K 近邻算法(KNN)与KD 树实现
Posted 随煜而安
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了K 近邻算法(KNN)与KD 树实现相关的知识,希望对你有一定的参考价值。

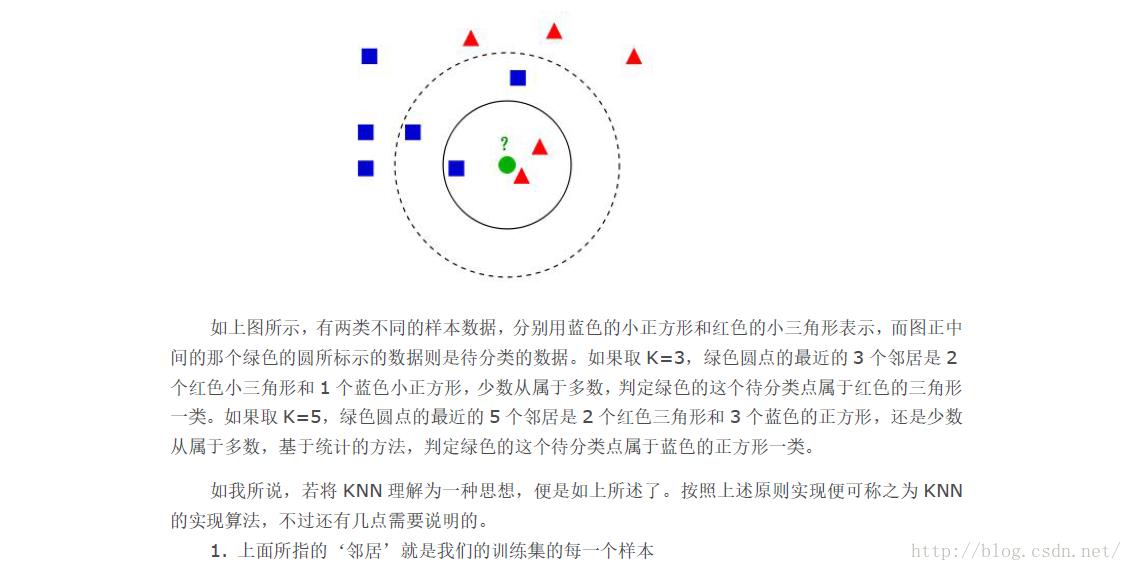






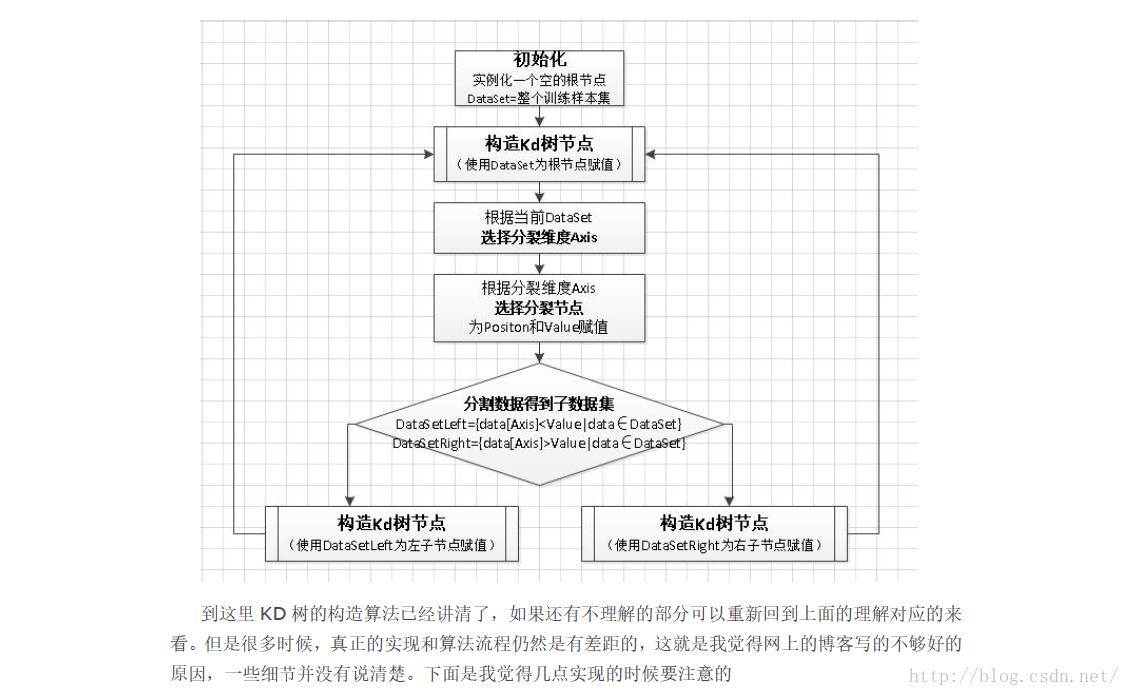



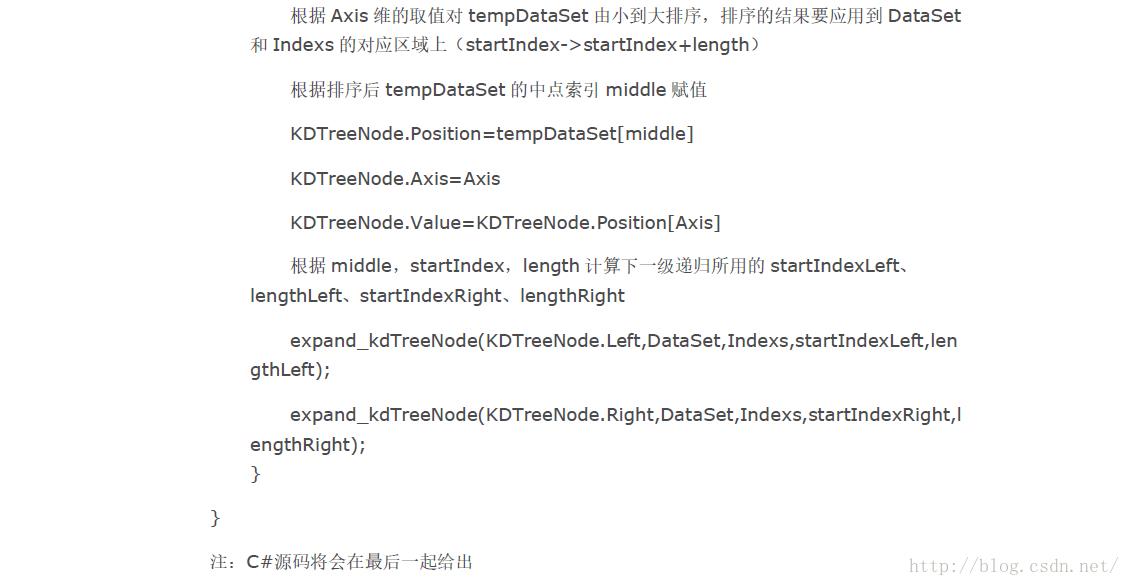
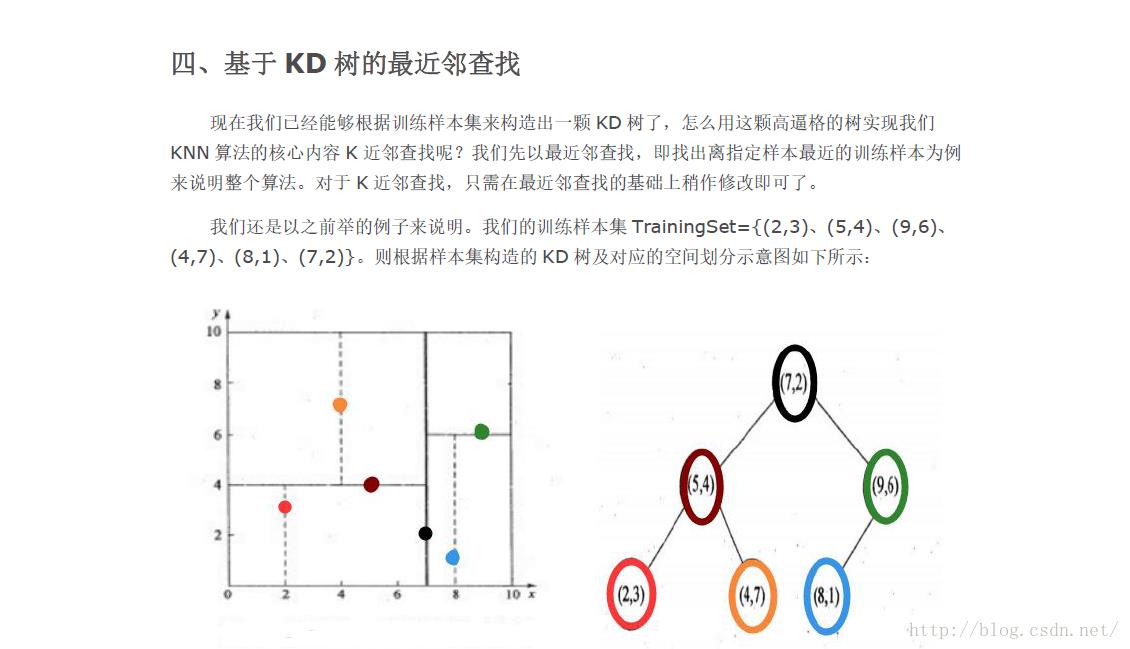








KD树节点
/// <summary>
/// KD树节点
/// /2016/4/1安晟添加
/// </summary>
[Serializable]
public class KDTreeNode
{
/// <summary>
/// 获取或设置节点的空间坐标
/// </summary>
public double[] Position { get; set; }
/// <summary>
/// 获取或设置分裂维度的索引
/// Gets or sets the dimension index of the split.
/// </summary>
public int Axis { get; set; }
/// <summary>
/// 获取或设置该节点在分裂维度上的取值
/// </summary>
public double Value { get; set; }
/// <summary>
/// 获取或设置该节点对应样本在原数据集中的索引
/// 这个属性在查询k近邻元素时十分重要
/// </summary>
public int OriginalIndex { get; set; }
/// <summary>
/// 获取或设置该节点的左孩子节点
/// </summary>
public KDTreeNode Left { get; set; }
/// <summary>
/// 获取或设置该节点的右孩子节点
/// </summary>
public KDTreeNode Right { get; set; }
/// <summary>
/// 获取该节点是否为叶子节点(木有孩子节点)
/// Gets whether this node is a leaf (has no children).
