《数据库系统概念》15-可扩展动态散列
Posted zhixin9001
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《数据库系统概念》15-可扩展动态散列相关的知识,希望对你有一定的参考价值。
静态散列要求桶的数目始终固定,那么在确定桶数目和选择散列函数时,如果桶数目过小,随着数据量增加,性能会降低;如果留一定余量,又会带来空间的浪费;或者定期重组散列索引结构,但这是一项开销大且耗时的工作。为了应对这些问题,为此提出了几种动态散列(dynamic hashing)技术,可扩展动态散列(extendable hashing)便是其一。
一、可扩展动态散列

A)用一个数组来存储桶指针的目录,数组的位数为2的D次方,桶的容量为2的L次方,D和L分别称为全局位深度和局部位深度。每次发生桶溢出时,溢出桶分裂,容量变为2的L+1次方,其它桶的容量保持不变,同时数据目录的深度变为D+1。扩展容量时,只是调整了局部的桶容量和目录的容量,性能开销比较小。
上图中,目录深度为2,目录项有4个。然后开始插入数据d1和d2,假定h(d1)=13、h(d2)=20,由于13=1101,且全局位深度为2,则根据后两位01确定应插入b桶,b桶有空间,可直接插入。20=10100,应插入a桶,但a桶以及满了,于是开始分裂,a桶的局部位深度变为3,容量扩展为8,如果扩展后的局部位深度超过了全局位深度,则全局位深度等于这个最大的局部位深度,于是全局位深度也随之变为3。
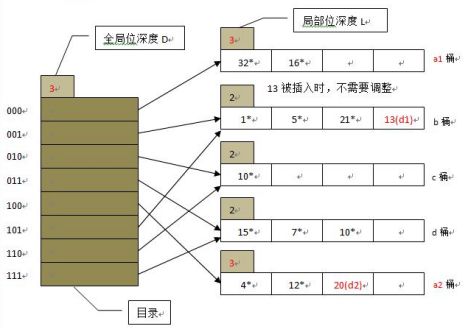
如上图所示,a桶分裂为a1、a2,目录变为三位,对原来a桶中的元素进行重组,由于目录位多了一位,要根据000、100来分别存储到a1、a2桶。虽然目录发生了翻倍,但未进行分裂的桶的局部深度仍然为2,所以会有多个目录项指向这些桶,比如001、101的后两位都是01,都指向b桶。
B)对于查找操作,根据当前的全局位深度,通过目录直接定位到桶地址,随后在桶内部逐一查找。
C)对于删除操作,与查找操作类似,删除元素后,如果发现桶变为空,可与其兄弟桶进行合并,并使局部位深度减一。如果所有的局部位深度都小于全局位深度,则目录数组也进行收缩。
二、静态散列与动态散列对比
与静态散列相比,动态散列的主要优势在于其性能不会随着记录数增长而下降,另外还具有最小的空间占用。缺点在于它会额外增加一次查询定位,因为在查询bucket本身前,需要先查找目录来定位bucket。
另一种动态散列技术-线性散列(linear hashing)可以避免额外的查询定位,但可能这种方式需要更多的溢出桶,日后学习。
三、顺序索引与散列的适用场景
每种索引结构都有其优缺点。如果是select
* from a where
b=c这样的定值查询,散列比顺序索引跟适合,顺序索引会随着记录数的增加而性能降低,散列则相对稳定。而对于where b>c and
b<d这样的范围搜索,则顺序索引更适合,散列的随机特性使得无法定位搜索的bucket。所以散列只适合根据搜索码搜索且不是范围查询的场合。
学习资料:Database System Concepts, by Abraham Silberschatz, Henry F.Korth, S.Sudarshan
https://www.cnblogs.com/kegeyang/archive/2012/04/05/2432608.html
以上是关于《数据库系统概念》15-可扩展动态散列的主要内容,如果未能解决你的问题,请参考以下文章