合并流以及已知文件流长度和未知文件长度的文件流读取方法
Posted 我心自在
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了合并流以及已知文件流长度和未知文件长度的文件流读取方法相关的知识,希望对你有一定的参考价值。
项目中有一个这样的需求,上传文件的时候需要多张文件一起上传,而且每张文件都有自己的文件信息,因为文件信息需要匹配验证,在处理过程中需要传输流的时候前半段固定长度为文件信息,后半段是文件流,而且还是多张批量的情况,经过不断摸索最终想出一个方案:那就是采用合并流,示意图如下:
批次信息[256]+文件信息流1[1024]+文件流1+文件信息流2[1024]+文件流2+文件信息流3[1024]+文件流3…….
前面256是固定长度的一个流,里面是文件数量等信息,文件批量上传的时候就可以根据文件数量来循环文件的个数了。
当然,1024固定长度信息中必须包含每个文件的大小(字节数),如果不知道大小的话,下一个循环的时候就会出现错误。
合并流介绍
合并流,顾名思义,就是将多个流合并到一起形成一个完整的流,然后再根据需要截取需要的信息,原理很简单,下面是API:
private static SequenceInputStream getSequenceStream(String fileInfoString,String filePath){ FileInputStream fs=null; ByteArrayInputStream bais=null; SequenceInputStream sis=null; try { //文件信息流 byte[] b = fileInfoString.getBytes(); byte[] info = Arrays.copyOf(b,1024); bais=new ByteArrayInputStream(info); //文件流 File file=new File(filePath); fs=new FileInputStream(file); //合并流 sis=new SequenceInputStream(bais,fs); } catch (FileNotFoundException e) { e.printStackTrace(); } return sis; }
上面代码就是合并流的过程,非常简单,我们可以根据固定的1024长度得到文件信息,这个长度的设置可以根据实际需求来调整,或者是直接利用String类的length方法获取,没有固定的值。利用这个原理,我们就可以将多个文件合并成一个流传到我们需要的地方了,我们这个项目是吧文件写入大数据平台根据文件的具体大小存入Hbase或者HDFS。
合并流搞定之后,接下来我们就是截取合并流了,这里就出现了一个问题,文件信息我们可以根据前面的固定长度截取读出来进行解析,因为他是转化String类型很容易,但是文件流呢,虽然我们知道他的大小,但是如何快速的把他读出来并写入磁盘呢?
第一种方案:直接读写
这种方案就是我们根据文件信息中告诉我们的流大小,然后开辟相应的缓冲区,把它一次性的写入我们的磁盘,下面是代码:
private byte [] getBytes(BufferedInputStream bis,long fileSize){ byte[] buffer=null; try { ByteArrayOutputStream bos=new ByteArrayOutputStream(); int count=(int)fileSize; int readCount=0;//已经成功读取的字节 int len=0; byte []buf=new byte[count]; // buf=new byte[count]; logger.info("Hbase可读文件大小:"+count); while(readCount<count){ len=bis.read(buf, readCount, count-readCount); readCount+=len; } bos.write(buf); bos.flush(); buffer = bos.toByteArray(); bos.close(); } catch (IOException e) { e.fillInStackTrace(); } return buffer; }
测试效果:
经过测试,这种方案是可行的,但是我们做的是大数据的项目,客户对效率的要求非常高,从压力测试来看效率非常低,另外,如果文件很大的话,这样的buffer开辟的区域会占用很大的内存,所以这种方案,虽然功能上可行,但是不可取,没有效率。下面是测试效果:
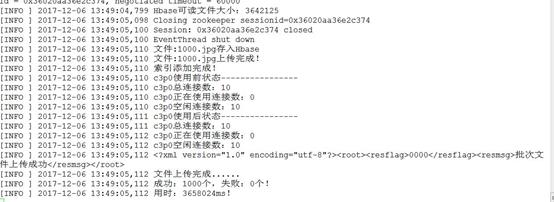
这种方案功能可行,但是效率不行,问题的根源就在于读流的方法没有效率,没有发挥出read方法的功效,而且开辟的缓冲区根据文件的大小而不同,如果一个批次文件太多的话,很容易把内存占满,发生内存溢出。
第二种方案:循环读写
这种方案是前一种方案的改进,我们根据文件大小利用循环读完固定长度的流,首先解释一下为什么要这样写while循环,要从read这个方法说起,从源码分析来看,read这个方法一次性本来就不可已读完整个流的,所以为了保证所有的流都读完,只能这样写。下面是方法:
//--------------------------改进的方法----------------------------- private byte [] getBytess(BufferedInputStream bis,long fileSize){ byte[] buffer=null; try { ByteArrayOutputStream bos=new ByteArrayOutputStream(); int count=(int)fileSize; int readCount=0;//已经成功读取的字节 int len=0; byte []buf=new byte[4096];
while( count>0){ len=bis.read(buf,0,count); bos.write(buf); count-=len; } bos.flush(); buffer = bos.toByteArray(); bos.close(); return buffer; } catch (IOException e) { e.fillInStackTrace(); } return buffer; }
这样的尝试貌似可行,但是在测试的过程中又出现问题了,这种方案流是能读完,但是偶尔会读多,为什么呢?问题出现在while循环里,因为最后一次的循环可能不是文件剩下的那么多,比如1028个字节的流,它第一次会读1024,第二次读的就不是剩下的8个字节了,而且还是1024,原因就在于read这个方法,除非到-1他能读完,但是我们又不能读到-1,所以这种方法还需要改进,其实很简单,加判断就可以了,下面是改进的方法:
private byte [] getBytes(BufferedInputStream bis,long fileSize) throws IOException{ byte[] buffer=null; ByteArrayOutputStream bos=null; bos=new ByteArrayOutputStream(); int count=(int)fileSize; int len=0; byte []buf=new byte[4096]; while(count>0){ if(count<buf.length){ len=bis.read(buf,0,count); }else{ len=bis.read(buf); } bos.write(buf,0,len); count-=len; } bos.flush(); buffer = bos.toByteArray(); bos.close(); return buffer; }
经过测试后这种方法不仅可行而且对效率也没有影响。
测试效果:

从效果来看,效率提升了不止一倍。最后附上一次性读完流的代码,这种方式可以把整个流读完。
private byte [] getBytes(BufferedInputStream bis) throws IOException{ byte[] buffer=null; ByteArrayOutputStream bos=null; bos=new ByteArrayOutputStream(); int len=0; byte []buf=new byte[1024]; while((len=bis.read(buf))!=-1){ bos.write(buf, 0, len); } bos.flush(); buffer=bos.toByteArray(); bos.close(); return buffer; }
以上是关于合并流以及已知文件流长度和未知文件长度的文件流读取方法的主要内容,如果未能解决你的问题,请参考以下文章