/// </summary>
public bool IsLeaf
{
get { return Left == null && Right == null; }
}
}
构造KD树
/// <summary>
/// 构造KDTree
/// </summary>
/// <param name="DateSet">输入样本集(构造树的过程中样本的顺序会被修改,不过不必担心,
/// 方法内部已经单独克隆一块内存区域来处理)</param>
public void BuildKDTree(double[][] DataSet)
{
KDTreeNode rootNode = new KDTreeNode();
//克隆数据集,DataSet将指向新开辟的数据集
//这样expand_kdTreeNode对样本顺序进行修改就不会影响到外部调用者
DataSet = (double[][])DataSet.Clone();
//Indexs数组用于记录每个样本对应的索引
//在expand_kdTreeNode方法内部,Indexs应随着DataSet中样本数据顺序的变化相应的变动。
int[] Indexs = new int[DataSet.Length];
for (int i = 0; i < DataSet.Length; i++)
Indexs[i] = i;
//从根节点开始递归构造KD树
expand_kdTreeNode(rootNode, DataSet, Indexs, 0, DataSet.Length);
this.Root = rootNode;
this.Dimensions = DataSet.Length;
}/// <summary>
/// 递归增加kd树节点
/// 按照方差选择分裂维度
/// 内部样本会被打乱顺序,如有需要使用前需单独复制一块内存区域
/// </summary>
/// <param name="currentNode"></param>
/// <param name="DataSet"></param>
/// <param name="startIndex"></param>
/// <param name="length"></param>
private void expand_kdTreeNode(KDTreeNode currentNode,double[][] DataSet,int[] Indexs,int startIndex,int length)
{
if(length==1)
{
//当前只有一个样本点,无需再进行分裂
//当前节点为叶子节点
currentNode.Position = DataSet[startIndex];
currentNode.OriginalIndex = Indexs[startIndex];
currentNode.Left = null;
