hashCode花式卖萌
Posted Qcer
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hashCode花式卖萌相关的知识,希望对你有一定的参考价值。
声明:这篇博文纯属是最近看源码时闲着没事瞎折腾(好奇心驱动),对实际的应用程序编码我觉得可能没有那么大的帮助,各位亲就当是代码写累了放松放松心情,视为偏门小故事看一看就可以了,别深究。
一、从Object和System谈起
首先是Object类中的hashCode()方法:
public native int hashCode();
native修饰的方法。但是根据文档的描述,我们知道这个int类型的hashCode是根据对象的地址转换而来的。
引文:
As much as is reasonably practical, the hashCode method defined by class Object does return distinct integers for distinct objects. (This is typically implemented by converting the internal address of the object into an integer, but this implementation technique is not required by the Java™ programming language.)。
然后是System类的静态方法:identityHashCode(Object x)
public static native int identityHashCode(Object x);
不出所料,也是native方法。这个方法返回的结果也是根据对象的地址转换而来的,与Object的实例调用hashCode()返回的结果一样(前提是hashCode()方法未被子类重写)。
但是还是有点小差别,就是在处理null值的时候:
System.identityHashCode(null)会返回0,而指向null的Object对象调用hashCode()显然会出现NPE异常。
package com.prac; public class Obj { public static void main(String[] args) { Obj obj = null; // System.out.println(obj.hashCode());//NPE异常 System.out.println(System.identityHashCode(null));//0 } }
另外,由于数组木有重写Object的hashCode()方法,因此任何数组对象调用hashCode()方法得到的都是基于对象地址计算出来的值,也即是与System.identityHashCode()方式调用返回的结果一样。
实验一下:
int[] ary = new int[10]; System.out.println(ary.hashCode()); System.out.println(System.identityHashCode(ary));
输出:
778966024 778966024
以上根据对象地址来计算hashCode值是比较"原始简单粗暴"的策略。一个对象本身的内容(属性数据)改变后,其hashCode仍然不会变,例如下面这个例子。在很多实际应用场景中,这可能不是一个很好的策略。姑且将这种策略称之为“base on address”,实际上这与后面要介绍的“base on content”形成一个比对效果。
ArrayList<Integer> list = new ArrayList<Integer>(); list.add(1); System.out.println(System.identityHashCode(list));//1794515827 list.add(2); System.out.println(System.identityHashCode(list));//1794515827,与改变前的hashCode一样,因为对象地址没变
二、邂逅基本包装类型
2.1、Integer类型的hashCode实现
Integer当然也重写了其间接父类Object的hashCode()方法,在JDK1.8以前,是直接返回Integer对象的数值value,JDK1.8中增加了一个静态方法,通过调用静态方法也是直接返回对象的数值value。
@Override
public int hashCode() {
return Integer.hashCode(value);
}
/**
* @since 1.8
*/
public static int hashCode(int value) {
return value;
}
2.2、Long类型的hashCode实现
Long是将其值进行无符号右移32位的结果在与其本身做异或运算,最后返回一个int值,嗯,好像有点意思!
@Override
public int hashCode() {
return Long.hashCode(value);
}
/**
* @since 1.8
*/
public static int hashCode(long value) {
return (int)(value ^ (value >>> 32));
}
3.2、Character、Short和Byte
Character类型、Short类型和Byte类型基本是采用相同的方式,都是将char、short或者byte类型向上转型为int类型,就直接返回了,不一一列举。
以Character为例:
@Override
public int hashCode() {
return Character.hashCode(value);
}
/**
* @since 1.8
*/
public static int hashCode(char value) {
return (int)value;
}
3.3、Float和Double的hashCode实现
这两个类型的实现大致比较类似,但是稍微有点不好理解。
这里以Float为例,Float类(>=JDK1.8)中求解hashCode过程中分别调用了如下的方法。
@Override
public int hashCode() {
return Float.hashCode(value);
}
/**
* @since 1.8
*/
public static int hashCode(float value) {
return floatToIntBits(value);
}
public static int floatToIntBits(float value) {
int result = floatToRawIntBits(value);
// Check for NaN based on values of bit fields, maximum
// exponent and nonzero significand.
if ( ((result & FloatConsts.EXP_BIT_MASK) ==
FloatConsts.EXP_BIT_MASK) &&
(result & FloatConsts.SIGNIF_BIT_MASK) != 0)
result = 0x7fc00000;
return result;
}
public static native int floatToRawIntBits(float value);
可见最终是调用floatToRawIntBits()方法,有点意思!
