:含义同fit的同名参数,但只能取0或1 -
sample_weight:numpy array,含义同 fit 的同名参数
本函数返回一个测试误差的标量值(如果模型没有其他评价指标),或一个标量的 list(如果模型还有其他的评价指标)。model.metrics_names将给出 list 中各个值的含义。
model.evaluate(data, labels, batch_size=32)
512/1000 [==============>...............] - ETA: 0s
[0.62733754062652591, 0.68200000000000005, 0.54467054557800298]
model.metrics_names
[\'loss\', \'acc\', \'mean_pred\']
1.1.5 predict 模型预测
predict(self, x, batch_size=32, verbose=0)
predict_classes(self, x, batch_size=32, verbose=1)
predict_proba(self, x, batch_size=32, verbose=1)
predict函数按 batch 获得输入数据对应的输出,函数的返回值是预测值的 numpy array 其参数有:predict_classes:本函数按batch产生输入数据的类别预测结果;predict_proba:本函数按 batch 产生输入数据属于各个类别的概率
model.predict_proba?
model.predict(data[:5])
array([[ 0.39388809],
[ 0.39062682],
[ 0.59655035],
[ 0.53066045],
[ 0.56720185]], dtype=float32)
model.predict_classes(data[:5])
5/5 [==============================] - 0s
array([[0],
[0],
[1],
[1],
[1]])
model.predict_proba(data[:5])
5/5 [==============================] - 0s
array([[ 0.39388809],
[ 0.39062682],
[ 0.59655035],
[ 0.53066045],
[ 0.56720185]], dtype=float32)
1.1.6 on_batch 的结果,模型检查
train_on_batch:本函数在一个 batch 的数据上进行一次参数更新,函数返回训练误差的标量值或标量值的 list,与 evaluate 的情形相同。test_on_batch:本函数在一个 batch 的样本上对模型进行评估,函数的返回与 evaluate 的情形相同predict_on_batch:本函数在一个 batch 的样本上对模型进行测试,函数返回模型在一个 batch 上的预测结果
model.train_on_batch(data, labels)
[0.62733746, 0.68199992, 0.54467058]
model.train_on_batch(data, labels)
[0.62483531, 0.68799996, 0.52803379]
1.1.7 fit_generator
- 利用 Python 的生成器,逐个生成数据的 batch 并进行训练。
- 生成器与模型将并行执行以提高效率。
- 例如,该函数允许我们在 CPU 上进行实时的数据提升,同时在 GPU 上进行模型训练
参考链接:http://keras-cn.readthedocs.io/en/latest/models/sequential/
有了该函数,图像分类训练任务变得很简单。
model.fit_generator(generator, steps_per_epoch, epochs=1, verbose=1, callbacks=None, validation_data=None, validation_steps=None, class_weight=None, max_queue_size=10, workers=1, use_multiprocessing=False, initial_epoch=0)
函数的参数是:
generator:生成器函数,生成器的输出应该为:- 一个形如
(inputs,targets)的tuple - 一个形如
(inputs, targets,sample_weight)的 tuple。
所有的返回值都应该包含相同数目的样本。生成器将无限在数据集上循环。每个 epoch 以经过模型的样本数达到 samples_per_epoch 时,记一个 epoch 结束。
- 一个形如
steps_per_epoch:整数,当生成器返回steps_per_epoch次数据时计一个 epoch 结束,执行下一个 epochepochs:整数,数据迭代的轮数verbose:日志显示,0为不在标准输出流输出日志信息,1为输出进度条记录,2为每个 epoch 输出一行记录validation_data:具有以下三种形式之一- 生成验证集的生成器
- 一个形如
(inputs,targets)的tuple - 一个形如
(inputs,targets,sample_weights)的tuple
validation_steps: 当validation_data为生成器时,本参数指定验证集的生成器返回次数class_weight:规定类别权重的字典,将类别映射为权重,常用于处理样本不均衡问题。sample_weight:权值的 numpy array,用于在训练时调整损失函数(仅用于训练)。可以传递一个1D的与样本等长的向量用于对样本进行 \\(1\\) 对\\(1\\) 的加权,或者在面对时序数据时,传递一个的形式为(samples,sequence_length)的矩阵来为每个时间步上的样本赋不同的权。这种情况下请确定在编译模型时添加了sample_weight_mode=\'temporal\'。workers:最大进程数max_q_size:生成器队列的最大容量pickle_safe: 若为真,则使用基于进程的线程。由于该实现依赖多进程,不能传递non picklable(无法被 pickle 序列化)的参数到生成器中,因为无法轻易将它们传入子进程中。initial_epoch: 从该参数指定的 epoch 开始训练,在继续之前的训练时有用。
函数返回一个 History 对象。
例子
def generate_arrays_from_file(path):
while 1:
f = open(path)
for line in f:
# create Numpy arrays of input data
# and labels, from each line in the file
x, y = process_line(line)
yield (x, y)
f.close()
model.fit_generator(generate_arrays_from_file(\'/my_file.txt\'), steps_per_epoch= 1000, epochs=10)
1.1.8 其他的两个辅助的内容:
evaluate_generator:本函数使用一个生成器作为数据源评估模型,生成器应返回与 test_on_batch 的输入数据相同类型的数据。该函数的参数与 fit_generator 同名参数含义相同,steps 是生成器要返回数据的轮数。predcit_generator:本函数使用一个生成器作为数据源预测模型,生成器应返回与 test_on_batch 的输入数据相同类型的数据。该函数的参数与 fit_generator 同名参数含义相同,steps 是生成器要返回数据的轮数。
案例二:多分类-VGG的卷积神经网络
注意:keras.utils.to_categorical 的用法:
类似于 One-Hot 编码:
keras.utils.to_categorical(y, num_classes=None)
# -*- coding:utf-8 -*-
import numpy as np
import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras.optimizers import SGD
from keras.utils import np_utils
# Generate dummy data
x_train = np.random.random((100, 100, 100, 3))
# 100张图片,每张 100*100*3
y_train = keras.utils.to_categorical(np.random.randint(10, size=(100, 1)), num_classes=10)
# 100*10
x_test = np.random.random((20, 100, 100, 3))
y_test = keras.utils.to_categorical(np.random.randint(10, size=(20, 1)), num_classes=10)
