顾名思义,物化节点是一类可缓存元组的节点。在执行过程中,很多扩展的物理操作符需要首先获取所有的元组后才能进行操作(例如聚集函数操作、没有索引辅助的排序等),这时要用物化节点将元组缓存起来。下面列出了PostgreSQL中提供的物化节点。
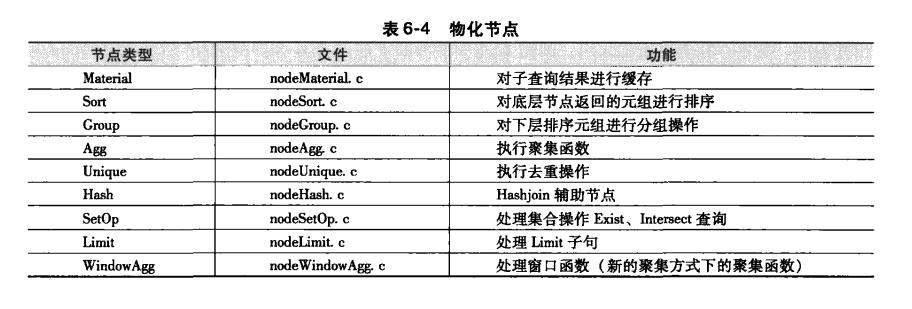
物化节点概述
物化节点需要有元组的缓存结构,以加快执行效率或实现特定功能(例如排序等)。物化节点的功能种类多样,实现过程也不尽相同,缓存的方式也有所不同,主要使用了 tuplestore来进行缓存。tuplestore使用Tuplestorestate数据结构
//src/backend/utils/sort/tuplestore.c
/*
* Private state of a Tuplestore operation.
*/
struct Tuplestorestate
{
TupStoreStatus status; /* enumerated value as shown above */
...
BufFile *myfile; /* underlying file, or NULL if none */
...
void *(*copytup) (Tuplestorestate *state, void *tup);
void (*writetup) (Tuplestorestate *state, void *tup);
void *(*readtup) (Tuplestorestate *state, unsigned int len);
void **memtuples; /* array of pointers to palloc\'d tuples */
...
};
来存储相关信息和数据,以上列举了比较重要的字段。status表明了Tuplestore操作期间的状态(保持在内存等待处理;读;写)。memtuples字段指定了一块内存区域用于缓存数据,而当内存中缓存的元组达到一定的数量时会将元组写人myfile字段指定的临时文件。一些函数指针指向了针对该缓存元组的操作函数,浓浓的面向对象的味道。
tuplestore 通过 tuplestore_begin_heap 来构造和初始化,通过 tuplestore_end 进行释放。tuplestore_puttuple函数用于将加人到tuplestore,而tuplestore_gettuple函数则可以从tuplestore中获取元组。
以上可以说是物化节点的基础模板操作流程,几乎所有的物化节点都遵循这一操作流程。下面要说的Sort节点也不例外。
Sort节点
Sort节点(排序节点)用于对于下层节点的输出结果进行排序,该节点只有左子节点。排序节点先将下层节点返回的所有元组缓存起来,然后进行排序。由于缓存结果可能很多,因此不可避免地会用到临时文件进行存储,这种情况下Sort节点将使用外排序方法。
Sort节点的定义如下所示,
typedef struct Sort
{
Plan plan;
int numCols; /* number of sort-key columns */
AttrNumber *sortColIdx; /* their indexes in the target list */
Oid *sortOperators; /* OIDs of operators to sort them by */
Oid *collations; /* OIDs of collations */
bool *nullsFirst; /* NULLS FIRST/LAST directions */
} Sort;
其中保存了进行排序的属性个数(mumCols)、用于排序的属性的厲性号数组(sortcolIdx,长度为numCols)和用于每个排序属性的排序操作符OID数组(sortOperators,长度也为numCols)。另外,Sort节点用一个布尔类型的宇段millsFirst记录是否将空值排在前面。
由于Sort节点仅对元组进行排序,不需要做投影和选择操作,因此在Sort节点的初始化过程(ExecInitSort函数)中不会对Plan结构中的投影(targetlist)和选择(qual)链表进行初始化,只需构造SortState节点并调用下层节点的初始化过程。
typedef struct SortState
{
ScanState ss; /* its first field is NodeTag */
bool randomAccess; /* need random access to sort output? */
bool bounded; /* is the result set bounded? */
int64 bound; /* if bounded, how many tuples are needed */
bool sort_Done; /* sort completed yet? */
bool bounded_Done; /* value of bounded we did the sort with */
int64 bound_Done; /* value of bound we did the sort with */
void *tuplesortstate; /* private state of tuplesort.c */
int eflags; /* node\'s capability flags to use sortadaptor */
} SortState;
在SortState中,比较重要的是tuplesortstate字段。在tuplestore的基础之上,PostgreSQL提供了 tuplesortstore (由数据结构Tuplesortstate实现),它在tuplestore内增加了排序功能:当获取所有的元组后,可对元组进行排序。如果没有使用临时文件,则使用快速排序,否则将使用归并法进行外排序。
而其中LogicalTapeSet类型的字段则提供了在外部排序时的排序文件的功能(类似于Tuplestorestate中的BufFile字段)。
下面老规矩,对着代码我们细说。
首先,Sort节点的执行入口是:
TupleTableSlot *
ExecSort(SortState *node)
它被上层的ExecProcNode函数调用,输出元组。
在ExecSort函数的首次调用中会首先通过tuplesort_begin_heap对元组缓存结构初始化,返回一个Tuplesortstate结构。
Tuplesortstate *
tuplesort_begin_heap(TupleDesc tupDesc,
int nkeys, AttrNumber *attNums,
Oid *sortOperators, Oid *sortCollations,
bool *nullsFirstFlags,
int workMem, bool randomAccess)