currentNode.Right = null;
//因为是叶子节点并不需要分裂,所以 分裂维度Axis属性 和 该维度对应值Value属性 随便赋一个值就好了
currentNode.Axis = 0;
currentNode.Value = currentNode.Position[0];
}
else
{
//else对应通常情况,即需要对当前的数据集DataSet[startIndex:startIndex+length-1]
//的各个特征维度进行方差分析,找出分裂维度和分裂值,生成当前节点
#region 对数据集的关心区域,按照找到的分裂维度进行排序
//计算各个维度的方差,找到分裂维度
int split = CalculateFeaturesVariance(DataSet, startIndex, length);
//根据split维特征的取值,对数据集进行排序
double[] splitValueArray = new double[length]; //记录split维的特征值数组
int[] IndexArray = new int[length]; //记录对应相对索引(从0开始)
for(int i=startIndex;i<startIndex+ length;i++)
{
splitValueArray[i - startIndex] = DataSet[i][split];
IndexArray[i - startIndex] = i-startIndex;
}
//根据splitValueArray记录的split维的特征值数组,同时对splitValueArray和IndexArray进行排序
//IndexArray排序后记录的是 startIndex:startIndex+length-1 排序时的交换顺序
Array.Sort(splitValueArray, IndexArray);
//根据结果对DataSet的关心区域startIndex:startIndex+length-1重新排序
//首先需要克隆关心区域到内存中
double[][] tempData = new double[length][];
int[] tempIndex = new int[length];
for(int i=startIndex;i<startIndex+length;i++)
{
tempData[i - startIndex] = DataSet[i];
tempIndex[i - startIndex] = Indexs[i];
}
int RelativeDataIndex = -1; //对于每一个位置,它应当插入的元素所对应的排序前的索引
for (int i = startIndex; i < startIndex + length; i++)
{
RelativeDataIndex = IndexArray[i - startIndex];