# 20*100
model = Sequential()#最简单的线性、从头到尾的结构顺序,不分叉
# input: 100x100 images with 3 channels -> (100, 100, 3) tensors.
# this applies 32 convolution filters of size 3x3 each.
model.add(Conv2D(32, (3, 3), activation=\'relu\', input_shape=(100, 100, 3)))
model.add(Conv2D(32, (3, 3), activation=\'relu\'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), activation=\'relu\'))
model.add(Conv2D(64, (3, 3), activation=\'relu\'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(256, activation=\'relu\'))
model.add(Dropout(0.5))
model.add(Dense(10, activation=\'softmax\'))
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss=\'categorical_crossentropy\', optimizer=sgd)
model.fit(x_train, y_train, batch_size=32, epochs=10)
score = model.evaluate(x_test, y_test, batch_size=32)
score
Epoch 1/10
100/100 [==============================] - 1s - loss: 2.3800
Epoch 2/10
100/100 [==============================] - 0s - loss: 2.3484
Epoch 3/10
100/100 [==============================] - 0s - loss: 2.3034
Epoch 4/10
100/100 [==============================] - 0s - loss: 2.2938
Epoch 5/10
100/100 [==============================] - 0s - loss: 2.2874
Epoch 6/10
100/100 [==============================] - 0s - loss: 2.2873
Epoch 7/10
100/100 [==============================] - 0s - loss: 2.3132 - ETA: 0s - loss: 2.31
Epoch 8/10
100/100 [==============================] - 0s - loss: 2.2866
Epoch 9/10
100/100 [==============================] - 0s - loss: 2.2814
Epoch 10/10
100/100 [==============================] - 0s - loss: 2.2856
20/20 [==============================] - 0s
2.2700035572052002
使用LSTM的序列分类
采用stateful LSTM的相同模型
stateful LSTM的特点是,在处理过一个batch的训练数据后,其内部状态(记忆)会被作为下一个batch的训练数据的初始状态。状态LSTM使得我们可以在合理的计算复杂度内处理较长序列
from keras.models import Sequential
from keras.layers import LSTM, Dense
import numpy as np
data_dim = 16
timesteps = 8
num_classes = 10
batch_size = 32
# Expected input batch shape: (batch_size, timesteps, data_dim)
# Note that we have to provide the full batch_input_shape since the network is stateful.
# the sample of index i in batch k is the follow-up for the sample i in batch k-1.
model = Sequential()
model.add(LSTM(32, return_sequences=True, stateful=True,
batch_input_shape=(batch_size, timesteps, data_dim)))
model.add(LSTM(32, return_sequences=True, stateful=True))
model.add(LSTM(32, stateful=True))
model.add(Dense(10, activation=\'softmax\'))
model.compile(loss=\'categorical_crossentropy\',
optimizer=\'rmsprop\',
metrics=[\'accuracy\'])
# Generate dummy training data
x_train = np.random.random((batch_size * 10, timesteps, data_dim))
y_train = np.random.random((batch_size * 10, num_classes))
# Generate dummy validation data
x_val = np.random.random((batch_size * 3, timesteps, data_dim))
y_val = np.random.random((batch_size * 3, num_classes))
model.fit(x_train, y_train,
batch_size=batch_size, epochs=5, shuffle=False,
validation_data=(x_val, y_val))
Train on 320 samples, validate on 96 samples
Epoch 1/5
320/320 [==============================] - 2s - loss: 11.4843 - acc: 0.1062 - val_loss: 11.2222 - val_acc: 0.1042
Epoch 2/5
320/320 [==============================] - 0s - loss: 11.4815 - acc: 0.1031 - val_loss: 11.2207 - val_acc: 0.1250
Epoch 3/5
320/320 [==============================] - 0s - loss: 11.4799 - acc: 0.0844 - val_loss: 11.2202 - val_acc: 0.1562
Epoch 4/5
320/320 [==============================] - 0s - loss: 11.4790 - acc: 0.1000 - val_loss: 11.2198 - val_acc: 0.1562
Epoch 5/5
320/320 [==============================] - 0s - loss: 11.4780 - acc: 0.1094 - val_loss: 11.2194 - val_acc: 0.1250
<keras.callbacks.History at 0x1ab0e78ff28>
Keras FAQ:
常见问题: http://keras-cn.readthedocs.io/en/latest/for_beginners/FAQ/
1.2 Model(通用模型)(或者称为函数式(Functional)模型)
函数式模型称作 Functional,但它的类名是 Model,因此我们有时候也用 Model 来代表函数式模型。
Keras函数式模型接口是用户定义多输出模型、非循环有向模型或具有共享层的模型等复杂模型的途径。函数式模型是最广泛的一类模型,序贯模型(Sequential)只是它的一种特殊情况。更多关于序列模型的资料参考: 序贯模型API
通用模型可以用来设计非常复杂、任意拓扑结构的神经网络。类似于序列模型,通用模型采用函数化的应用接口来定义模型。
在定义的时候,从输入的多维矩阵开始,然后定义各层及其要素,最后定义输出层。将输入层与输出层作为参数纳入通用模型中就可以定义一个模型对象,并进行编译和拟合。