随后针对是否存在limit字段设置返回元组的bound数以及其它的一些flags。
然后循环执行下层节点获取元组,循环执行调用tuplesort_puttupleslot函数。
void
tuplesort_puttupleslot(Tuplesortstate *state, TupleTableSlot *slot)
该函数主要是
- 1.将获得的元组进行拷贝(考虑到内存上下文的问题,必须拷贝而不是引用),
- 2.调用puttuple_common函数进行共通处理。
puttuple_common函数比较微妙,会根据Sort节点所在的状态做不同处理。
其实说白了就是依据当前已输入元组的数量决定排序的方法:
- 1.数据量少到可以整体放到内存的话,就直接快速排序走起;
- 2.数据量较大内存放不下,但是所需要返回的元组内存可以装下或者TOP N的性能比快排好的话,TOP N类型的算法走起(这里是堆排序),;
- 3.数据量很大,并且返回的元组内存也放不下的话,外部归并排序走起。
下面是楼主自己简化理解:
switch (status)
{
case TSS_INITIAL:(这个状态下暂时是快速排序)
读入SortTuple;
满足 if (state->bounded &&
(state->memtupcount > state->bound * 2 ||
(state->memtupcount > state->bound && LACKMEM(state)))):
则switch over to a bounded heapsort(大顶堆)
status = TSS_BOUNDED -->堆排序
if (state->memtupcount < state->memtupsize && !LACKMEM(state))
return;返回, -->快速排序
否则Execute_Tape_sort:
将数据写到tape
status = TSS_BUILDRUNS-->外部归并排序
case TSS_BOUNDED:(这个状态下已经是堆排序)
if new tuple <= top of the heap, so we can discard it
else discard top of heap, sift up, insert new tuple
case TSS_BUILDRUNS:(这个状态下已经是外部归并排序)
Insert the tuple into the heap, with run number currentRun if
it can go into the current run, else run number currentRun+1.
}
获取到下层节点的所有元组之后,调用tuplesort_performsort对缓存元组进行排序(这里就根据status的值来确定使用哪一种排序方法)。
然后输出第一个元组。
第一次调用到此结束。
后续对Sort节点的执行都将直接调用tuplesort_gettupleslot从缓存中返回一个元组。比如说你要返回100个元组,这里就要重复执行1+99(这个1是最开始的第一次)次得到结果。
我们也来看看上层怎么调用的吧。我们假设一个简单的语句和它的查询计划:
postgres=# explain select id,xxx from test order by id ;
QUERY PLAN
----------------------------------------------------------------------
Sort (cost=2904727.34..2929714.96 rows=9995048 width=34)
Sort Key: id
-> Seq Scan on test (cost=0.00..376141.48 rows=9995048 width=34)
(3 行)
查询编译阶段我就不说了,我们直接到查询执行。
这里应该是进入到了standard_ExecutorRun函数:
void
standard_ExecutorRun(QueryDesc *queryDesc,
ScanDirection direction, long count)
这个函数只是一个壳子,根据提供的查询描述符QueryDesc做一些初始化操作,设置好内存上下文之后,把工作交给ExecutePlan函数来做。
ExecutePlan函数也是个壳子,里面包着这个死循环,循环一次就执行一次计划节点。再看上面的查询计划。对应到这里就是首先执行planstate中最上层的Sort节点,而Sort节点又会循环地调用Scan节点来获取元组(上面已经提到)。整体就是一个循环递归的过程。
/*
* Loop until we\'ve processed the proper number of tuples from the plan.
*/
for (;;)
{
/* Reset the per-output-tuple exprcontext */
ResetPerTupleExprContext(estate);
/*
* Execute the plan and obtain a tuple
*/
slot = ExecProcNode(planstate);
/*
* if the tuple is null, then we assume there is nothing more to
* process so we just end the loop...
*/
if (TupIsNull(slot))
break;
...
}
Sort节点的清理过程(ExecEndSort函数)需要调用tuplesort_end对缓存结构进行清理回收,然后调用下层节点的清理过程。
整个查询执行周期里的节点的生死的函数调用栈如下:
初始化
standard_ExecutorStart
---->InitPlan
---->ExecInitNode
---->ExecInitSort
---->ExecInitSeqScan
执行
standard_ExecutorRun
---->ExecutePlan
---->ExecProcNode
---->ExecSort
---->ExecSeqScan
结束
standard_ExecutorEnd
---->ExecEndPlan
---->ExecEndNode
---->ExecEndSort
---->ExecEndSeqScan
强迫症表示一本满足。
tips:调试
postgresql内部给了很多针对性的调试宏和参数,这里记录一下。
在postgresql.conf文件中有一个trace_sort参数可以在日志中打印Sort中的节点的初始化执行和结束信息。
小结
本文讲述了postgresql的sort节点的执行过程,也大致说了下基本节点的执行过程,本质就是上层节点递归地调用下层节点的过程。这次讲的比较粗,由于时间紧迫。
2017快完了,还是要多写写。