DataSet[i] = tempData[RelativeDataIndex];
Indexs[i] = tempIndex[RelativeDataIndex];
}
//将临时数组清空,本函数由于是个递归函数,
//为了避免内存中可能会存众多的tempData,所以用完就清空掉,应该是合理的
tempData = null;
tempIndex = null;
#endregion
//到这里数据集的关心区域已经按照split维进行排序了
#region 构造当前节点
int middleIndex = startIndex + length / 2;
int leftStart = startIndex;
int leftlength = middleIndex - leftStart ;
int rightStart = middleIndex + 1;
int rightlength = startIndex + length - 1 - middleIndex;
currentNode.Axis = split;
currentNode.Position = DataSet[middleIndex];
currentNode.Value = currentNode.Position[split];
currentNode.OriginalIndex = Indexs[middleIndex];
currentNode.Left = new KDTreeNode();
currentNode.Right = new KDTreeNode();
#endregion
#region 递归
//递归左孩子节点
if (leftlength > 0) //因为选取中点时采取的逻辑,这个if语句是不起作用的(leftlength永远都不会等于0),仅仅是为了便于理解代码
expand_kdTreeNode(currentNode.Left, DataSet, Indexs, leftStart, leftlength);
else
currentNode.Left = null;
//递归右孩子节点
if (rightlength > 0)
expand_kdTreeNode(currentNode.Right, DataSet, Indexs, rightStart, rightlength);
else
currentNode.Right = null;
#endregion
}
}
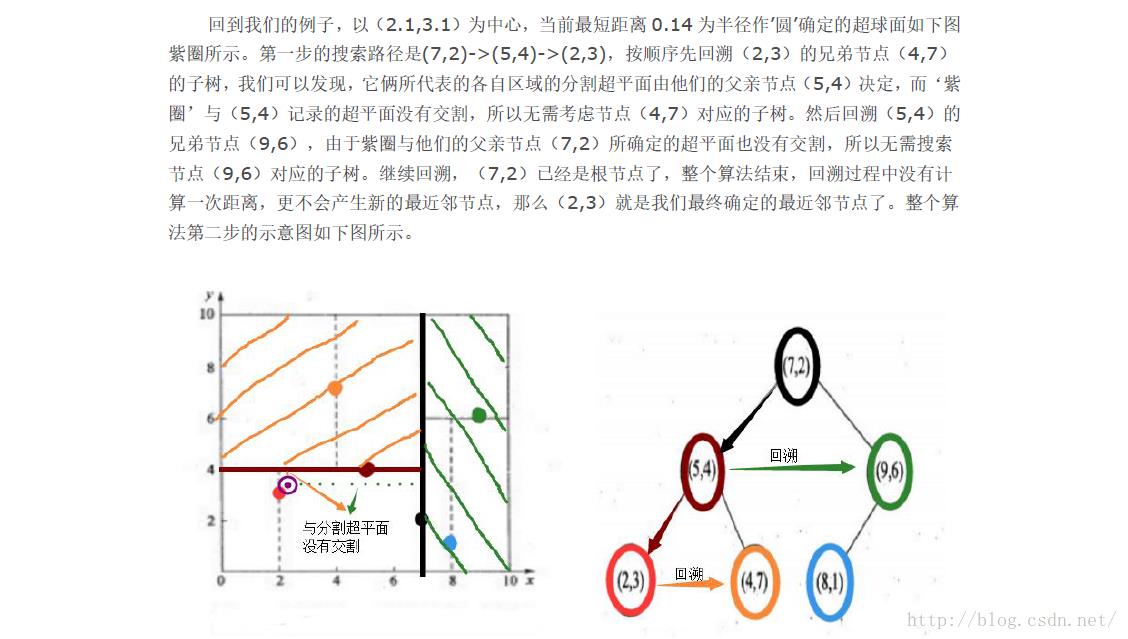
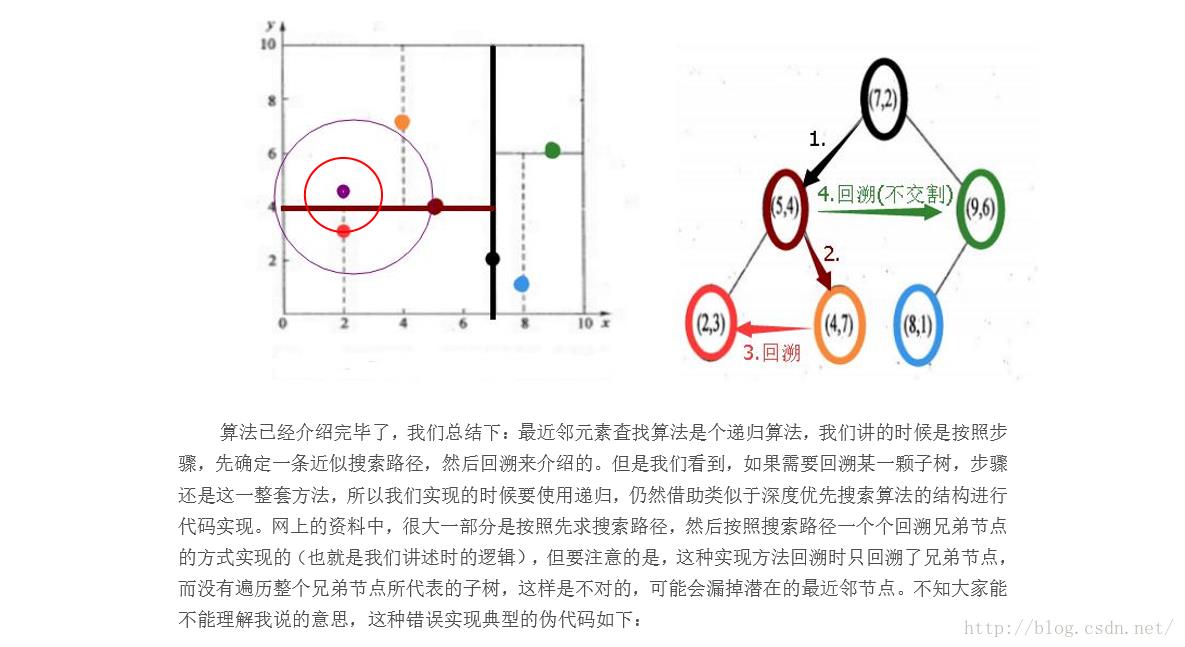
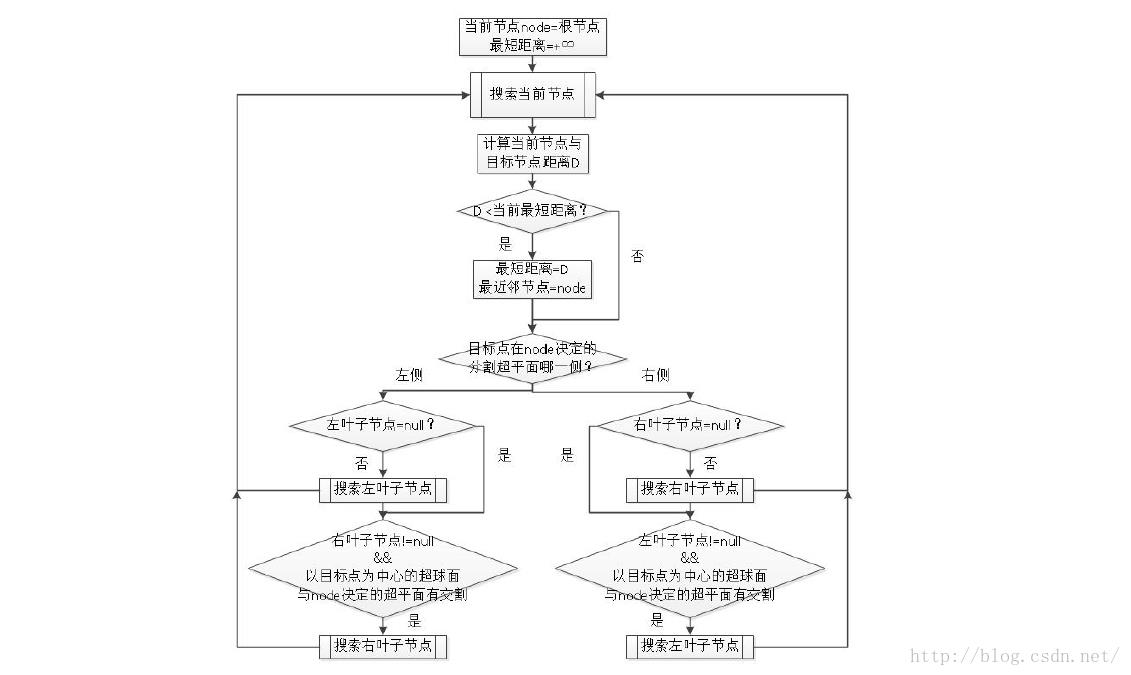
查找K近邻节点
以上是关于K 近邻算法(KNN)与KD 树实现的主要内容,如果未能解决你的问题,请参考以下文章