函数式模型基本属性与训练流程:
model.layers,添加层信息;model.compile,模型训练的BP模式设置;model.fit,模型训练参数设置 + 训练;evaluate,模型评估;predict模型预测
1.2.1 常用Model属性
model.layers:组成模型图的各个层model.inputs:模型的输入张量列表model.outputs:模型的输出张量列表
1.2.2 compile 训练模式设置
compile(self, optimizer, loss, metrics=None, loss_weights=None, sample_weight_mode=None)
本函数编译模型以供训练,参数有
optimizer:优化器,为预定义优化器名或优化器对象loss:损失函数,为预定义损失函数名或一个目标函数metrics:列表,包含评估模型在训练和测试时的性能的指标,典型用法是metrics=[\'accuracy\']如果要在多输出模型中为不同的输出指定不同的指标,可像该参数传递一个字典,例如metrics={\'ouput_a\': \'accuracy\'}sample_weight_mode:如果你需要按时间步为样本赋权( 2D 权矩阵),将该值设为 “temporal”。默认为 “None”,代表按样本赋权(1D权)。
如果模型有多个输出,可以向该参数传入指定sample_weight_mode的字典或列表。在下面fit函数的解释中有相关的参考内容。
【Tips】如果你只是载入模型并利用其 predict,可以不用进行 compile。在Keras中,compile 主要完成损失函数和优化器的一些配置,是为训练服务的。predict 会在内部进行符号函数的编译工作(通过调用_make_predict_function 生成函数)
1.2.3 fit 模型训练参数设置 + 训练
fit(self, x=None, y=None, batch_size=32, epochs=1, verbose=1, callbacks=None, validation_split=0.0, validation_data=None, shuffle=True, class_weight=None, sample_weight=None, initial_epoch=0)
与序列模型类似
1.2.4 evaluate,模型评估
evaluate(self, x, y, batch_size=32, verbose=1, sample_weight=None)
与序列模型类似
1.2.5 predict 模型预测
predict(self, x, batch_size=32, verbose=0)
与序列模型类似
1.2.6 模型检查
train_on_batch:本函数在一个 batch 的数据上进行一次参数更新,函数返回训练误差的标量值或标量值的 list,与 evaluate 的情形相同。test_on_batch:本函数在一个 batch 的样本上对模型进行评估,函数的返回与 evaluate 的情形相同predict_on_batch:本函数在一个 batch 的样本上对模型进行测试,函数返回模型在一个 batch 上的预测结果
与序列模型类似
1.2.7 fit_generator
fit_generator(self, generator, steps_per_epoch, epochs=1, verbose=1, callbacks=None, validation_data=None, validation_steps=None, class_weight=None, max_q_size=10, workers=1, pickle_safe=False, initial_epoch=0) evaluate_generator(self, generator, steps, max_q_size=10, workers=1, pickle_safe=False)
案例三:全连接网络
在开始前,有几个概念需要澄清:
- 层对象接受张量为参数,返回一个张量。
- 输入是张量,输出也是张量的一个框架就是一个模型,通过
Model定义。 - 这样的模型可以被像Keras的
Sequential一样被训练
import keras
from keras.layers import Input, Dense
from keras.models import Model
# 层实例接受张量为参数,返回一个张量
inputs = Input(shape=(100,))
# a layer instance is callable on a tensor, and returns a tensor
# 输入inputs,输出x
# (inputs)代表输入
x = Dense(64, activation=\'relu\')(inputs)
# 输入x,输出x
x = Dense(64, activation=\'relu\')(x)
predictions = Dense(100, activation=\'softmax\')(x)
# 输入x,输出分类
# This creates a model that includes
# the Input layer and three Dense layers
model = Model(inputs=inputs, outputs=predictions)
model.compile(optimizer=\'rmsprop\',
loss=\'categorical_crossentropy\',
metrics=[\'accuracy\'])
# Generate dummy data
import numpy as np
data = np.random.random((1000, 100))
labels = keras.utils.to_categorical(np.random.randint(2, size=(1000, 1)), num_classes=100)
# Train the model
model.fit(data, labels, batch_size=64, epochs=10) # starts training
Epoch 1/10
1000/1000 [==============================] - 0s - loss: 2.2130 - acc: 0.4650
Epoch 2/10
1000/1000 [==============================] - 0s - loss: 0.7474 - acc: 0.4980
Epoch 3/10
1000/1000 [==============================] - 0s - loss: 0.7158 - acc: 0.5050
Epoch 4/10
1000/1000 [==============================] - 0s - loss: 0.7039 - acc: 0.5260
Epoch 5/10
1000/1000 [==============================] - 0s - loss: 0.7060 - acc: 0.5280
Epoch 6/10
1000/1000 [==============================] - 0s - loss: 0.6979 - acc: 0.5270
Epoch 7/10
1000/1000 [==============================] - 0s - loss: 0.6854 - acc: 0.5570
Epoch 8/10
1000/1000 [==============================] - 0s - loss: 0.6920 - acc: 0.5300
Epoch 9/10
1000/1000 [==============================] - 0s - loss: 0.6862 - acc: 0.5620
Epoch 10/10
1000/1000 [==============================] - 0s - loss: 0.6766 - acc: 0.5750
<keras.callbacks.History at 0x1ec3dd2d5c0>
inputs
<tf.Tensor \'input_4:0\' shape=(?, 100) dtype=float32>
可以看到结构与序贯模型完全不一样,其中 x = Dense(64, activation=\'relu\')(inputs) 中:(input)代表输入;x 代表输出
model = Model(inputs=inputs, outputs=predictions) 该句是函数式模型的经典,可以同时输入两个 input,然后输出 output两个。
下面的时间序列模型,我不懂。。。。。。。。。
案例四:视频处理
现在用来做迁移学习;
-
还可以通过
TimeDistributed来进行实时预测; -
input_sequences代表序列输入;model代表已训练的模型
x = Input(shape=(100,))
