spark on yarn
Posted 乡村骑士2
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark on yarn相关的知识,希望对你有一定的参考价值。
公司中一般采用spark on yarn 模式,下面主要介绍spark on yarn的安装与简单程序运行。
1、spark on yarn两种运行模式
yarn-cluster:用于生产环境。Driver和AM运行在一起,client单独。
yarn-client:能立即看到输出结果。Driver运行在本地。AM仅用来管理资源。
client提交的job都会在worker上分配一个唯一的APPmaster。
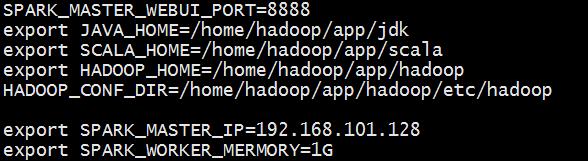
2、配置spark-env.sh文件,让spark找到yarn在哪里
HADOOP_CONF_DIR=/home/hadoop/app/hadoop/etc/hadoop
3、配置slaves文件,指定在哪些节点运行worker

4、spark-env.sh—spark的环境变量
5、试运行集群
bin/spark-shell --master yarn-client
启动成功:

6、作业提交(运行pi)
bin/spark-submit \\
--class org.apache.spark.examples.JavaSparkPi \\
--master yarn-client \\
--num-executors 1 \\
--driver-memory 1g \\
--executor-memory 1g \\
--executor-cores 1 \\
lib/spark-examples-1.6.1-hadoop2.6.0.jar

错误解决:

解决方式:
- 同步时间
- 在hadoop配置文件中yarn-site.xml配置
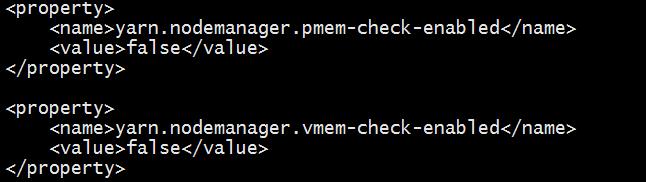
以上是关于spark on yarn的主要内容,如果未能解决你的问题,请参考以下文章
黑猴子的家:Spark on hive 与 hive on spark 的区别