这个floatToRawIntBits()方法的官方注解是:
Returns a representation of the specified floating-point value according to the IEEE 754 floating-point "single format" bit layout, preserving Not-a-Number (NaN) values.
我个人理解就是将该浮点数在IEEE 754标准下的二进制位表示直接当成int类型的二进制位来解释,也就是忽略掉IEEE 754标准的约定规则。API的方法命名floatToIntBits也大概是想表达这个语义吧。
IEEE 754标准表示32位浮点数格式分三部分:数符S(第31位),阶码E(第23位-30位共8位)和尾数M(剩下的23位)。
具体的求解过程举个栗子:
还是以经典的浮点数Float valuef = 100.25f为例,IEEE 754标准表示过程如下:

32位的二进制:0100 0010 1100 1000 1000 0000 0000 0000本来是根据IEEE 754标准表示的结果,但是计算hashCode时直接将这个二进制数按照int类型来解释就是1120436224。
所以valuef 的hashCode应该是1120436224。
实验一下:
Float valuef = 100.25f;
System.out.println("hashCode = "+valuef.hashCode());
System.out.println("floatToIntBits = "+Float.floatToIntBits(valuef));
System.out.println("floatToRawIntBits = "+Float.floatToRawIntBits(valuef));
System.out.println("0x42C88000->decimal = "+Integer.parseInt("0x42C88000".substring(2),16));
System.out.println(Float.toHexString(new Float(100.25f)));
输出:
hashCode = 1120436224
floatToIntBits = 1120436224
floatToRawIntBits = 1120436224
0x42C88000->decimal = 1120436224
0x1.91p6
Double类求hashCode与Float原理是类似的。
3.4、Boolean类型的hashCode实现
Boolean类型的hashCode最搞笑了,根据Boolean对象的值进行二者其选一:true->1231,false->1237。为什么程序的实现者会选择这两个值作为其hashCode呢,有什么故事吗?不造也!或者就是作者个人癖好?
@Override
public int hashCode() {
return Boolean.hashCode(value);
}
/**
* @since 1.8
*/
public static int hashCode(boolean value) {
return value ? 1231 : 1237;
}
三、拐角遇见String类
String类重写了父类Object的hashCode()方法:
/** *=================================================================== * String当然是重写了Object的hashCode()方法 * hashCode的生成逻辑:s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1] * 空字符串的hashCode是0 *================================================================== */ public int hashCode() { int h = hash; if (h == 0 && value.length > 0) { char val[] = value; for (int i = 0; i < value.length; i++) { h = 31 * h + val[i]; } hash = h; } return h; }
如果从数学角度来直观的展现这个求解过程,大概是下面这样的:

化简一下求解过程也很简单:将前面n-1个等式的左右两边依次乘上31^(n-1)、31^(n-1)...31^2、31,再左右累加就可以错位相消。n次迭代后,hashCode计算由如下公式的给出:
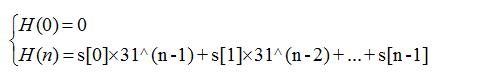
当然这里的hashCode很有可能因为大于-1>>>1而溢出返回一个负数。
素数31在后面的其他hashCode方法中都很常见,似乎是一个所谓的“梅森素数”,没研究过,选31也可能是考虑用移位运算(1<<5)-1比较快吧。
四、眼看他起朱楼
有了以上的String和8种基本包装类型的hashCode实现,其他类的hashCode基本上就是在其前面的基础上做扩展,做迭代。
比如:工具类Arrays中,求一个long类型的数组的hashCode,就是将每个元素值的hashCode按照规则进行n次迭代,其源码如下:
public static int hashCode(long a[]) { if (a == null) return 0; int result = 1; for (long element : a) { int elementHash = (int)(element ^ (element >>> 32)); result = 31 * result + elementHash; } return result; }
Arrays类针对不同的参数(byte[],int[],long[]等等)重载了很多hashCode()方法,基本都是按照此思路来迭代求解hashCode值的。
这些迭代可以有一个通用公式:
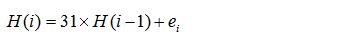
实际上,“将每个元素值的hashCode按照规则进行n次迭代”这样的实现有一定的考究。Arrays中的这些方法都遵循一个所谓的“based on the contents”的原则,即这个返回的hashCdoe只与数组中的元素本身有关,跟这个数组对象的地址无关。
举个栗子很容易验证:
int[] aryA = {1,2,3}; int[] aryB = {1,2,3}; System.out.println("AryA ?= AryB : "+(aryA == aryB)); System.out.println(Arrays.hashCode(aryA));//30817 System.out.println(Arrays.hashCode(aryB));//30817,aryA和aryB显然是两个不同的对象,但是它们的"内容"相同
输出:
AryA ?= AryB : false
30817
30817
另外,针对对象数组,Arrays中提供两个方法来求解其hashCode:hashCode(Object a[])和deepHashCode(Object a[])
第一个方法可以理解为只做到了一层“基于内容”(based on the contents)的调用,当对象数组中的元素还是一个数组时(也即多维数组),第二层实际上是根据数组对象地址来生成hashCode,这多少有点违背了“based on the contents”原则。这个层面来讲,这是种“浅迭代”的方式。
想要严格的实现“基于内容”,可以通过第二个方法deepHashCode(Object a[]),该方法在每一层迭代时会对每一个元素进行类型校验,以确保该元素都是基本类型的数组,如果不是,就继续递归下去。这样真正做到了“based on the contents”。
public static int hashCode(Object a[]) { if (a == null) return 0; int result = 1; for (Object element : a) result = 31 * result + (element == null ? 0 : element.hashCode()); return result; } public static int deepHashCode(Object a[]) { if (a == null) return 0; int result = 1; for (Object element : a) { int elementHash = 0; if (element instanceof Object[]) elementHash = deepHashCode((Object[]) element); else if (element instanceof byte[]) elementHash = hashCode((byte[]) element); else if (element instanceof short[]) elementHash = hashCode((short[]) element); else if (element instanceof int[]) elementHash = hashCode((int[]) element); else if (element instanceof long[]) elementHash = hashCode((long[]) element); else if (element instanceof char[]) elementHash = hashCode((char[]) element); else if (element instanceof float[]) elementHash = hashCode((float[]) element); else if (element instanceof double[]) elementHash = hashCode((double[]) element); else if (element instanceof boolean[]) elementHash = hashCode((boolean[]) element); else if (element != null) elementHash = element.hashCode(); result = 31 * result + elementHash; } return result; }
其他的像Objects类(Object的工具类,也是null值兼容的),以及集合对象(在它们的抽象父类:AbstractList,AbstractMap,AbstractSet等中实现了hashCode()方法)大致都是按照Arrays中的实现思路来实现的,而且也都遵循"based on the contents"这一基本原则。
int[] aryA = {1,2,3}; ArrayList<Integer> list = new ArrayList<Integer>(); list.add(1); list.add(2); list.add(3); System.out.println(Arrays.hashCode(aryA));//30817 System.out.println(list.hashCode());//30817
五、结局了,散了吧
大结局了,还是简单看看一下HashMap中的hashCode实现,本来HashMap没有什么特殊性的。
准确的说这里说的是HashMap中的节点元素Node的hashCode实现。
因为HashMap内部实际上是用了一个Node<K,V>类型的数组来存储HashMap对象的有效数据,Node对象中分别有四个属性:hash,kye,value以及指向下一个Node对象的next。大致可以用如下图这样来理解:
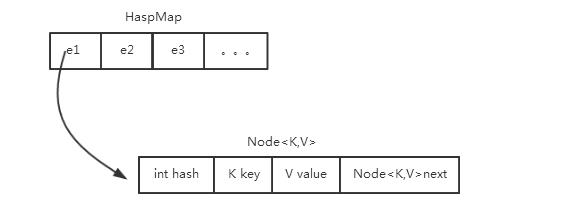
其内部类Node的hashCode()实现:
static class Node<K,V> implements Map.Entry<K,V> { final int hash; final K key; V value; Node<K,V> next; //其他如构造器,getter方法略掉 public final int hashCode() { return Objects.hashCode(key) ^ Objects.hashCode(value); } //其他方法略掉 }
这个hashCode实现有点欲言又止,在源码中似乎没有看到这个Node的hashCode()方法的调用?
在JDK1.8中的HashMap对象调用put方法中hash值是采用如下方式生成:
static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }
所以HashMap的hash值也是站在前面的肩膀上的。
全剧终!
从此hashCode和程序员过上了幸福美满的生活!
以上是关于hashCode花式卖萌的主要内容,如果未能解决你的问题,请参考以下文章