# This works, and returns the 10-way softmax we defined above.
y = model(x)
# model里面存着权重,然后输入 x,输出结果,用来作 fine-tuning
# 分类 -> 视频、实时处理
from keras.layers import TimeDistributed
# Input tensor for sequences of 20 timesteps,
# each containing a 100-dimensional vector
input_sequences = Input(shape=(20, 100))
# 20个时间间隔,输入 100 维度的数据
# This applies our previous model to every timestep in the input sequences.
# the output of the previous model was a 10-way softmax,
# so the output of the layer below will be a sequence of 20 vectors of size 10.
processed_sequences = TimeDistributed(model)(input_sequences) # Model是已经训练好的
processed_sequences
<tf.Tensor \'time_distributed_1/Reshape_1:0\' shape=(?, 20, 100) dtype=float32>
案例五:双输入、双模型输出:LSTM 时序预测
本案例很好,可以了解到 Model 的精髓在于他的任意性,给编译者很多的便利。
- 输入:
- 新闻语料;新闻语料对应的时间
- 输出:
- 新闻语料的预测模型;新闻语料+对应时间的预测模型
模型一:只针对新闻语料的 LSTM 模型
from keras.layers import Input, Embedding, LSTM, Dense
from keras.models import Model
# Headline input: meant to receive sequences of 100 integers, between 1 and 10000.
# Note that we can name any layer by passing it a "name" argument.
main_input = Input(shape=(100,), dtype=\'int32\', name=\'main_input\')
# 一个100词的 BOW 序列
# This embedding layer will encode the input sequence
# into a sequence of dense 512-dimensional vectors.
x = Embedding(output_dim=512, input_dim=10000, input_length=100)(main_input)
# Embedding 层,把 100 维度再 encode 成 512 的句向量,10000 指的是词典单词总数
# A LSTM will transform the vector sequence into a single vector,
# containing information about the entire sequence
lstm_out = LSTM(32)(x)
# ? 32什么意思?????????????????????
#然后,我们插入一个额外的损失,使得即使在主损失很高的情况下,LSTM 和 Embedding 层也可以平滑的训练。
auxiliary_output = Dense(1, activation=\'sigmoid\', name=\'aux_output\')(lstm_out)
#再然后,我们将LSTM与额外的输入数据串联起来组成输入,送入模型中:
# 模型一:只针对以上的序列做的预测模型
组合模型:新闻语料+时序
# 模型二:组合模型
auxiliary_input = Input(shape=(5,), name=\'aux_input\') # 新加入的一个Input,5维度
x = keras.layers.concatenate([lstm_out, auxiliary_input]) # 组合起来,对应起来
# We stack a deep densely-connected network on top
# 组合模型的形式
x = Dense(64, activation=\'relu\')(x)
x = Dense(64, activation=\'relu\')(x)
x = Dense(64, activation=\'relu\')(x)
# And finally we add the main logistic regression layer
main_output = Dense(1, activation=\'sigmoid\', name=\'main_output\')(x)
#最后,我们定义整个2输入,2输出的模型:
model = Model(inputs=[main_input, auxiliary_input], outputs=[main_output, auxiliary_output])
#模型定义完毕,下一步编译模型。
#我们给额外的损失赋0.2的权重。我们可以通过关键字参数loss_weights或loss来为不同的输出设置不同的损失函数或权值。
#这两个参数均可为Python的列表或字典。这里我们给loss传递单个损失函数,这个损失函数会被应用于所有输出上。
其中:Model(inputs=[main_input, auxiliary_input], outputs=[main_output, auxiliary_output]) 是核心,
Input 两个内容,outputs 两个模型:
# 训练方式一:两个模型一个loss
model.compile(optimizer=\'rmsprop\', loss=\'binary_crossentropy\',
loss_weights=[1., 0.2])
#编译完成后,我们通过传递训练数据和目标值训练该模型:
model.fit([headline_data, additional_data], [labels, labels],
epochs=50, batch_size=32)
# 训练方式二:两个模型,两个Loss
#因为我们输入和输出是被命名过的(在定义时传递了“name”参数),我们也可以用下面的方式编译和训练模型:
model.compile(optimizer=\'rmsprop\',
loss={\'main_output\': \'binary_crossentropy\', \'aux_output\': \'binary_crossentropy\'},
loss_weights={\'main_output\': 1., \'aux_output\': 0.2})
# And trained it via:
model.fit({\'main_input\': headline_data, \'aux_input\': additional_data},
{\'main_output\': labels, \'aux_output\': labels},
epochs=50, batch_size=32)
因为输入两个,输出两个模型,所以可以分为设置不同的模型训练参数
案例六:共享层:对应关系、相似性
一个节点,分成两个分支出去
import keras
from keras.layers import Input, LSTM, Dense
from keras.models import Model
tweet_a = Input(shape=(140, 256))
tweet_b = Input(shape=(140, 256))
#若要对不同的输入共享同一层,就初始化该层一次,然后多次调用它
# 140个单词,每个单词256维度,词向量
#
# This layer can take as input a matrix
# and will return a vector of size 64
shared_lstm = LSTM(64)
# 返回一个64规模的向量
# When we reuse the same layer instance
# multiple times, the weights of the layer
# are also being reused
# (it is effectively *the same* layer)
encoded_a = shared_lstm(tweet_a)
encoded_b = shared_lstm(tweet_b)
# We can then concatenate the two vectors:
# 连接两个结果
# axis=-1?????
merged_vector = keras.layers.concatenate([encoded_a, encoded_b], axis=-1)
# And add a logistic regression on top
predictions = Dense(1, activation=\'sigmoid\')(merged_vector)
# 其中的1 代表什么????
# We define a trainable model linking the
# tweet inputs to the predictions
model = Model(inputs=[tweet_a, tweet_b], outputs=predictions)
model.compile(optimizer=\'rmsprop\',
loss=\'binary_crossentropy\',
metrics=[\'accuracy\'])
model.fit([data_a, data_b], labels, epochs=10)
# 训练模型,然后预测
案例七:抽取层节点内容
# 1、单节点
a = Input(shape=(140, 256))
lstm = LSTM(32)
encoded_a = lstm(a)
assert lstm.output == encoded_a
# 抽取获得encoded_a的输出张量
# 2、多节点
a = Input(shape=(140, 256))
b = Input(shape=(140, 256))
lstm = LSTM(32)
encoded_a = lstm(a)
encoded_b = lstm(b)
assert lstm.get_output_at(0) == encoded_a
assert lstm.get_output_at(1) == encoded_b
# 3、图像层节点
# 对于input_shape和output_shape也是一样,如果一个层只有一个节点,
#或所有的节点都有相同的输入或输出shape,
#那么input_shape和output_shape都是没有歧义的,并也只返回一个值。
#但是,例如你把一个相同的Conv2D应用于一个大小为(3,32,32)的数据,
#然后又将其应用于一个(3,64,64)的数据,那么此时该层就具有了多个输入和输出的shape,
#你就需要显式的指定节点的下标,来表明你想取的是哪个了
a = Input(shape=(3, 32, 32))
b = Input(shape=(3, 64, 64))
conv = Conv2D(16, (3, 3), padding=\'same\')
conved_a = conv(a)
# Only one input so far, the following will work:
assert conv.input_shape == (None, 3, 32, 32)
conved_b = conv(b)
# now the `.input_shape` property wouldn\'t work, but this does:
assert conv.get_input_shape_at(0) == (None, 3, 32, 32)
assert conv.get_input_shape_at(1) == (None, 3, 64, 64)
案例八:视觉问答模型
#这个模型将自然语言的问题和图片分别映射为特征向量,
#将二者合并后训练一个logistic回归层,从一系列可能的回答中挑选一个。
from keras.layers import Conv2D, MaxPooling2D, Flatten
from keras.layers import Input, LSTM, Embedding, Dense
from keras.models import Model, Sequential
# First, let\'s define a vision model using a Sequential model.
# This model will encode an image into a vector.
vision_model = Sequential()
vision_model.add(Conv2D(64, (3, 3) activation=\'relu\', padding=\'same\', input_shape=(3, 224, 224)))
vision_model.add(Conv2D(64, (3, 3), activation=\'relu\'))
vision_model.add(MaxPooling2D((2, 2)))
vision_model.add(Conv2D(128, (3, 3), activation=\'relu\', padding=\'same\'))
vision_model.add(Conv2D(128, (3, 3), activation=\'relu\'))
vision_model.add(MaxPooling2D((2, 2)))
vision_model.add(Conv2D(256, (3, 3), activation=\'relu\', padding=\'same\'))
vision_model.add(Conv2D(256, (3, 3), activation=\'relu\'))
vision_model.add(Conv2D(256, (3, 3), activation=\'relu\'))
vision_model.add(MaxPooling2D((2, 2)))
vision_model.add(Flatten())
# Now let\'s get a tensor with the output of our vision model:
image_input = Input(shape=(3, 224, 224))
encoded_image = vision_model(image_input)
# Next, let\'s define a language model to encode the question into a vector.
# Each question will be at most 100 word long,
# and we will index words as integers from 1 to 9999.
question_input = Input(shape=(100,), dtype=\'int32\')
embedded_question = Embedding(input_dim=10000, output_dim=256, input_length=100)(question_input)
encoded_question = LSTM(256)(embedded_question)
# Let\'s concatenate the question vector and the image vector:
merged = keras.layers.concatenate([encoded_question, encoded_image])
# And let\'s train a logistic regression over 1000 words on top:
output = Dense(1000, activation=\'softmax\')(merged)
# This is our final model:
vqa_model = Model(inputs=[image_input, question_input], outputs=output)
# The next stage would be training this model on actual data.
延伸一:fine-tuning 时如何加载 No_top 的权重
如果你需要加载权重到不同的网络结构(有些层一样)中,例如 fine-tune 或 transfer-learning,你可以通过层名字来加载模型:
model.load_weights(‘my_model_weights.h5’, by_name=True)
例如:
假如原模型为:
model = Sequential()
model.add(Dense(2, input_dim=3, name="dense_1"))
model.add(Dense(3, name="dense_2"))
...
model.save_weights(fname)
新模型为:
model = Sequential()
model.add(Dense(2, input_dim=3, name="dense_1")) # will be loaded
model.add(Dense(10, name="new_dense")) # will not be loaded
# load weights from first model; will only affect the first layer, dense_1.
model.load_weights(fname, by_name=True)
2 学习资料
3 keras 学习小结
引自:http://blog.csdn.net/sinat_26917383/article/details/72857454
3.1 keras网络结构

3.2 keras网络配置

其中回调函数 callbacks 是keras
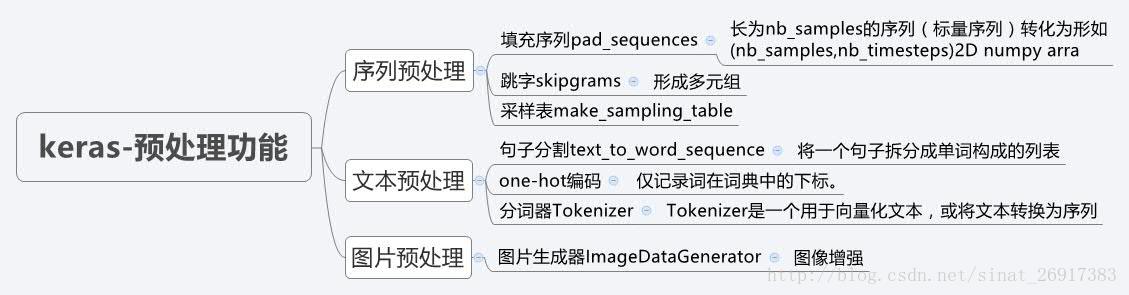
3.3 keras预处理功能
3.4 模型的节点信息提取
对于序列模型
%%time
import keras
from keras.models import Sequential
from keras.layers import Dense
import numpy as np
# 实现 Lenet
import keras
from keras.datasets import mnist
(x_train, y_train), (x_test,y_test) = mnist.load_data()
x_train=x_train.reshape(-1, 28,28,1)
x_test=x_test.reshape(-1, 28,28,1)
x_train=x_train/255.
x_test=x_test/255.
y_train=keras.utils.to_categorical(y_train)
y_test=keras.utils.to_categorical(y_test)
from keras.layers import Conv2D, MaxPool2D, Dense, Flatten
from keras.models import Sequential
lenet=Sequential()
lenet.add(Conv2D(6, kernel_size=3,strides=1, padding=\'same\', input_shape=(28, 28, 1)))
lenet.add(MaxPool2D(pool_size=2,strides=2))
lenet.add(Conv2D(16, kernel_size=5, strides=1, padding=\'valid\'))
lenet.add(MaxPool2D(pool_size=2, strides=2))
lenet.add(Flatten())
lenet.add(Dense(120))
lenet.add(Dense(84))
lenet.add(Dense(10, activation=\'softmax\'))
lenet.compile(\'sgd\',loss=\'categorical_crossentropy\',metrics=[\'accuracy\']) # 编译模型
lenet.fit(x_train,y_train,batch_size=64,epochs= 20,validation_data=[x_test,y_test], verbose= 0) # 训练模型
lenet.save(\'E:/Graphs/Models/myletnet.h5\') # 保存模型
Wall time: 2min 48s
# 节点信息提取
config = lenet.get_config() # 把 lenet 模型中的信息提取出来
config[0]
{\'class_name\': \'Conv2D\',
\'config\': {\'activation\': \'linear\',
\'activity_regularizer\': None,
\'batch_input_shape\': (None, 28, 28, 1),
\'bias_constraint\': None,
\'bias_initializer\': {\'class_name\': \'Zeros\', \'config\': {}},
\'bias_regularizer\': None,
\'data_format\': \'channels_last\',
\'dilation_rate\': (1, 1),
\'dtype\': \'float32\',
\'filters\': 6,
\'kernel_constraint\': None,
\'kernel_initializer\': {\'class_name\': \'VarianceScaling\',
\'config\': {\'distribution\': \'uniform\',
\'mode\': \'fan_avg\',
\'scale\': 1.0,
\'seed\': None}},
\'kernel_regularizer\': None,
\'kernel_size\': (3, 3),
\'name\': \'conv2d_7\',
\'padding\': \'same\',
\'strides\': (1, 1),
\'trainable\': True,
\'use_bias\': True}}
model = Sequential.from_config(config) # 将提取的信息传给新的模型, 重构一个新的 Model 模型,fine-tuning 比较好用
3.5 模型概况查询、保存及载入
1、模型概括打印
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_7 (Conv2D) (None, 28, 28, 6) 60
_________________________________________________________________
max_pooling2d_7 (MaxPooling2 (None, 14, 14, 6) 0
_________________________________________________________________
conv2d_8 (Conv2D) (None, 10, 10, 16) 2416
_________________________________________________________________
max_pooling2d_8 (MaxPooling2 (None, 5, 5, 16) 0
_________________________________________________________________
flatten_4 (Flatten) (None, 400) 0
_________________________________________________________________
dense_34 (Dense) (None, 120) 48120
_________________________________________________________________
dense_35 (Dense) (None, 84) 10164
_________________________________________________________________
dense_36 (Dense) (None, 10) 850
=================================================================
Total params: 61,610
Trainable params: 61,610
Non-trainable params: 0
_________________________________________________________________
2、权重获取
model.get_layer(\'conv2d_7\' ) # 依据层名或下标获得层对象
<keras.layers.convolutional.Conv2D at 0x1ed425bce10>
weights = model.get_weights() #返回模型权重张量的列表,类型为 numpy array
model.set_weights(weights) #从 numpy array 里将权重载入给模型,要求数组具有与 model.get_weights() 相同的形状。
# 查看 model 中 Layer 的信息
model.layers
[<keras.layers.convolutional.Conv2D at 0x1ed425bce10>,
<keras.layers.pooling.MaxPooling2D at 0x1ed4267a4a8>,
<keras.layers.convolutional.Conv2D at 0x1ed4267a898>,
<keras.layers.pooling.MaxPooling2D at 0x1ed4266bb00>,
<keras.layers.core.Flatten at 0x1ed4267ebe0>,
<keras.layers.core.Dense at 0x1ed426774a8>,
<keras.layers.core.Dense at 0x1ed42684940>,
<keras.layers.core.Dense at 0x1ed4268edd8>]
3.6 模型保存与加载
引用:keras如何保存模型
-
使用
model.save(filepath)将 Keras 模型和权重保存在一个 HDF5 文件中,该文件将包含:- 模型的结构(以便重构该模型)
- 模型的权重
- 训练配置(损失函数,优化器等)
- 优化器的状态(以便于从上次训练中断的地方开始)
-
使用
keras.models.load_model(filepath)来重新实例化你的模型,如果文件中存储了训练配置的话,该函数还会同时完成模型的编译
# 将模型权重保存到指定路径,文件类型是HDF5(后缀是.h5)
filepath = \'E:/Graphs/Models/lenet.h5\'
model.save_weights(filepath)
# 从 HDF5 文件中加载权重到当前模型中, 默认情况下模型的结构将保持不变。
# 如果想将权重载入不同的模型(有些层相同)中,则设置 by_name=True,只有名字匹配的层才会载入权重
model.load_weights(filepath, by_name=False)
json_string = model.to_json() # 等价于 json_string = model.get_config()
open(\'E:/Graphs/Models/lenet.json\',\'w\').write(json_string)
model.save_weights(\'E:/Graphs/Models/lenet_weights.h5\')
#加载模型数据和weights
model = model_from_json(open(\'E:/Graphs/Models/lenet.json\').read())
model.load_weights(\'E:/Graphs/Models/lenet_weights.h5\')
3.6.1 只保存模型结构,而不包含其权重或配置信息
- 保存成
json格式的文件
# save as JSON
json_string = model.to_json()
open(\'E:/Graphs/Models/my_model_architecture.json\',\'w\').write(json_string)
from keras.models import model_from_json
model = model_from_json(open(\'E:/Graphs/Models/my_model_architecture.json\').read())
- 保存成
yaml文件
# save as YAML
yaml_string = model.to_yaml()
open(\'E:/Graphs/Models/my_model_architectrue.yaml\',\'w\').write(yaml_string)
from keras.models import model_from_yaml
model = model_from_yaml(open(\'E:/Graphs/Models/my_model_architectrue.yaml\').read())
这些操作将把模型序列化为json或yaml文件,这些文件对人而言也是友好的,如果需要的话你甚至可以手动打开这些文件并进行编辑。当然,你也可以从保存好的json文件或yaml文件中载入模型
3.6.2 实时保存模型结构、训练出来的权重、及优化器状态并调用
keras 的 callback 参数可以帮助我们实现在训练过程中的适当时机被调用。实现实时保存训练模型以及训练参数
keras.callbacks.ModelCheckpoint(
filepath,
monitor=\'val_loss\',
verbose=0,
save_best_only=False,
save_weights_only=False,
mode=\'auto\',
period=1
)
filename:字符串,保存模型的路径monitor:需要监视的值- verbose:信息展示模式,
0或1 - save_best_only:当设置为True时,将只保存在验证集上性能最好的模型
- mode:‘auto’,‘min’,‘max’之一,在save_best_only=True时决定性能最佳模型的评判准则,例如,当监测值为val_acc时,模式应为max,当检测值为val_loss时,模式应为min。在auto模式下,评价准则由被监测值的名字自动推断。
- save_weights_only:若设置为True,则只保存模型权重,否则将保存整个模型(包括模型结构,配置信息等)
- period:CheckPoint之间的间隔的epoch数
3.6.3 示例
假如原模型为:
x=np.array([[0,1,0],[0,0,1],[1,3,2],[3,2,1]])
y=np.array([0,0,1,1]).T
model=Sequential()
model.add(Dense(5,input_shape=(x.shape[1],),activation=\'relu\', name=\'layer1\'))
model.add(Dense(4,activation=\'relu\',name=\'layer2\'))
model.add(Dense(1,activation=\'sigmoid\',name=\'layer3\'))
model.compile(optimizer=\'sgd\',loss=\'mean_squared_error\')
model.fit(x,y,epochs=200, verbose= 0) # 训练
model.save_weights(\'E:/Graphs/Models/my_weights.h5\')
model.predict(x[0:1]) # 预测
array([[ 0.38783705]], dtype=float32)
# 新模型
model = Sequential()
model.add(Dense(2, input_dim=3, name="layer_1")) # will be loaded
model.add(Dense(10, name="new_dense")) # will not be loaded
# load weights from first model; will only affect the first layer, dense_1.
model.load_weights(\'E:/Graphs/Models/my_weights.h5\', by_name=True)
model.predict(x[1:2])
array([[-0.27631092, -0.35040742, -0.2807056 , -0.22762418, -0.31791407,
-0.0897391 , 0.02615392, -0.15040982, 0.19909057, -0.38647971]], dtype=float32)
3.7 How to Check-Point Deep Learning Models in Keras
# Checkpoint the weights when validation accuracy improves
from keras.models import Sequential
from keras.layers import Dense
from keras.callbacks import ModelCheckpoint
import matplotlib.pyplot as plt
import numpy as np
x=np.array([[0,1,0],[0,0,1],[1,3,2],[3,2,1]])
y=np.array([0,0,1,1]).T
model=Sequential()
model.add(Dense(5,input_shape=(x.shape[1],),activation=\'relu\', name=\'layer1\'))
model.add(Dense(4,activation=\'relu\',name=\'layer2\'))
model.add(Dense(1,activation=\'sigmoid\',name=\'layer3\'))
# Compile model
model.compile(loss=\'binary_crossentropy\', optimizer=\'adam\', metrics=[\'accuracy\'])
filepath="E:/Graphs/Models/weights-improvement-{epoch:02d}-{val_acc:.2f}.hdf5"
checkpoint = ModelCheckpoint(filepath, monitor=\'val_acc\', verbose=1, save_best_only=True, mode=\'max\')
callbacks_list = [checkpoint]
# Fit the model
model.fit(x, y, validation_split=0.33, epochs=150, batch_size=10, callbacks=callbacks_list, verbose=0)
Epoch 00000: val_acc improved from -inf to 1.00000, saving model to E:/Graphs/Models/weights-improvement-00-1.00.hdf5
Epoch 00001: val_acc did not improve
Epoch 00002: val_acc did not improve
Epoch 00003: val_acc did not improve
Epoch 00004: val_acc did not improve
Epoch 00005: val_acc did not improve
Epoch 00006: val_acc did not improve
Epoch 00007: val_acc did not improve
Epoch 00008: val_acc did not improve
Epoch 00009: val_acc did not improve
Epoch 00010: val_acc did not improve
Epoch 00011: val_acc did not improve
Epoch 00012: val_acc did not improve
Epoch 00013: val_acc did not improve
Epoch 00014: val_acc did not improve
Epoch 00015: val_acc did not improve
Epoch 00016: val_acc did not improve
Epoch 00017: val_acc did not improve
Epoch 00018: val_acc did not improve
Epoch 00019: val_acc did not improve
Epoch 00020: val_acc did not improve
Epoch 00021: val_acc did not improve
Epoch 00022: val_acc did not improve
Epoch 00023: val_acc did not improve
Epoch 00024: val_acc did not improve
Epoch 00025: val_acc did not improve
Epoch 00026: val_acc did not improve
Epoch 00027: val_acc did not improve
Epoch 00028: val_acc did not improve
Epoch 00029: val_acc did not improve
Epoch 00030: val_acc did not improve
Epoch 00031: val_acc did not improve
Epoch 00032: val_acc did not improve
Epoch 00033: val_acc did not improve
Epoch 00034: val_acc did not improve
Ep以上是关于Keras 学习之旅的主要内容,如果未能解决你的问题,请参考以下文章
我的C语言学习进阶之旅解决 Visual Studio 2019 报错:错误 C4996 ‘fscanf‘: This function or variable may be unsafe.(代码片段
我的C语言学习进阶之旅解决 Visual Studio 2019 报错:错误 C4996 ‘fscanf‘: This function or variable may be unsafe.(代码片段
我的OpenGL学习进阶之旅NDK开发中find_library查找的系统动态库在哪里?
我的OpenGL学习进阶之旅NDK开发中find_library查找的系统动态库在哪里?
Unity Shader入门精要学习笔记 - 第5章 开始 Unity Shader 学习之旅
我的Android进阶之旅NDK开发之在C++代码中使用Android Log打印日志,打印出C++的函数耗时以及代码片段耗时详情